Clear Sky Science · pt
Um quadro geral para redução dimensional não paramétrica adaptativa
Por que reduzir grandes volumes de dados importa
A vida moderna funciona com dados: exames médicos, históricos de compras online, fotos, feeds de notícias e muito mais. Cada registro pode conter centenas ou milhares de medidas, o que torna difícil armazenar, analisar ou mesmo visualizar. Cientistas usam a “redução dimensional” para comprimir essa complexidade em imagens e modelos mais simples, mantendo os padrões importantes. Mas as ferramentas populares de hoje frequentemente exigem muitas escolhas manuais e ajustes por tentativa e erro. Este artigo apresenta uma forma de deixar que os próprios dados decidam a melhor maneira de encolher, visando imagens mais claras, aprendizado mais preciso e menos adivinhação pelo usuário.
De linhas simples a realidades curvadas
Uma ferramenta clássica para simplificar dados, a Análise de Componentes Principais (PCA), funciona como iluminar um objeto e observar sua sombra: ela encontra as melhores direções planas que explicam a maior parte da variação. Isso é poderoso quando a estrutura dos dados é aproximadamente reta ou plana. Mas dados reais — como imagens, textos ou leituras de sensores — frequentemente estão sobre superfícies curvas escondidas em um espaço de alta dimensão. Nas últimas duas décadas, novos métodos “não lineares” como Isomap, Locally Linear Embedding (LLE), embeddings espectrais e UMAP foram desenvolvidos especificamente para revelar essas formas sinuosas. Eles se apoiam em vizinhanças locais: para cada ponto, olham seus vizinhos mais próximos e tentam preservar essas relações em pequena escala ao desenhar uma representação de dimensão mais baixa. Contudo, esses métodos obrigam o usuário a escolher duas configurações-chave: quantos vizinhos usar e para quantas dimensões projetar. Escolhas ruins podem tornar o resultado enganoso ou computacionalmente caro.
Deixar os dados escolherem sua própria vizinhança
Os autores se baseiam em uma ferramenta estatística recente chamada estimador de dimensão intrínseca, que tenta responder a uma pergunta simples: em quantas direções independentes os dados realmente variam, uma vez que o ruído é removido? O estimador deles, chamado ABIDE, vai além. Em torno de cada ponto, ele busca automaticamente uma vizinhança que pareça razoavelmente uniforme — nem pequena e ruidosa, nem grande e distorcida. Ao fazer isso, retorna duas informações: uma estimativa global da dimensão verdadeira dos dados e um tamanho de vizinhança ajustado para cada ponto. Isso transforma o usual “número fixo de vizinhos” em uma quantidade adaptativa localmente, que pode crescer em regiões esparsas e encolher em áreas densas, acompanhando a densidade real dos dados.
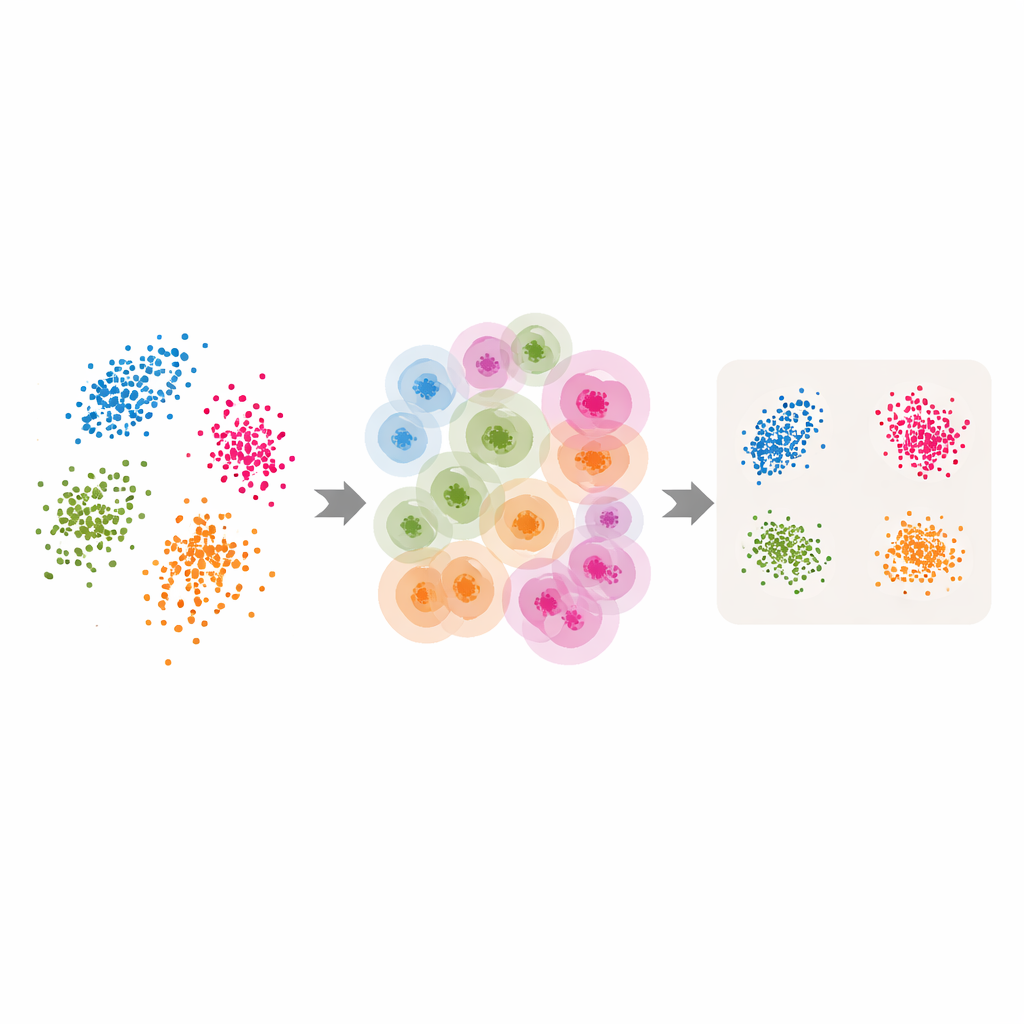
Transformando ferramentas clássicas em adaptativas
Munidos dessas vizinhanças adaptativas e da dimensão intrínseca estimada, os autores adaptam diversos métodos populares de redução dimensional e de agrupamento. Para o LLE, eles substituem o único número de vizinhos escolhido pelo usuário pelos valores por ponto retornados pelo ABIDE, e definem a dimensão alvo igual à dimensão intrínseca estimada. O algoritmo então aprende a reconstruir cada ponto a partir de um grupo local cuidadosamente escolhido antes de encontrar um arranjo global de baixa dimensão que preserve melhor essas reconstruções locais. Ideias semelhantes são aplicadas ao agrupamento espectral — onde um grafo de similaridades entre pontos é usado para formar grupos — e ao UMAP, que constrói um mapa difuso de como os pontos se conectam. Em cada caso, o tamanho rígido da vizinhança é trocado por uma estrutura flexível, orientada pelos dados, que segue a geometria natural dos dados.
Testes com flores, dígitos, texto e formas sintéticas
Para verificar se essa abordagem adaptativa compensa, os autores executam experimentos em vários benchmarks: as clássicas medidas da íris, imagens de dígitos manuscritos (MNIST), artigos de notícias representados por embeddings de modelos de linguagem e formas sintéticas tridimensionais com ruído adicionado. Eles comparam as versões adaptativas com configurações padrão de software e com grades cuidadosamente ajustadas de hiperparâmetros. Em tarefas não supervisionadas, como agrupamento e visualização, os métodos adaptativos tipicamente produzem clusters mais claros, agrupamentos mais coesos e melhores pontuações em medidas de qualidade padrão. Por exemplo, em variedades complexas com densidade de pontos desigual, os métodos adaptativos recuperam a estrutura verdadeira muito melhor do que versões com vizinhos fixos. Em testes supervisionados, onde os dados reduzidos são alimentados em um classificador, a abordagem adaptativa novamente iguala ou supera as melhores escolhas de parâmetros fixos, sem a necessidade de ajuste exaustivo.
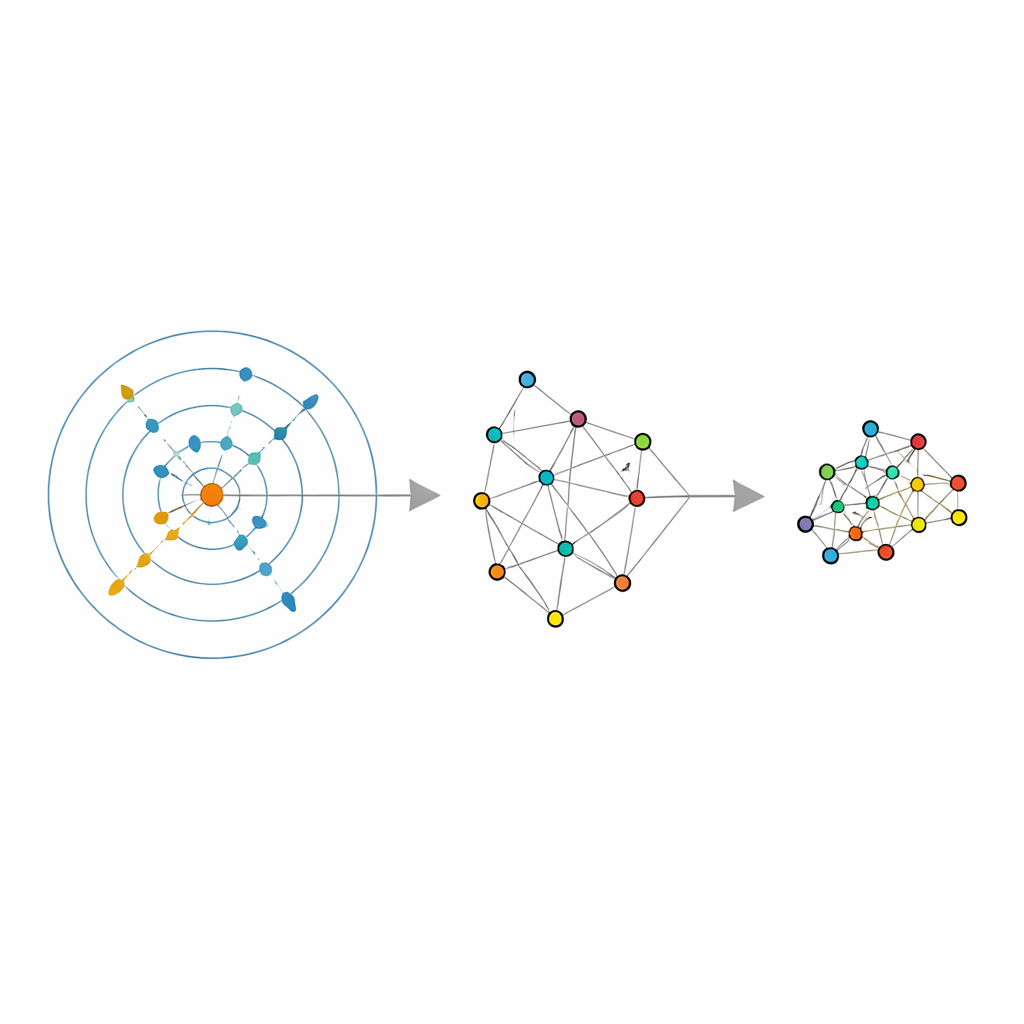
O que isso significa para a análise de dados do dia a dia
Para não especialistas e praticantes, a mensagem principal é que reduzir dados não precisa depender de tentativa e erro. Ao usar a própria geometria dos dados para decidir “quantos vizinhos” e “quantas dimensões”, este quadro transforma ferramentas amplamente usadas como LLE, agrupamento espectral e UMAP em versões mais inteligentes e robustas de si mesmas. O resultado são visões de baixa dimensão mais confiáveis — gráficos e características que refletem melhor a forma verdadeira dos dados — ao mesmo tempo que muitas vezes reduz o tempo gasto em buscas manuais por hiperparâmetros. Em termos práticos, isso significa que tarefas como visualizar grandes coleções de imagens, agrupar documentos ou preparar entradas para modelos preditivos podem se tornar mais fáceis e mais confiáveis, simplesmente deixando que os dados guiem de forma adaptativa como são comprimidos.
Citação: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
Palavras-chave: redução dimensional, aprendizado de variedade, vizinhos mais próximos, dimensão intrínseca, visualização de dados