Clear Sky Science · pt
De dados a decisões: o uso de IA explicável para prever rendimento de soja nos principais países produtores
Por que previsões de safra mais inteligentes importam
Dos preços no supermercado ao comércio global, a modesta soja desempenha um papel surpreendentemente grande na vida cotidiana. Governos, comerciantes e agricultores precisam saber o tamanho da colheita meses antes das colheitadeiras entrarem nos campos. Hoje, ferramentas poderosas de inteligência artificial (IA) podem vasculhar montanhas de dados meteorológicos e de satélite para fazer essas previsões — mas muitos desses modelos funcionam como “caixas-pretas”, oferecendo pouca visão sobre por que dão determinada resposta. Este estudo explora um novo tipo de IA explicável que não apenas prevê rendimentos de soja nos principais países produtores do mundo, mas também mostra com clareza quais fatores impulsionam essas previsões.
Três países que alimentam o mundo
Os pesquisadores focaram nos três países que dominam o abastecimento global de soja: Estados Unidos, Brasil e Argentina, que juntos produzem mais de 80% da soja mundial. Eles analisaram em escala fina — condados nos EUA e regiões equivalentes de pequeno porte no Brasil e na Argentina — usando dados recentes de 2018 a 2022. Para cada região, montaram um retrato detalhado das condições de cultivo: registros climáticos pormenorizados, propriedades do solo e múltiplos tipos de dados de satélite que acompanham o crescimento das plantas, o estado hídrico e até um fraco brilho da fotossíntese conhecido como fluorescência da clorofila induzida pelo sol (SIF). No total, 154 diferentes características numéricas foram extraídas para descrever cada safra antes de serem alimentadas nos modelos.
De pipelines de dados a máquinas de aprendizado
Para lidar com essa inundação de informação, a equipe construiu um pipeline de processamento padronizado. Eles alinharam todos os conjuntos de dados no espaço e no tempo usando calendários de cultivo, suavizaram sinais de satélite ruidosos e resumiram a estação de crescimento com estatísticas como médias, extremos e variabilidade. Em seguida, treinaram três tipos de modelos para prever rendimentos: Random Forest (RF), um cavalo de batalha amplamente usado em aprendizado de máquina; Multilayer Perceptron (MLP), uma rede neural profunda clássica; e Kolmogorov–Arnold Networks (KAN), uma arquitetura mais recente projetada desde a base para ser mais interpretável. Para evitar avaliações excessivamente otimistas, os autores dividiram cuidadosamente os dados em blocos espaciais de modo que os modelos fossem testados em regiões que não haviam “visto” durante o treinamento.
Abrindo a caixa-preta da IA
O que distingue este trabalho não é apenas a precisão das previsões, mas como os modelos se explicam. RF e MLP foram sondados com ferramentas padrão que mostram o quanto cada característica de entrada contribui para suas previsões. KAN vai além: representa as ligações entre entradas e saídas como curvas suaves unidimensionais que podem ser plotadas e inspecionadas. Isso permite aos pesquisadores ver literalmente como, por exemplo, uma mudança na SIF ou na umidade do solo empurra o rendimento para cima ou para baixo. Entre países e métodos, um padrão ficou claro — a SIF, o sinal de satélite diretamente ligado à fotossíntese, classificou-se consistentemente entre os preditores mais importantes do rendimento de soja. Outros fatores-chave variaram por região: nos Estados Unidos, sinais de vegetação relacionados à água se destacaram, enquanto no Brasil e na Argentina a temperatura e a umidade do solo desempenharam papéis mais fortes.
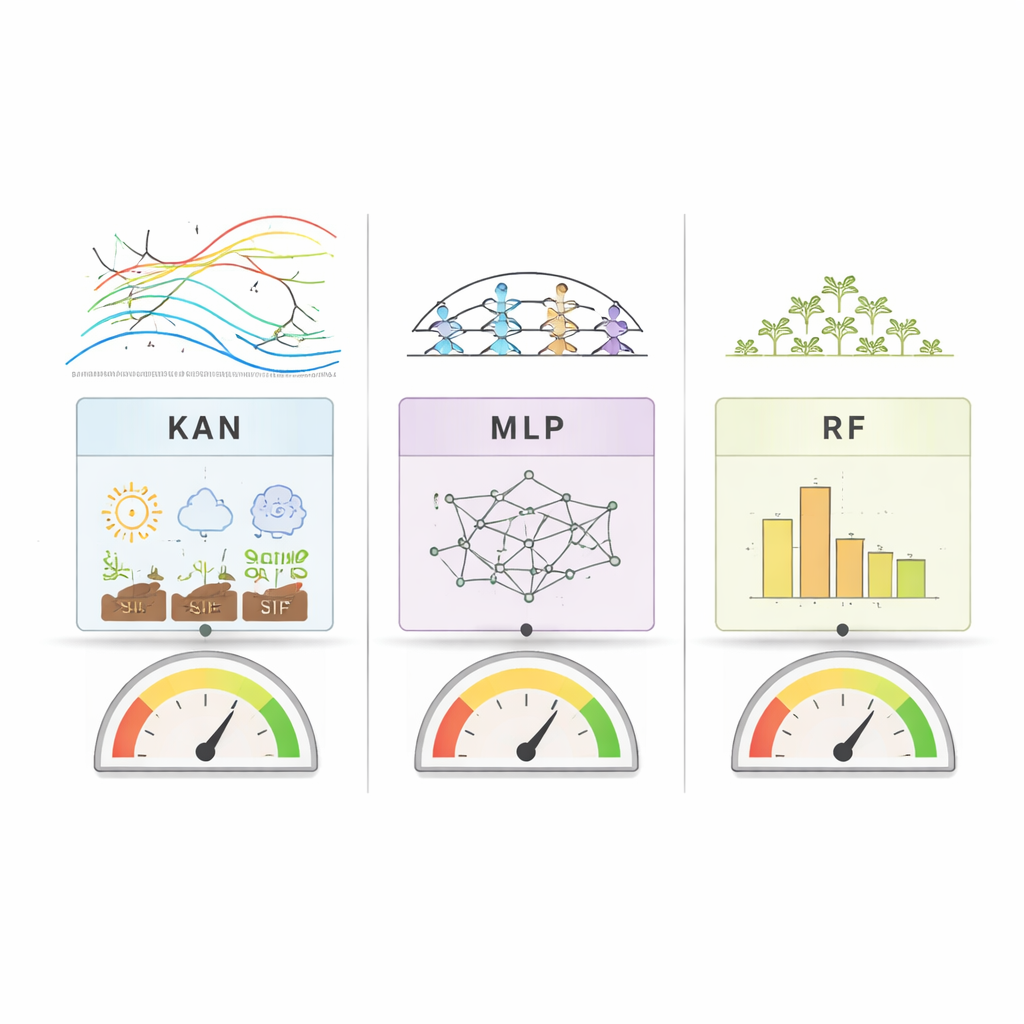
Quão bem os modelos se saíram?
Ao comparar a acurácia dos modelos, nenhum método venceu de forma absoluta em todas as situações. Nos Estados Unidos, onde os rendimentos foram relativamente estáveis ano a ano, o Random Forest teve desempenho ligeiramente melhor no geral, mas KAN e MLP ficaram logo atrás. No Brasil, com rendimentos mais voláteis e um conjunto de dados maior, os três modelos alcançaram alta precisão, embora tenham tido alguma dificuldade em prever rendimentos muito altos. Na Argentina, onde os dados eram mais limitados, KAN geralmente superou a linha de base de aprendizado profundo (MLP) e chegou perto do Random Forest. Esses resultados sugerem que KAN pode igualar modelos tradicionais em conjuntos de dados agrícolas pequenos e desafiadores, oferecendo ao mesmo tempo muito mais transparência sobre como chega às suas conclusões.
O que isso significa para agricultores e segurança alimentar
Para decisores do mundo real, confiar em um modelo pode ser tão importante quanto a precisão bruta. Este estudo mostra que abordagens de IA explicável como KAN podem fornecer previsões competitivas de rendimento da soja enquanto revelam claramente quais sinais ambientais e da cultura são mais relevantes. Essa visibilidade ajuda cientistas a diagnosticar erros, incorporar conhecimento agronômico de especialistas e adaptar modelos a novas regiões ou a climas em mudança. A longo prazo, tais ferramentas transparentes poderiam ser integradas a sistemas nacionais de monitoramento de culturas, dando a agricultores, planejadores e mercados alertas mais precoces e confiáveis sobre más colheitas ou safras recordes — e apoiando sistemas alimentares mais resilientes e sustentáveis.
Citação: Wang, X., He, Y., Chen, H. et al. From data to decisions: the use of explainable AI to forecast soybean yield in major producing countries. Sci Rep 16, 5103 (2026). https://doi.org/10.1038/s41598-026-35716-x
Palavras-chave: previsão de rendimento da soja, IA explicável, sensoriamento remoto, modelagem agrícola, segurança alimentar