Clear Sky Science · pt
Fusão de imagens infravermelhas e visíveis por aprimoramento visual e acoplamento semântico
Visão mais nítida de câmeras diurnas e noturnas
Carros modernos, drones e sistemas de segurança costumam ter dois tipos de “olhos”: uma câmera convencional que capta cor e textura e uma câmera infravermelha que capta calor. Cada uma tem pontos fortes e limitações, e combiná-las em uma única imagem clara é surpreendentemente difícil. Este artigo apresenta uma nova forma de fundir essas duas visões em uma imagem que não apenas é mais agradável aos olhos, mas também mais fácil de ser compreendida por programas de computador.
Por que dois olhos são melhores que um
Câmeras de luz visível capturam detalhes nítidos, como marcações na pista, contornos de edifícios e roupas, mas têm dificuldade à noite, na neblina ou quando objetos se confundem com o fundo. Câmeras infravermelhas fazem o contrário: destacam objetos quentes, como pessoas e veículos, mesmo no escuro, mas suas imagens tendem a ser borradas e carecem de detalhes finos. Fundir essas duas visões em uma imagem “o melhor dos dois mundos” pode ajudar em tarefas que vão desde a detecção de pedestres em sistemas de auxílio ao motorista até vigilância e busca e salvamento. No entanto, muitos métodos de fusão existentes se concentram apenas em características superficiais — pontos brilhantes do infravermelho e texturas das imagens visíveis — enquanto negligenciam o significado mais profundo da cena, que é importante para máquinas inteligentes.
Uma maneira mais inteligente de mesclar imagens
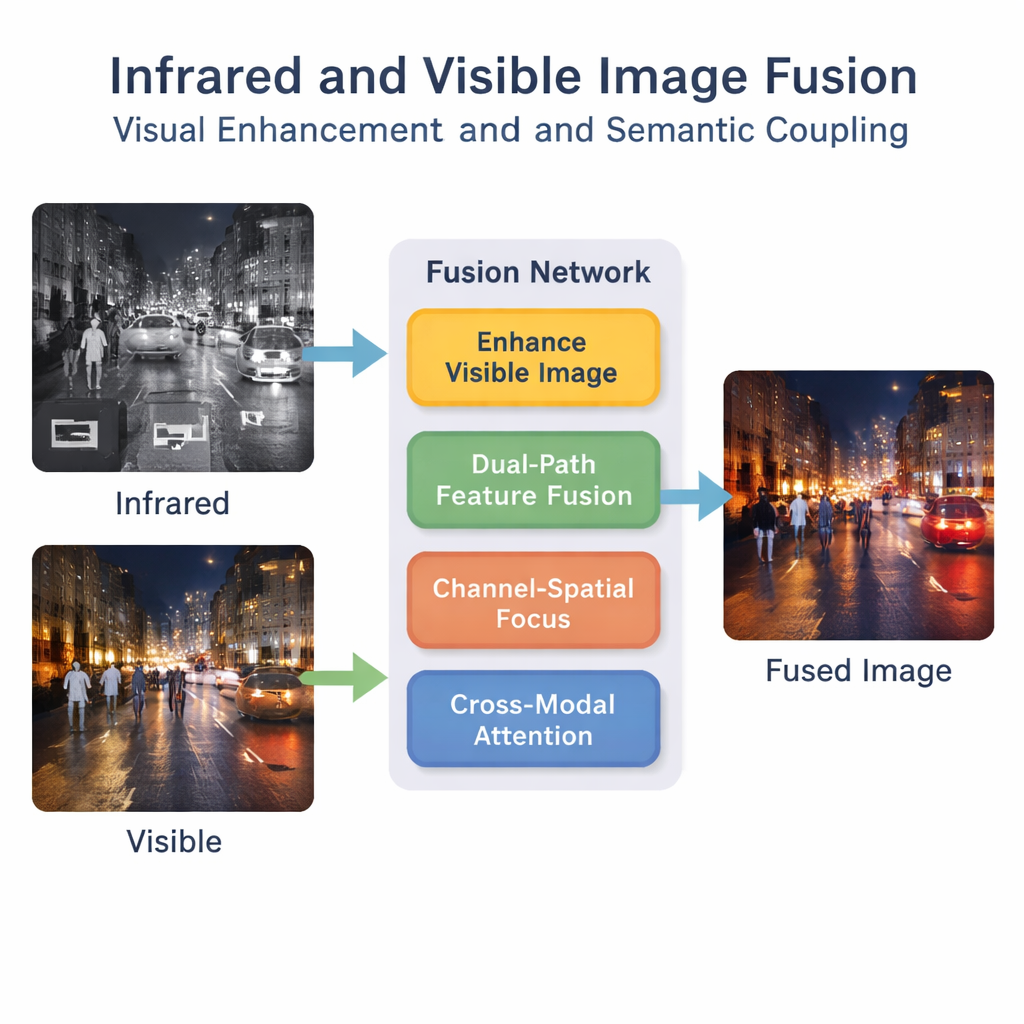
Os autores propõem uma estrutura de aprendizado profundo que trata a fusão como algo mais do que uma simples sobreposição. Primeiro, uma etapa especial de aprimoramento clareia e equilibra a imagem visível, especialmente em cenas de baixa luminosidade, de modo que detalhes valiosos não sejam perdidos antes mesmo da fusão começar. Em seguida, uma rede de caminho duplo processa as entradas infravermelhas e visíveis em paralelo. Um caminho concentra-se em padrões locais, como bordas e texturas, enquanto o outro observa o contexto mais amplo da cena. Ao combinar esses caminhos, o sistema produz uma descrição interna mais rica do que está acontecendo nas imagens.
Ensinando à rede o que observar
Extrair muitas características não é suficiente; a rede precisa aprender quais são importantes. Um módulo “canal–espacial” ajuda o modelo a destacar regiões e tipos de informação críticos, como pedestres ou faróis brilhantes, enquanto reduz a importância de ruído de fundo menos útil. Além disso, um mecanismo de atenção interativa bimodal incentiva os fluxos infravermelho e visível a se comunicarem. Ele aprende como assinaturas térmicas e texturas visuais se alinham pela cena, capturando conceitos de nível superior como “esta mancha brilhante no infravermelho corresponde àquela pessoa na imagem visível”. Esse acoplamento semântico ajuda a imagem fundida a permanecer logicamente consistente, e não apenas visualmente mesclada.

Colocando o método à prova
Para verificar se as imagens fundidas são não apenas atraentes, mas também realistas, os autores adicionam uma rede discriminadora semelhante às usadas em redes generativas adversariais. Essa rede extra aprende a distinguir imagens visíveis reais das fundidas, pressionando o processo de fusão a produzir saídas que pareçam naturais tanto para humanos quanto para máquinas. O método é treinado e testado em três conjuntos desafiadores de pares de imagens infravermelhas e visíveis, cobrindo estradas diurnas e noturnas e cenas de estilo militar. Em uma série de medidas de qualidade padrão, a nova abordagem geralmente supera dez técnicas de fusão existentes, produzindo imagens com bordas mais nítidas, melhor contraste e conteúdo mais informativo.
Imagens melhores para máquinas mais seguras
Além da qualidade visual, os autores fazem uma pergunta prática: essas imagens fundidas ajudam os computadores a tomar melhores decisões? Usando um sistema popular de detecção de objetos para localizar pedestres, eles mostram que suas imagens fundidas melhoram a precisão da detecção em comparação tanto com imagens de um único sensor quanto com métodos de fusão anteriores. Em termos práticos, a técnica cria imagens que são mais fáceis de interpretar por humanos e algoritmos, especialmente em condições difíceis como dirigir à noite. Embora o sistema ainda precise de ajustes para uso em tempo real em dispositivos com recursos limitados, ele oferece um passo promissor rumo a uma visão mais segura e confiável em veículos automatizados, vigilância e outras tecnologias que precisam enxergar claramente quando isso mais importa.
Citação: Yang, Y., Li, Y., Li, J. et al. Infrared and visible image fusion via visual enhancement and semantic coupling. Sci Rep 16, 5666 (2026). https://doi.org/10.1038/s41598-026-35763-4
Palavras-chave: fusão de imagens, imagens infravermelhas, visão em baixa luminosidade, aprendizado profundo, detecção de objetos