Clear Sky Science · pt
Uma estrutura híbrida de CNN e aprendizado por reforço para identificação de locutor usando Mel-Espectrograma e características de transformada wavelet contínua
Por que sua voz pode ser uma chave digital
Imagine desbloquear sua conta bancária, a porta de casa ou o celular usando apenas a voz. Para que isso seja seguro, os computadores precisam distinguir uma pessoa da outra com confiabilidade, mesmo na presença de ruído de fundo, emoção ou um microfone ruim. Este artigo explora uma nova maneira de ensinar máquinas a reconhecer quem está falando, e não apenas o que está sendo dito, combinando técnicas modernas de aprendizado profundo com uma forma de aprendizado por tentativa e erro inspirada em robótica.
Das ondas sonoras às impressões digitais da voz
A voz de cada pessoa carrega pistas sutis moldadas pelo tamanho e formato do trato vocal, pelo modo como as pregas vocais vibram e pelo estilo de fala. Os pesquisadores começaram perguntando: quais propriedades mensuráveis da fala gravada realmente diferem entre indivíduos? Usando 2.703 clipes de áudio de 40 falantes em inglês do conjunto LibriSpeech, eles analisaram 22 características acústicas simples, como variação de intensidade, energia em diferentes faixas de frequência, ritmo e uma medida chamada entropia que captura quão complexo ou imprevisível é o som. Testes estatísticos mostraram que 21 dessas 22 características carregavam forte informação específica do locutor, com entropia e energia em altas frequências se destacando como especialmente distintivas. Em outras palavras, a “impressão digital” da voz de uma pessoa se espalha por muitos aspectos do som, não apenas pelo tom ou volume.
DuAS maneiras de transformar som em imagens
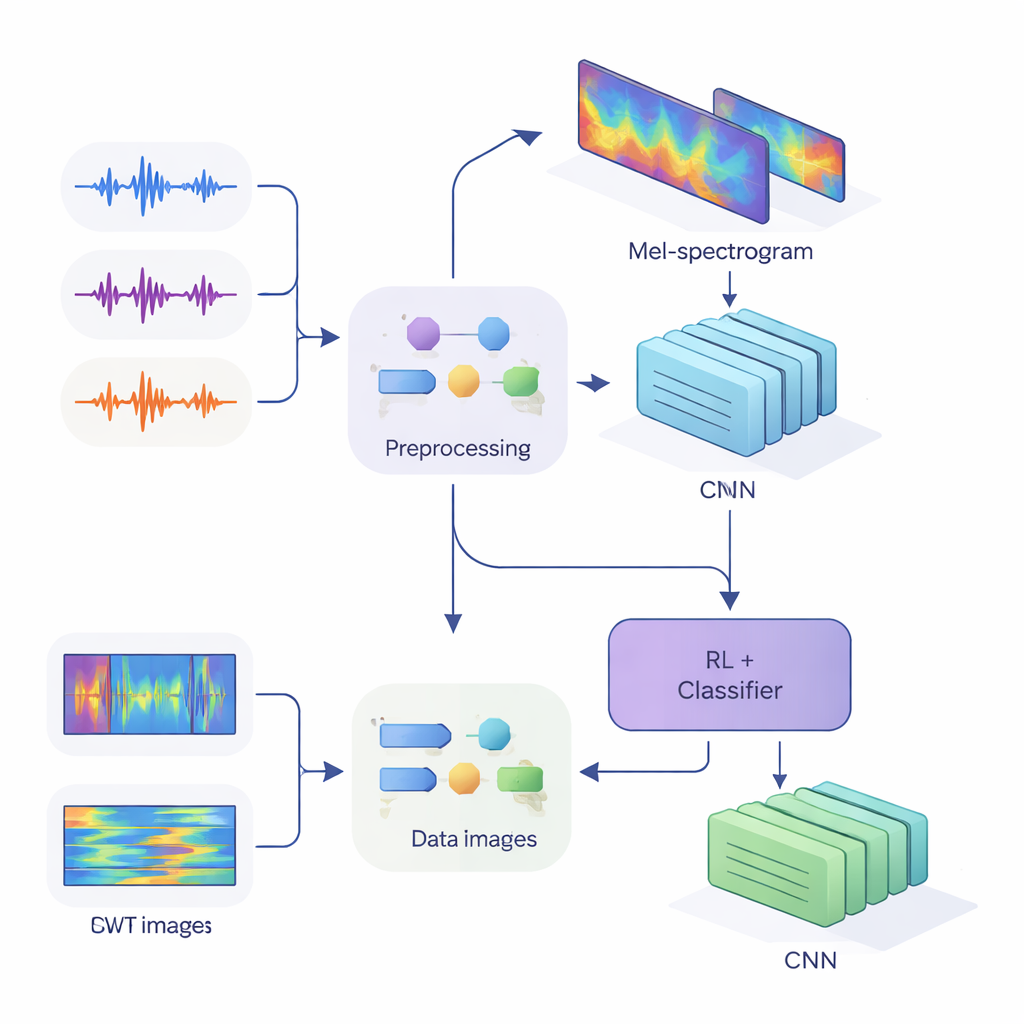
Para alimentar essas pistas em redes neurais modernas, a equipe converteu o áudio unidimensional em imagens bidimensionais que capturam como a energia muda ao longo do tempo e da frequência. No primeiro método, eles usaram Mel-espectrogramas, que imitam como o ouvido humano agrupa frequências e são padrão em tecnologia de fala. No segundo, usaram transformadas wavelet contínuas, uma forma mais flexível de dar zoom tanto em sons curtos e agudos quanto em vogais mais longas. Após limpar cuidadosamente o áudio—removendo silêncios, padronizando o volume e adicionando pequenas distorções como ruído e alterações de pitch para tornar o sistema mais robusto—eles produziram “imagens” Mel de tamanho 80 por 313 e “imagens” wavelet de tamanho 128 por 128, prontas para serem processadas por redes neurais convolucionais (CNNs).
Ensinando redes a ouvir e duvidar
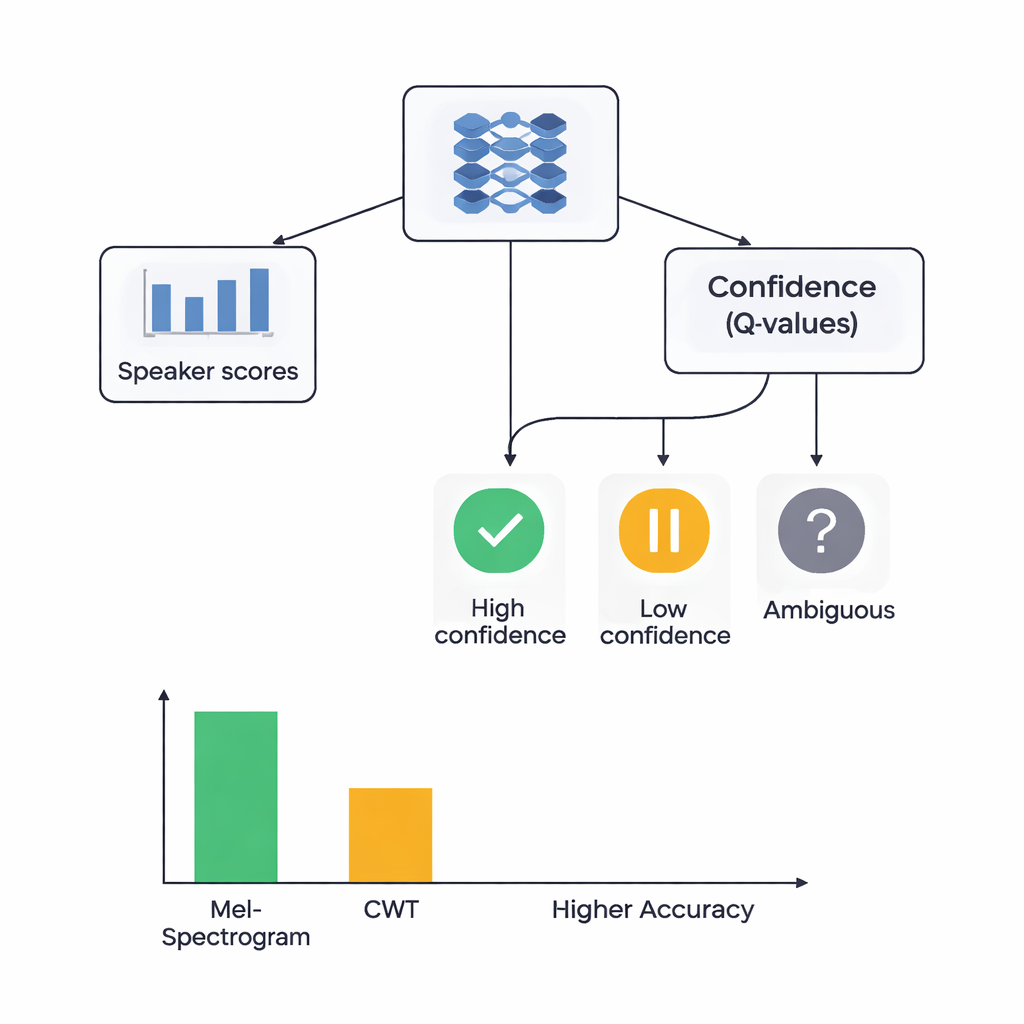
No centro do estudo está uma arquitetura híbrida que une dois estilos de aprendizado. Primeiro, as CNNs examinam as imagens Mel ou wavelet para extrair padrões que tendem a pertencer a locutores específicos, de modo semelhante a como redes de reconhecimento de imagem aprendem a identificar olhos ou contornos. Para o sistema baseado em Mel, os autores adicionam um módulo de self-attention que permite à rede focar nos segmentos temporais mais informativos. Sobre esses extratores de características, eles colocam um componente de aprendizado por reforço (RL) que aprende quão confiante o sistema deve estar em cada decisão. Em vez de sempre fazer uma escolha rígida, a parte RL atribui valores a ações como “aceitar isto como uma suposição de alta confiança”, “tratar isto como baixa confiança” ou “marcar como ambíguo”. Ao longo de muitas rodadas de treinamento, ela é recompensada quando decisões confiantes estão corretas, orientando a rede para julgamentos melhor calibrados.
Quão bem o sistema híbrido funciona?
Os pesquisadores compararam quatro modelos: baseado em Mel com RL, baseado em Mel sem RL, baseado em wavelet com RL e baseado em wavelet sem RL. Todos foram testados usando uma validação cruzada cuidadosa em cinco partições, o que significa que cada clipe de áudio serviu tanto para treinamento quanto para teste em rodadas diferentes. O sistema Mel com RL teve o melhor desempenho, identificando corretamente o locutor em cerca de 88% das vezes e mostrando separação quase perfeita entre locutores segundo uma medida padrão de poder discriminativo. O sistema wavelet com RL alcançou cerca de 78% de acurácia. Crucialmente, adicionar o componente RL melhorou o desempenho para ambos os tipos de característica em aproximadamente 3 pontos percentuais e tornou os resultados mais consistentes entre diferentes divisões dos dados. Mais classes de locutores alcançaram reconhecimento de alta qualidade quando o RL foi incluído, sugerindo que as decisões conscientes da confiança ajudaram especialmente com vozes difíceis e facilmente confundíveis.
O que isso significa para a segurança vocal do dia a dia
Para não especialistas, a conclusão principal é que checagens de identidade baseadas na voz mais confiáveis exigem tanto representações ricas do som quanto um saudável senso de dúvida por parte da máquina. Este trabalho mostra que Mel-espectrogramas inspirados no ouvido, combinados com atenção e um aprendiz por reforço capaz de dizer “não tenho certeza”, superam imagens wavelet mais exóticas na tarefa de distinguir locutores. Embora o estudo use um conjunto de dados relativamente pequeno e limpo e ainda não esteja afinado para condições ruidosas do mundo real, ele demonstra que adicionar uma camada sensível à confiança sobre redes neurais profundas pode tornar a autenticação por voz mais precisa e mais confiável—um passo importante se quisermos que nossas vozes se tornem chaves digitais seguras.
Citação: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Palavras-chave: identificação de locutor, biometria de voz, aprendizado profundo, aprendizado por reforço, Mel-espectrogramas