Clear Sky Science · pt
Estrutura CNN-MLP para previsão de áreas queimadas em florestas usando o algoritmo PSO-WOA
Por que prever os danos do fogo importa
Os incêndios florestais estão se tornando mais quentes, maiores e mais frequentes à medida que o clima aquece e as pessoas avançam sobre áreas arborizadas. Para as equipes de combate ao fogo e as comunidades locais, uma das questões mais urgentes durante um surto não é apenas se um fogo vai começar, mas quanta terra ele provavelmente queimará. Este estudo demonstra como um novo tipo de inteligência artificial pode transformar medições simples de tempo e seca em estimativas altamente precisas da área final queimada, potencialmente dando aos gestores de emergência uma vantagem valiosa quando cada hora conta.
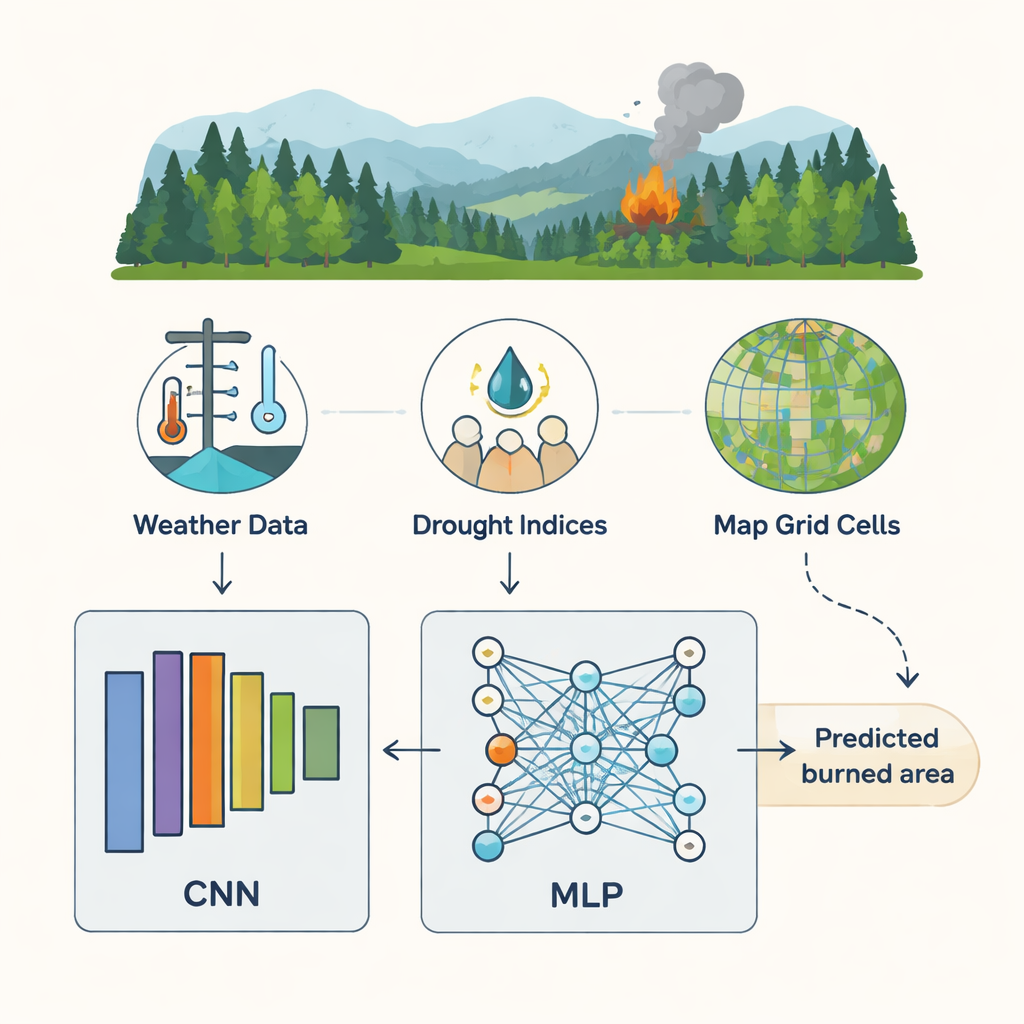
Dos dados brutos do tempo ao impacto do fogo
Os pesquisadores focam em um conjunto de dados bem conhecido de um parque nacional português que registra 517 incêndios florestais. Para cada incêndio, eles sabem onde e quando ocorreu, a temperatura do ar, a umidade, a velocidade do vento, chuvas recentes e vários códigos meteorológicos de incêndio que descrevem quão secos estão os diferentes níveis de combustível florestal. O desafio é que a maioria dos incêndios no registro é pequena, enquanto poucos são muito grandes, e a relação entre as leituras meteorológicas e a área queimada é altamente entrelaçada e não linear. Métodos anteriores, incluindo ferramentas padrão de aprendizado de máquina como máquinas de vetores de suporte e redes neurais simples, tiveram dificuldades com esse padrão complexo e produziram previsões apenas moderadamente precisas.
Deixando os algoritmos decidirem quais entradas importam
Em vez de alimentar todas as variáveis disponíveis em um modelo, a equipe primeiro usa um algoritmo inspirado em vagalumes para buscar a combinação mais informativa de entradas. Nesse esquema, cada "vagalume" propõe uma escolha sim-ou-não para cada característica: incluir temperatura, excluir chuva, incluir um dos códigos de seca etc. Vagalumes mais brilhantes representam combinações que geram previsões mais precisas usando um modelo de teste, mantendo o número de entradas pequeno. Ao longo de muitas rodadas, vagalumes mais fracos movem-se em direção aos mais brilhantes, e o processo se estabiliza em um conjunto enxuto de fatores-chave. Esse procedimento destaca de forma consistente cinco motores principais da área queimada: temperatura, umidade relativa, duas medidas de seca que capturam secas de médio e longo prazo e uma coordenada simples indicando onde no parque o incêndio ocorreu.
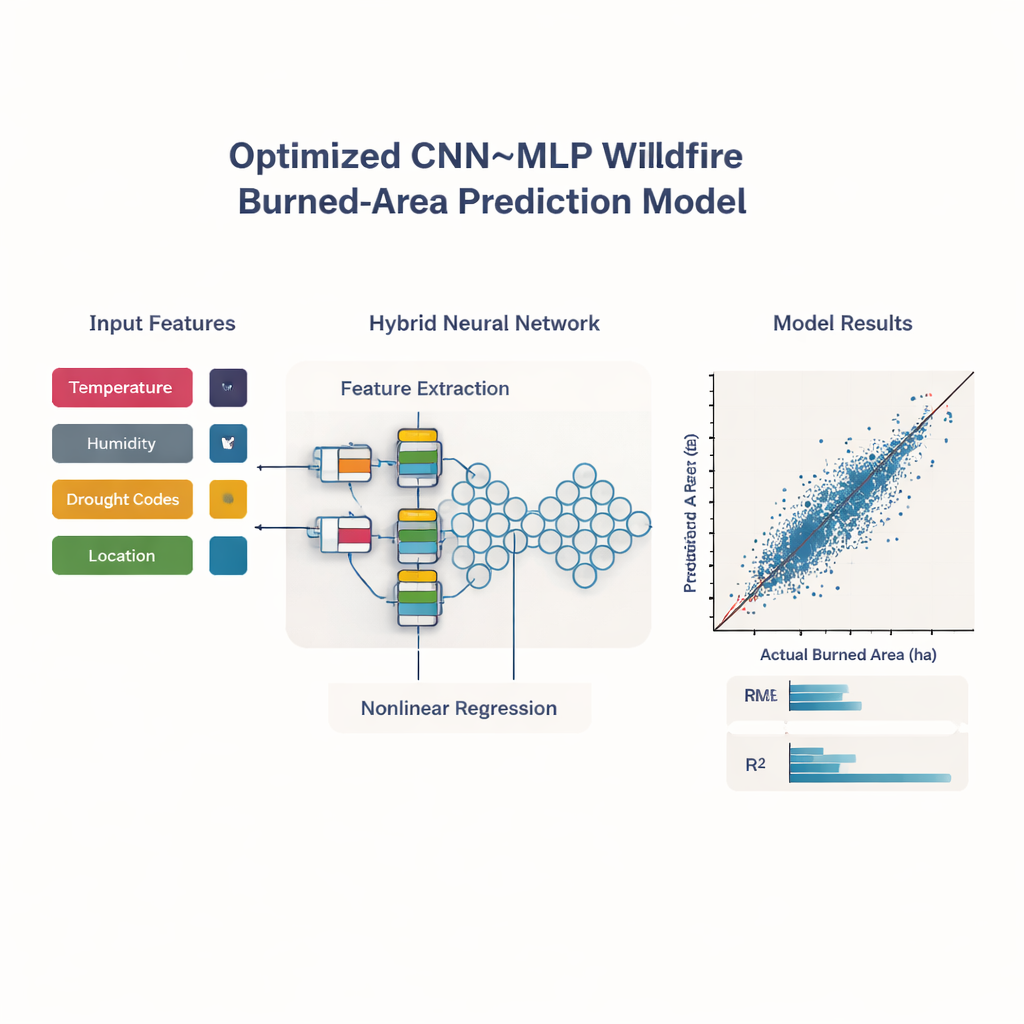
Uma rede neural híbrida ajustada por busca inspirada na natureza
Com essas entradas essenciais em mãos, os autores constroem uma rede neural leve, porém especializada. Uma parte, chamada rede convolucional unidimensional, procura padrões em como as características selecionadas interagem — por exemplo, a combinação de alta temperatura, baixa umidade e seca profunda em certas localidades. Sua saída então flui para um perceptron multicamadas mais tradicional que realiza a etapa final de regressão para estimar a área queimada. Escolher todos os ajustes internos desse modelo híbrido — quantas camadas, quantos neurônios, quão rápido ele aprende — é em si um problema complicado. Para tratar isso, a equipe combina mais dois métodos de busca inspirados na natureza, um modelado em bandos de pássaros (otimização por enxame de partículas) e outro na estratégia de caça das baleias. Trabalhando em etapas, esses algoritmos exploram muitos designs possíveis de rede e gradualmente convergem para aqueles que minimizam o erro de previsão em dados de validação reservados.
Quase concordância perfeita com incêndios reais
Após esse ajuste automático, o modelo híbrido otimizado é testado contra vários concorrentes fortes de aprendizado profundo: redes convolucionais independentes, redes feed-forward clássicas e modelos orientados a sequência, como LSTMs e GRUs. Todos são treinados e comparados nas mesmas divisões de dados. O sistema híbrido CNN–MLP sai claramente na frente. Suas previsões correspondem às áreas queimadas observadas com um coeficiente de determinação de cerca de 99,9%, e seus erros médios — medidos em hectares — são extremamente pequenos. A validação cruzada, na qual os dados são repetidamente embaralhados e divididos em diferentes conjuntos de treino e teste, mostra que esse desempenho é estável e não fruto de uma partição favorável. Análises adicionais usando SHAP, uma ferramenta para explicar decisões de modelos, confirmam que temperaturas mais altas e secas mais profundas empurram as previsões para áreas queimadas maiores, enquanto maior umidade as retém, ecoando a ciência consolidada sobre incêndios.
O que isso significa para o manejo do fogo
Para não especialistas, a mensagem central é que uma combinação cuidadosamente elaborada de IA moderna e otimização pode transformar um punhado de leituras rotineiras de tempo e seca em estimativas muito confiáveis de quanto de floresta um incêndio provavelmente consumirá. Ao selecionar automaticamente as entradas mais reveladoras e ajustar finamente o funcionamento interno do modelo, a abordagem oferece tanto precisão quanto interpretabilidade. Embora o estudo se concentre em um parque de Portugal e em um conjunto de dados relativamente pequeno, a estrutura pode, em princípio, ser estendida para dados mais ricos e outras regiões. À medida que esses sistemas amadurecem e são ligados a fluxos meteorológicos em tempo real, eles poderiam ajudar agências a priorizar zonas de alto risco, planejar evacuações mais cedo e alocar recursos de combate a incêndios com mais eficiência, reduzindo, em última instância, o impacto humano e ecológico dos incêndios florestais.
Citação: Mousa, M.H., Algamdi, A.M., Fouad, Y. et al. CNN-MLP framework for forest burned areas prediction using PSO-WOA algorithm. Sci Rep 16, 4982 (2026). https://doi.org/10.1038/s41598-026-35836-4
Palavras-chave: previsão de incêndios florestais, área queimada, aprendizado profundo, índice meteorológico de incêndio, risco de incêndio florestal