Clear Sky Science · pt
Otimização aprimorada por distribuição normal generalizada com método de reparo por distribuição gaussiana e aprendizado reverso cauchy para seleção de características
Por que escolher os dados certos importa
A vida moderna roda sobre dados, desde exames médicos e registros bancários até feeds de redes sociais. Mas mais dados nem sempre é melhor. Quando computadores são solicitados a aprender a partir de milhares de medidas brutas de uma vez, eles podem ficar mais lentos, mais caros de executar e, surpreendentemente, menos precisos. Este artigo apresenta uma forma mais inteligente de peneirar todas essas medições e manter apenas as que realmente importam, usando um novo algoritmo chamado Otimizador Binário Adaptativo de Distribuição Normal Generalizada, ou BAGNDO.
O problema de pistas demais
Imagine diagnosticar uma doença com centenas de exames laboratoriais, imagens e respostas a questionários. Muitas dessas “características” podem ser ruidosas, redundantes ou simplesmente irrelevantes, e fornecer todas elas a um classificador pode confundir em vez de ajudar. A seleção de características tem por objetivo escolher um subconjunto menor e mais informativo de entradas, de modo que modelos de aprendizado de máquina se tornem mais rápidos, mais baratos e mais confiáveis. Filtros estatísticos simples podem remover características obviamente inúteis, mas não adaptam suas escolhas ao modelo específico usado e frequentemente deixam passar combinações sutis de variáveis. Métodos mais avançados do tipo “wrapper” avaliam conjuntos de características testando diretamente o desempenho de um classificador, mas isso cria um problema de busca enorme: o número de subconjuntos possíveis explode conforme aumenta o número de características.
Buscar com inteligência em vez de cegamente
Para lidar com essa explosão, os pesquisadores recorrem a algoritmos metaheurísticos — estratégias de busca inspiradas por processos naturais ou físicos que equilibram ampla exploração com refinamento focado. Um desses métodos, o Otimizador de Distribuição Normal Generalizada (GNDO), trata soluções candidatas como se fossem extraídas de uma curva em forma de sino flexível e gradualmente desloca essa curva em direção a respostas melhores. O GNDO funcionou bem em aplicações de engenharia e energia, mas tende a se acomodar cedo em soluções apenas razoáveis e tem dificuldade em equilibrar seu vagar global com o ajuste local quando aplicado à seleção de características. Os autores identificam isso como uma lacuna crítica: a matemática elegante do GNDO não se traduz automaticamente em desempenho forte para decisões de alta dimensão do tipo sim-ou-não sobre quais características manter.
Uma atualização em três partes para um motor clássico
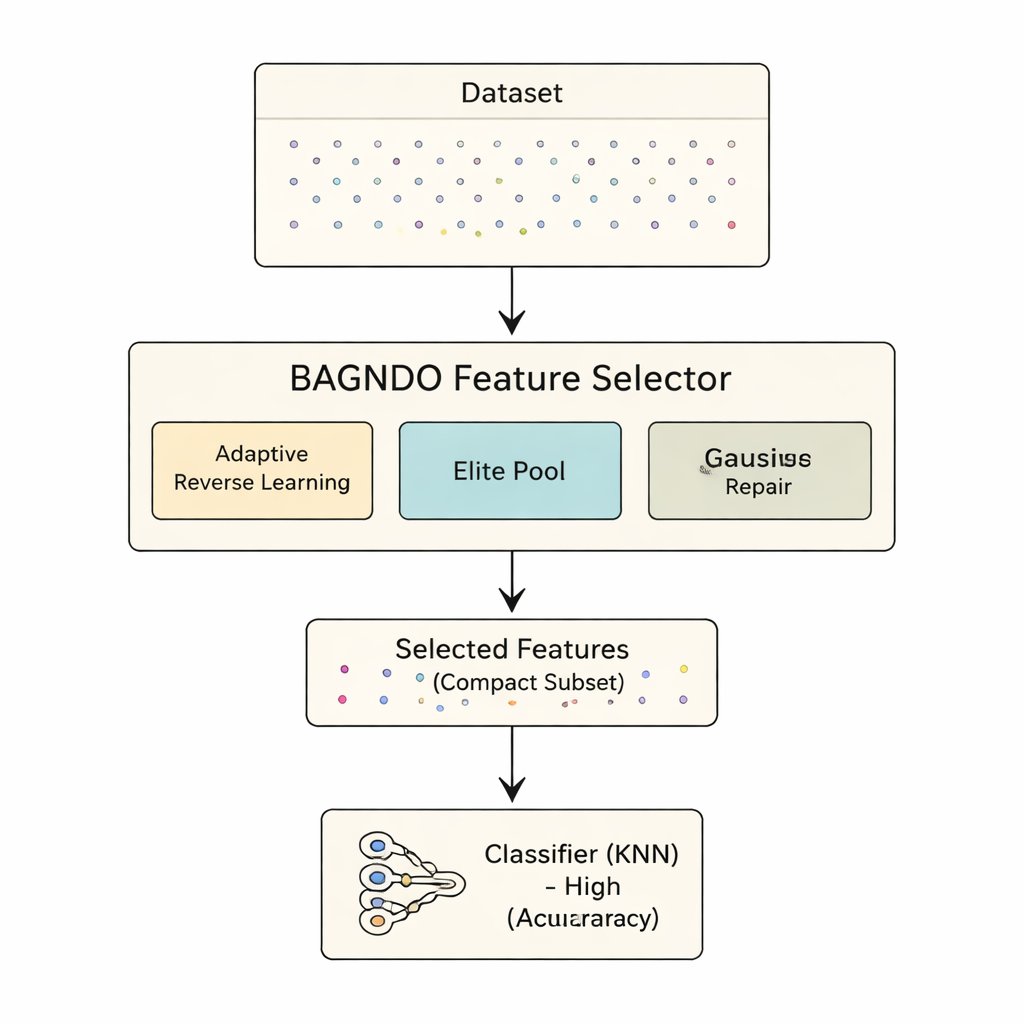
O framework proposto BAGNDO aprimora o GNDO com três ideias coordenadas. Primeiro, uma estratégia de Aprendizado Reverso Cauchy Adaptativo gera regularmente versões “espelhadas” das soluções atuais usando uma distribuição de probabilidade com caudas pesadas. Isso incentiva saltos audaciosos para regiões inexploradas do espaço de busca, prevenindo que o algoritmo fique preso em vales locais. Segundo, uma Estratégia de Pool de Elite mantém não apenas uma única melhor solução, mas um pequeno grupo de melhores desempenhantes mais um candidato “guia” combinado. Esse grupo de liderança mais rico ajuda a manter a diversidade ao mesmo tempo em que orienta a busca para regiões promissoras. Terceiro, um método de Reparo da Pior Solução baseado em Distribuição Gaussiana observa os candidatos mais fracos e os impulsiona em direção a padrões aprendidos a partir do grupo de elite, efetivamente reciclando soluções ruins em melhores em vez de descartá-las sumariamente.
Testando o método
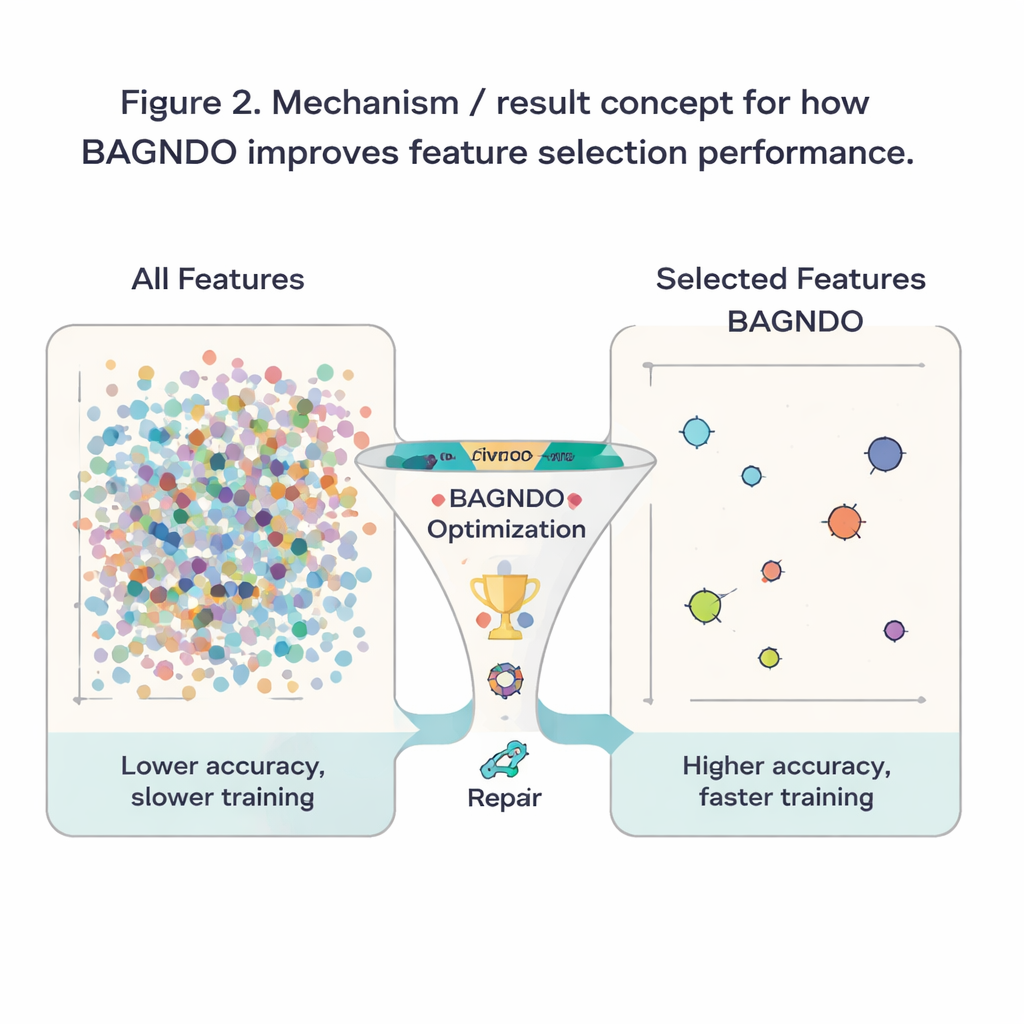
Para verificar se essas ideias ajudam na prática, os autores aplicaram o BAGNDO a 18 conjuntos de dados de referência bem conhecidos do repositório UCI, abrangendo diagnóstico médico, jogos, sinais e mais. Em cada caso, o algoritmo buscou um subconjunto de características que permitisse a um classificador padrão k-vizinhos mais próximos (k-NN) fazer previsões precisas. O BAGNDO foi confrontado com nove concorrentes fortes, incluindo otimização por enxame de partículas, métodos de estilo genético e vários algoritmos modernos inspirados em enxames. Nesses testes, o BAGNDO consistentemente encontrou conjuntos menores de características mantendo, e frequentemente melhorando, a precisão preditiva. Alcançou a melhor precisão com os subconjuntos de características mais compactos em 14 dos 18 conjuntos de dados, e testes estatísticos confirmaram que esses ganhos não se deviam ao acaso.
O que isso significa para o aprendizado de máquina do dia a dia
Para um público geral, o resultado pode ser resumido de forma simples: os autores construíram um “seletor de características” mais disciplinado que ajuda algoritmos de aprendizado a focarem no que realmente importa em um conjunto de dados. Ao equilibrar melhor exploração ampla, orientação de elite e reparo de candidatos fracos, o BAGNDO elimina entradas desnecessárias enquanto mantém ou aumenta a precisão. Isso se traduz em modelos mais rápidos, redução de custos de armazenamento e computação e, frequentemente, insights mais claros sobre quais medidas ou perguntas são mais informativas. Embora o método seja mais exigente computacionalmente do que algumas alternativas mais simples, oferece uma ferramenta poderosa para problemas onde precisão e interpretabilidade são essenciais, desde suporte a decisões médicas até monitoramento industrial e além.
Citação: Ghetas, M., Elaziz, M.A. & Issa, M. Enhanced generalized normal distribution optimizer with Gaussian distribution repair method and cauchy reverse learning for features selection. Sci Rep 16, 4794 (2026). https://doi.org/10.1038/s41598-026-35804-y
Palavras-chave: seleção de características, otimização metaheurística, aprendizado de máquina, redução de dimensionalidade, precisão de classificação