Clear Sky Science · pt
Rede de fusão de aprimoramento multifuncional para segmentação semântica de imagens de sensoriamento remoto
Mapas mais nítidos vistos do céu
Diariamente, satélites e drones capturam imagens detalhadas de nossas cidades e áreas agrícolas. Transformar essas imagens brutas em mapas claros, pixel a pixel, de ruas, telhados, árvores e plantações é essencial para tarefas como monitoramento da saúde das culturas ou planejamento de novos bairros. Este artigo apresenta uma nova abordagem para tornar esses mapas mais precisos, especialmente ao longo de limites desafiadores onde edifícios, campos e vegetação se confundem.
Por que imagens aéreas são difíceis de interpretar
Imagens de sensoriamento remoto diferem de fotos do cotidiano. São feitas de grandes altitudes, frequentemente em ângulos acentuados e sob iluminação variável. Objetos distintos podem parecer muito semelhantes visto de cima: um estacionamento de concreto e um telhado plano podem compartilhar quase a mesma cor; diferentes tipos de cultivo podem exibir padrões confundivelmente parecidos. Ao mesmo tempo, um mesmo tipo de objeto pode apresentar aparências bem diferentes dependendo das sombras, umidade ou configurações da câmera. Programas tradicionais, e até muitos sistemas modernos de aprendizado profundo, têm dificuldade em manter contornos nítidos nessas condições. Eles frequentemente borram as bordas entre categorias ou perdem pequenos detalhes como carros estacionados ou canais de irrigação estreitos.
Ver o panorama e as linhas finas
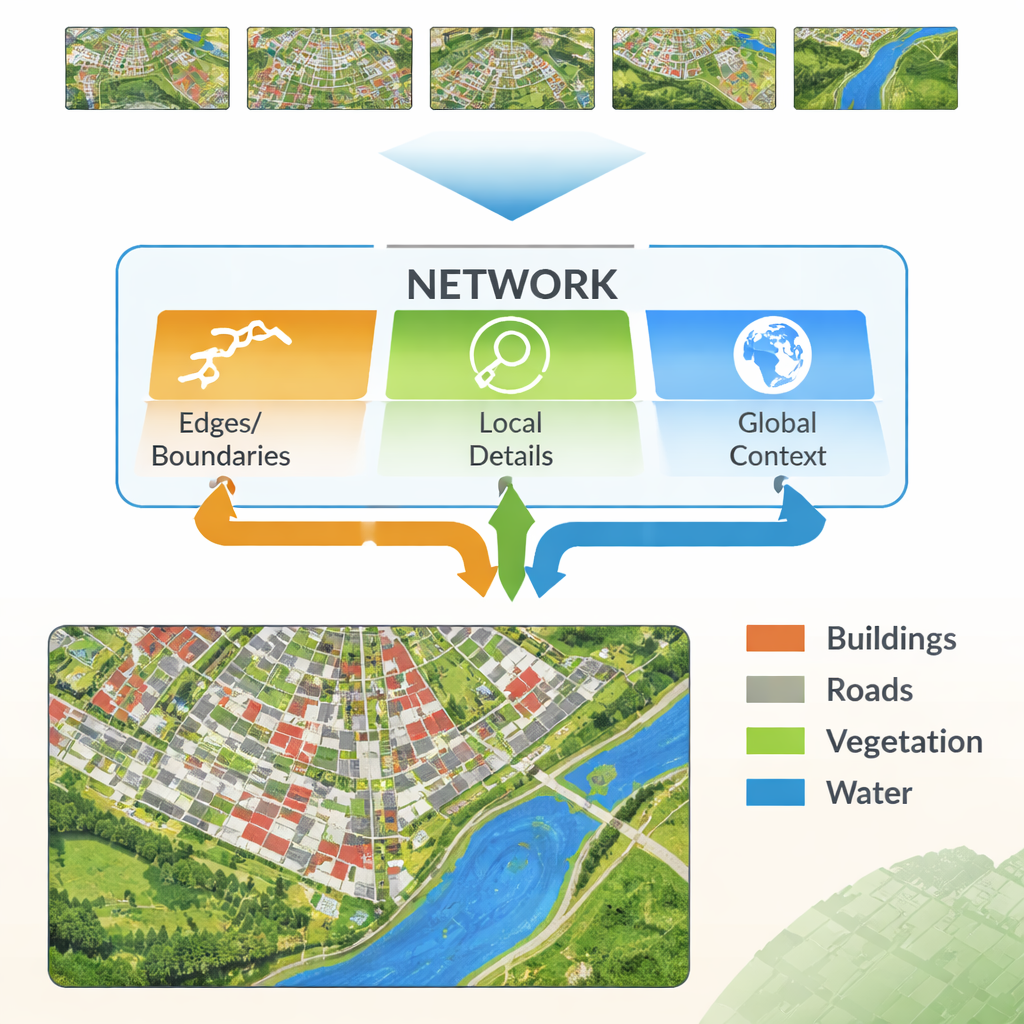
Redes neurais modernas aprendem ao passar uma imagem por muitas camadas. Camadas iniciais captam detalhes finos como linhas e texturas, enquanto camadas mais profundas aprendem padrões amplos, como “esta região provavelmente é edificada”. O desafio é que combinar esses dois tipos de informação não é trivial. Detalhes de baixo nível podem ser ruidosos e redundantes, e padrões de alto nível podem borrar as bordas, produzindo contornos difusos. Os autores propõem uma nova arquitetura, chamada Multi-Feature Enhancement Fusion Network (MFEF-UNet), projetada explicitamente para equilibrar detalhe local com compreensão global. Ela faz isso tratando bordas, padrões locais e contexto amplo como fontes separadas, porém cooperantes, de informação.
Destaque para bordas e fusão de características
Uma ideia central do novo método é aproveitar ferramentas clássicas e simples de detecção de bordas e integrá-las a um pipeline moderno de aprendizado profundo. Um Módulo de Aprimoramento de Bordas toma as primeiras características extraídas pela rede e as processa com operadores muito bons em encontrar limites—semelhante a como um software básico de edição de imagem pode detectar contornos. Esses mapas de borda aprimorados são produzidos em várias escalas, para que a rede veja tanto limites finos quanto mais grossos. Um Módulo de Fusão de Múltiplas Características então reúne três fluxos: a informação de alto nível em evolução (“o que é esta região?”), a reconstrução de detalhes pelo decodificador e os mapas de borda. Em vez de apenas empilhá-los, o módulo usa um mecanismo semelhante a atenção para que as características semânticas possam “consultar” os fluxos de borda e detalhe sobre onde estão realmente as fronteiras e pequenas estruturas, e ajustar a representação final em conformidade.
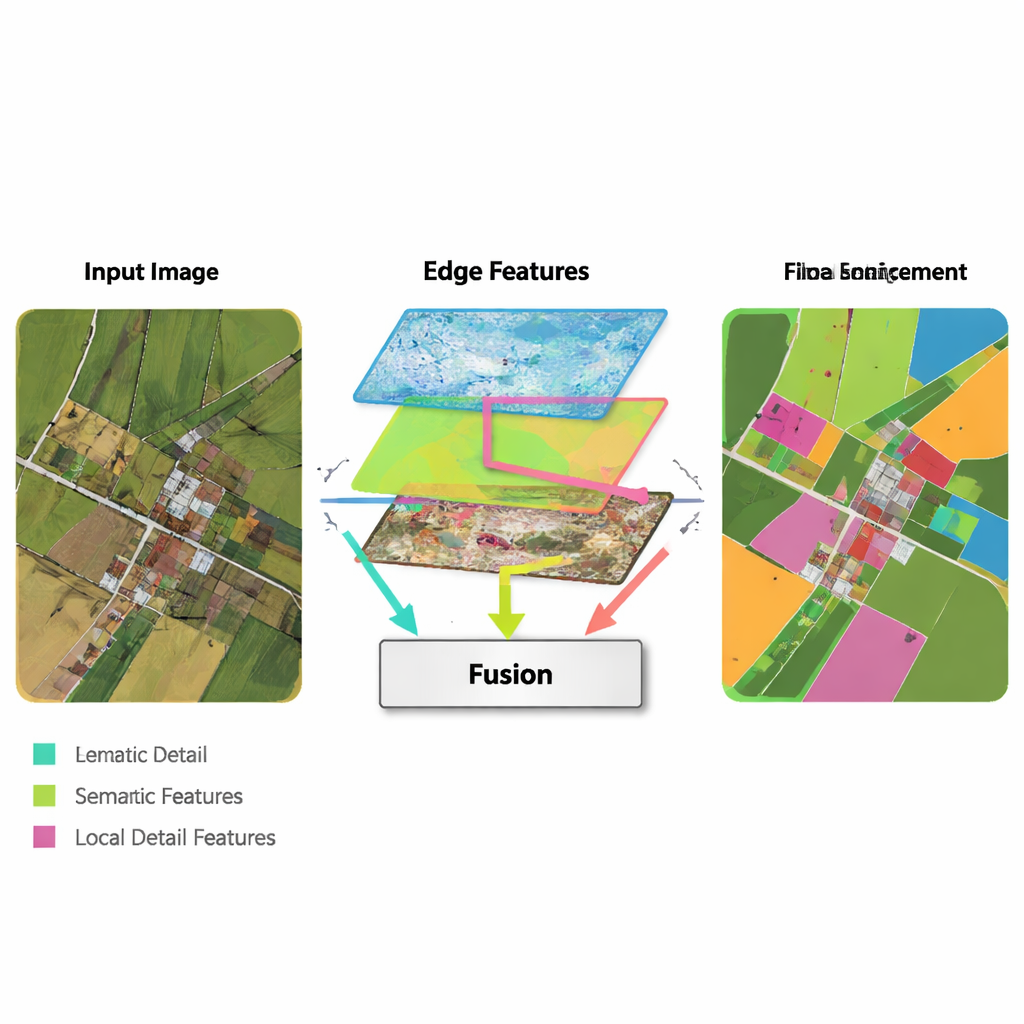
Equilibrando detalhe local com contexto global
Outro componente do MFEF-UNet é um Módulo de Aprimoramento de Características Local-Global. Para leigos, isso pode ser pensado como a parte da rede que garante que ela não perca a visão do bosque ao focar nas árvores—ou da cidade ao refinar cada edifício. A imagem é dividida em sub-janelas gerenciáveis para que pixels próximos possam ser modelados juntos, preservando formas e texturas. Após esse modelamento local, as janelas são costuradas de volta em uma imagem completa, e uma segunda passagem permite que a informação flua entre regiões distantes. Esse processo em duas etapas ajuda o modelo a respeitar tanto estruturas pequenas, como carros e limites estreitos de campos, quanto padrões em larga escala, como quarteirões de moradias ou corpos d’água contínuos.
Comprovando o método em cidades e áreas agrícolas
Os pesquisadores testaram sua abordagem em três conjuntos de dados públicos: dois que cobrem cidades e vilarejos europeus, e uma grande coleção de imagens agrícolas dos Estados Unidos. Esses conjuntos contêm uma mistura de telhados, vias, vegetação, água e padrões sutis de cultivo. Em todos os três benchmarks, o MFEF-UNet produziu consistentemente mapas mais precisos do que uma série de métodos de referência, incluindo redes convolucionais clássicas, arquiteturas baseadas em Transformers e modelos mais recentes de “estado de espaço”. Suas vantagens foram mais visíveis ao redor de contornos complexos de edifícios, aglomerados de pequenos objetos como veículos, e estruturas longas e estreitas como canais de drenagem ou linhas de plantio—locais onde outros métodos tendem a fragmentar ou borrar a segmentação.
O que isso significa na prática
Na prática, a rede proposta converte imagens aéreas em mapas de cobertura do solo mais limpos e confiáveis. Planejadores urbanos podem medir áreas edificadas com mais segurança, engenheiros podem traçar melhor ruas e telhados, e agrônomos podem delimitar com maior precisão campos, cursos d’água e zonas de estresse nas culturas. Embora os componentes adicionais de borda e fusão introduzam algum custo computacional extra, o projeto geral permanece razoavelmente eficiente ao mesmo tempo em que entrega ganhos claros em precisão e robustez. Para não especialistas, a conclusão é que, ao enfatizar deliberadamente as bordas e fundir cuidadosamente diferentes tipos de pistas visuais, os computadores agora conseguem interpretar imagens de satélite e drone com maior acuidade—aproximando-nos de mapas do mundo atualizados e de alta precisão.
Citação: Zhang, W., Yang, W., Yin, Y. et al. Multi-feature enhancement fusion network for remote sensing image semantic segmentation. Sci Rep 16, 5023 (2026). https://doi.org/10.1038/s41598-026-35723-y
Palavras-chave: sensoriamento remoto, segmentação semântica, imagens de satélite, aprendizado profundo, mapeamento de cobertura do solo