Clear Sky Science · pt
Rastreador siamês de duplo ramo aumentado por transformer com regressão ciente da confiança e atualização adaptativa de modelo
Ensinando computadores a seguir um objeto em uma cena cheia
De carros autônomos a câmeras de segurança doméstica e drones, muitos dispositivos modernos precisam seguir um único objeto em movimento por um mundo movimentado e mutável. Essa tarefa, chamada rastreamento visual de objetos, parece simples para humanos, mas é surpreendentemente difícil para máquinas: pessoas passam na frente da câmera, a iluminação muda, o objeto encolhe à distância ou fica brevemente oculto. Este artigo apresenta o TSDTrack, um novo sistema de rastreamento que usa avanços recentes em aprendizado profundo e transformers para manter o foco no alvo com mais confiabilidade nessas condições do mundo real.
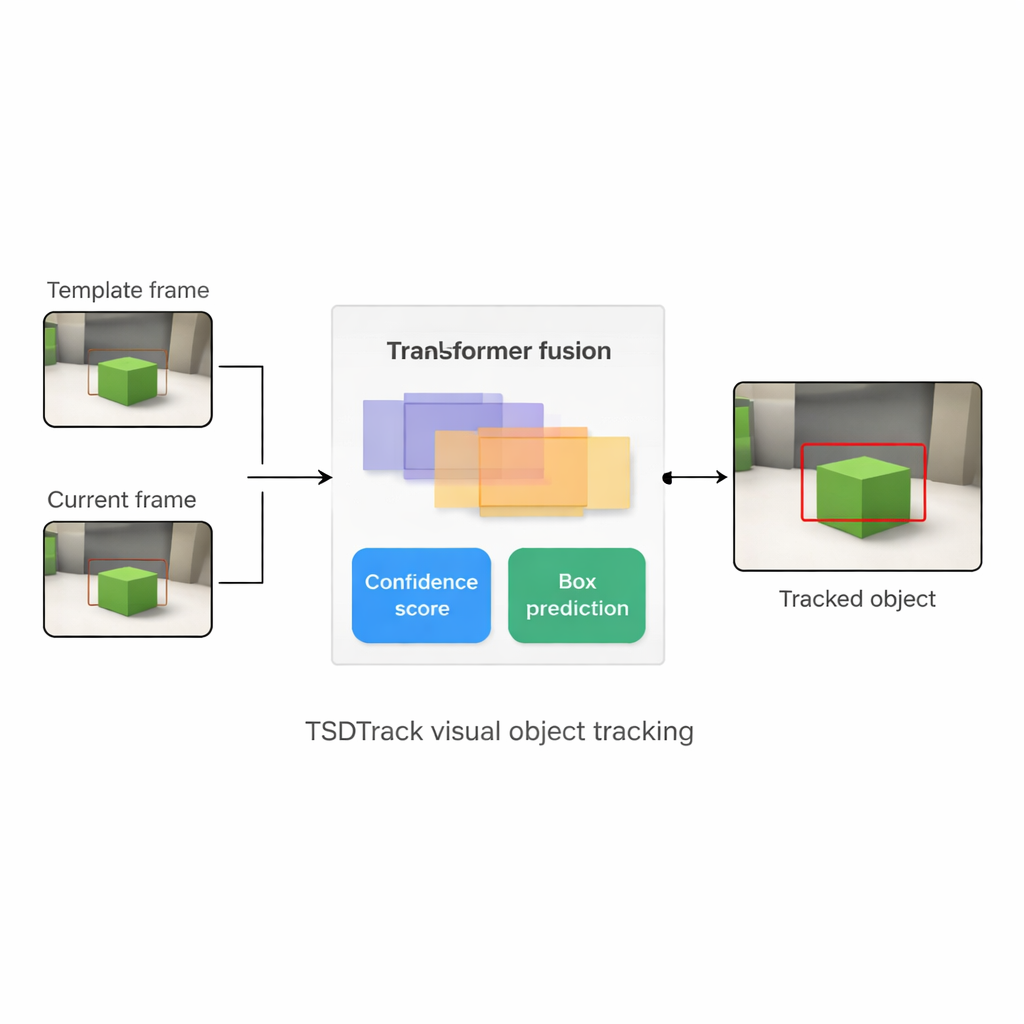
Por que seguir uma coisa é tão difícil
Um rastreador geralmente vê o objeto com clareza apenas no primeiro quadro de um vídeo e, em seguida, precisa continuar encontrando-o conforme a cena muda. Métodos tradicionais ou dependiam de características de imagem feitas à mão ou de uma rede neural que comparava o primeiro quadro (o "modelo") com cada novo quadro. Esses sistemas mais antigos tinham três grandes fraquezas. Primeiro, tipicamente mantinham o modelo original fixo, então se o objeto virasse, ficasse parcialmente coberto ou mudasse de tamanho, o rastreador tinha dificuldade. Segundo, muitas vezes se concentravam em um único nível de detalhe na imagem, perdendo a combinação de arestas finas e contexto mais amplo que ajuda humanos a reconhecer objetos. Terceiro, não sabiam quando desconfiar de si mesmos: produziam uma caixa ao redor do suposto objeto sem nenhum senso claro de quão confiável era essa estimativa, o que os tornava propensos a derivar para o fundo.
Misturando contexto global com detalhes finos
O TSDTrack resolve esses problemas combinando uma configuração clássica de rastreamento "Siamese" com um transformer, o mesmo tipo de modelo baseado em atenção que transformou tarefas de linguagem e visão. O sistema usa uma rede profunda para extrair características de duas entradas: um pequeno recorte que define o alvo e um recorte maior que contém a área de busca atual. Em vez de confiar em apenas uma escala de características, ele extrai informações de múltiplas camadas da rede, que representam arestas, formas e padrões em nível de objeto. Um módulo de fusão baseado em transformer então aprende a combinar essas camadas para que o rastreador entenda tanto onde as coisas estão na imagem quanto como elas se relacionam com a cena em geral. Isso ajuda a distinguir o alvo de objetos semelhantes e da desordem, mesmo quando a visão é ruidosa ou parcialmente bloqueada.
Saber o quão certo o rastreador realmente está
O coração do TSDTrack é uma cabeça de predição de duplo ramo que divide a tarefa em duas perguntas relacionadas: "Onde está o objeto?" e "Quanto devemos confiar nessa resposta?" Um ramo estima uma pontuação de confiança que reflete não apenas o quão semelhante o alvo parece, mas também o quão bem a caixa prevista se sobrepõe a regiões prováveis do objeto. O outro ramo trata as coordenadas da caixa não como uma única estimativa, mas como uma distribuição de probabilidade sobre muitas posições possíveis, permitindo ao modelo representar incerteza. Quando a imagem está clara, a distribuição se torna afiada e a caixa é precisa; quando o objeto está borrado ou parcialmente escondido, a distribuição se espalha. Essa visão probabilística leva a posicionamentos de caixa mais suaves e estáveis em comparação com rastreadores antigos que faziam uma única previsão rígida.
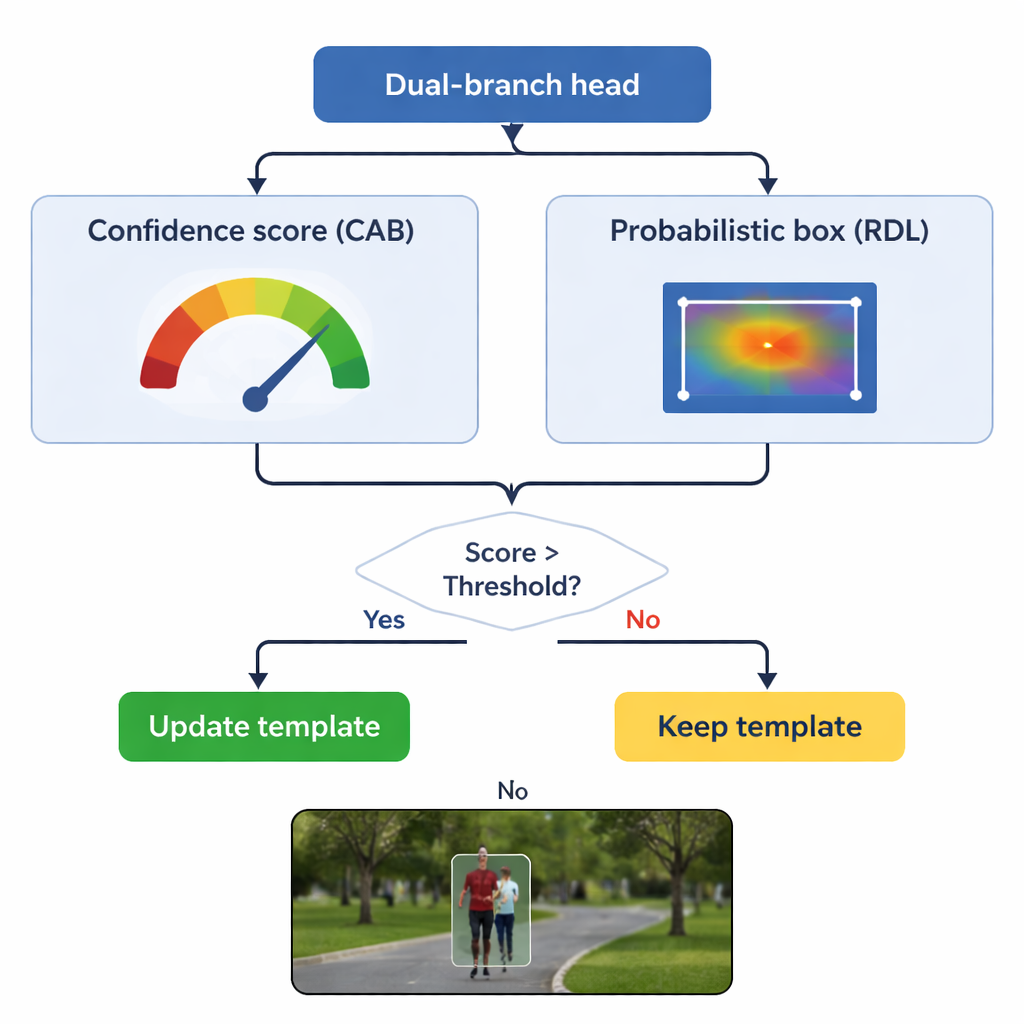
Atualizando a memória sem esquecer o original
Um perigo chave no rastreamento é a "deriva do modelo": se o modelo continuar atualizando sua ideia do objeto usando quadros ruins, ele pode lentamente aprender o fundo. O TSDTrack enfrenta isso deixando seu ramo de confiança agir como um guardião. O sistema atualiza seu modelo interno apenas quando a pontuação de confiança está acima de um limiar escolhido e, mesmo assim, mistura a nova informação suavemente com a visão original em vez de substituí-la por completo. Essa atualização seletiva permite que o rastreador se adapte a mudanças genuínas, como uma pessoa se virando ou um carro girando, sem ser enganado por oclusões momentâneas ou distrações. O modelo original também é mantido em reserva como uma referência estável caso atualizações posteriores se mostrem enganosas.
O que os resultados significam na prática
Os autores testaram o TSDTrack em vários benchmarks de rastreamento amplamente usados, incluindo vídeos longos, movimentos rápidos, imagens aéreas de drones e cenas com muita desordem. Em todos esses testes, o novo método superou consistentemente muitos rastreadores de ponta tanto em precisão (quão próxima a caixa está do objeto verdadeiro) quanto em robustez (com que raridade perde-se completamente o objeto), mantendo velocidade suficiente para uso em tempo real em hardware moderno. Para um não especialista, a conclusão é que o TSDTrack consegue manter o foco em um alvo escolhido com mais confiabilidade nas condições bagunçadas encontradas em câmeras do mundo real. Ao combinar raciocínio em múltiplas escalas com transformer, senso de confiança próprio e atualização cuidadosa do modelo, ele oferece um bloco de construção mais confiável para aplicações como direção autônoma, vigilância inteligente e robôs inteligentes.
Citação: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
Palavras-chave: rastreamento visual de objetos, rastreamento baseado em transformer, redes Siamese, visão computacional, sistemas autônomos