Clear Sky Science · pt
Uma abordagem baseada em satélite e aprendizado de máquina para estimar a temperatura média diária do ar em alta resolução em uma megacidade no Brasil
Por que o calor da cidade não é o mesmo em todos os lugares
Em um dia quente em uma grande cidade, a temperatura que você percebe em uma rua com árvores pode ser muito diferente da que alguém experimenta em uma praça de concreto a poucos quarteirões de distância. Ainda assim, a maioria dos estudos de saúde e clima continua a tratar uma cidade inteira como se tivesse uma única temperatura. Este artigo mostra como cientistas usaram satélites, modelos meteorológicos e aprendizado de máquina para mapear temperaturas diárias em São Paulo, Brasil, com grande detalhe—ajudando a revelar quem realmente está exposto a calor perigoso e onde os esforços de resfriamento são mais necessários.
Tirando a temperatura da cidade em alta definição
Os registros tradicionais de temperatura dependem de um número limitado de estações meteorológicas, muitas vezes concentradas perto de aeroportos ou em bairros mais ricos. Isso dificulta ver como o calor se distribui pelos bairros reais, especialmente em grandes cidades e em países de renda baixa e média, onde as redes de monitoramento são esparsas. Os pesquisadores focaram em São Paulo, uma megacidade vastíssima e altamente variada, com mais de 22 milhões de habitantes. O objetivo foi estimar a temperatura média diária do ar para cada quadrado de 500 por 500 metros em toda a área metropolitana ao longo de cinco anos, de 2015 a 2019, criando um dos conjuntos de dados de temperatura mais detalhados já disponíveis em uma cidade na América do Sul.
Combinação de satélites, modelos meteorológicos e sensores no solo
Para construir essa imagem em alta resolução, a equipe combinou vários tipos de dados de acesso livre. Reuniram medições de 48 estações terrestres, que fornecem as leituras de temperatura do ar mais diretas, mas apenas em pontos específicos. Em seguida incorporaram observações de satélite da temperatura de superfície do solo, o ângulo do sol e a refletância do terreno, junto com informações sobre umidade, vento e pressão de um produto global de “reanálise” meteorológica que reconstrói o tempo horário em uma grade grosseira. Esses ingredientes foram reamostrados para corresponder à grade de 500 metros e limpos para preencher lacunas causadas por nuvens ou passagens de satélite ausentes. No total, testaram 23 possíveis variáveis preditoras que poderiam ajudar a explicar como o calor varia no espaço e no tempo.
Treinando uma máquina de aprendizado para ler o calor
Em vez de usar uma equação simples de linha reta (linear), os cientistas recorreram a uma Random Forest, um método popular de aprendizado de máquina que constrói muitas árvores de decisão e faz a média de seus resultados. Essa abordagem é bem adequada para descobrir relações complexas e não lineares, como a forma pela qual a temperatura responde de maneira diferente ao calor de superfície, à umidade e ao vento em diferentes partes da cidade ou em diferentes épocas do ano. Para evitar o sobreajuste às particularidades de algumas estações, usaram um processo passo a passo de seleção de variáveis que mantém apenas aquelas que realmente melhoram as previsões, e validaram o modelo de duas maneiras: deixando repetidamente grupos de estações fora durante o treinamento e reservando cinco estações inteiras como um teste externo rigoroso de quão bem o modelo funciona em locais novos.
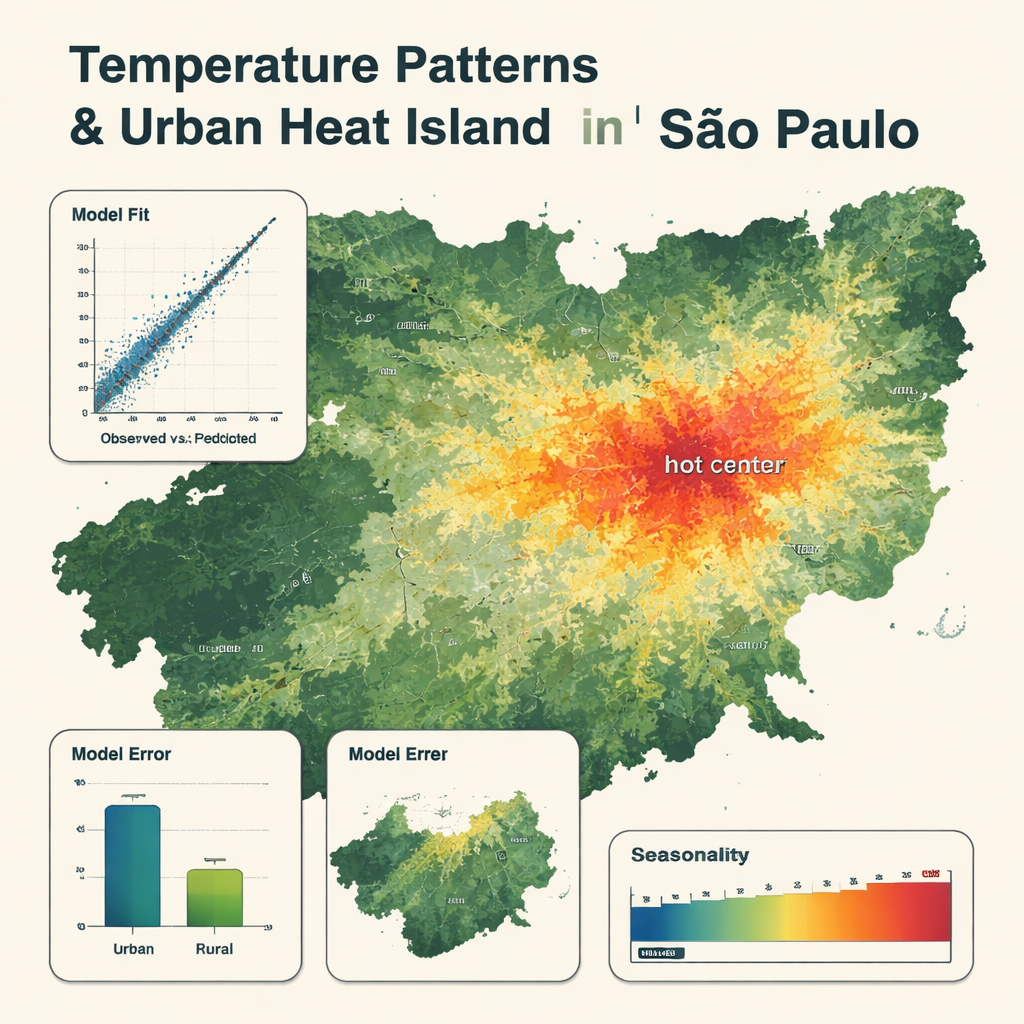
O que os mapas detalhados revelam
O modelo final usou apenas oito variáveis-chave, lideradas pela temperatura do ar fornecida pelo produto meteorológico global, com temperatura de superfície por satélite e umidade também desempenhando papéis importantes. Ele reproduziu as leituras das estações com muita precisão, com um erro médio de cerca de 0,8 °C e uma correspondência muito alta entre temperaturas observadas e previstas. Os mapas mostram padrões claros: zonas mais frias sobre florestas, morros e grandes reservatórios, e zonas mais quentes no centro urbano denso e edificado, onde as temperaturas podem ser até 5 °C mais altas do que em áreas rurais próximas. O modelo capturou oscilações sazonais, com as maiores temperaturas de dezembro a março e as mais baixas de maio a agosto. Foi um pouco menos preciso em áreas rurais e tendia a suavizar os dias mais extremos de calor e frio, mas ainda superou um modelo tradicional de regressão multlinear usando as mesmas entradas.
Por que esses mapas importam para a saúde das pessoas
Ao transformar medições dispersas e imagens de satélite em estimativas diárias de temperatura na escala das ruas, este trabalho oferece uma nova ferramenta poderosa para saúde pública e planejamento urbano em São Paulo e além. Pesquisadores podem agora estudar como o calor afeta diferentes bairros, incluindo assentamentos informais que muitas vezes estão ausentes dos registros oficiais, e identificar onde os moradores correm mais risco durante ondas de calor. Como o método se baseia inteiramente em dados abertos e software padrão, ele pode ser adaptado a outras cidades que disponham de algumas estações terrestres e cobertura satelital similar. Em termos simples, o estudo mostra que agora podemos “ver” o calor urbano com muito mais detalhe, fornecendo uma base essencial para uma adaptação climática mais justa, direcionada e para a proteção de comunidades vulneráveis.
Citação: Roca-Barceló, A., Schneider, R., Pirani, M. et al. A satellite based machine learning approach for estimating high resolution daily average air temperature in a megacity in Brazil. Sci Rep 16, 7459 (2026). https://doi.org/10.1038/s41598-026-35689-x
Palavras-chave: calor urbano, aprendizado de máquina, dados de satélite, São Paulo, temperatura do ar