Clear Sky Science · pt
Geração de imagens artísticas coloridas guiadas visualmente usando GAN aprimorado
Por que máquinas de arte mais inteligentes importam
Ferramentas digitais já conseguem pintar retratos, paisagens e cenas abstratas em segundos, mas muitas dessas obras geradas por IA ainda parecem um pouco estranhas — as cores entram em conflito, as texturas soam achatadas ou o “estilo” não coincide com o que as pessoas imaginam. Este artigo apresenta uma nova forma de ensinar computadores a criar obras coloridas mais ricas, coerentes e próximas de pinturas reais, permitindo que usuários ajustem o resultado com dicas visuais simples, como esboços e escolhas de cor. O objetivo é tornar a IA um parceiro criativo mais confiável para artistas, designers e usuários comuns que querem arte personalizada sem precisar de anos de treinamento.
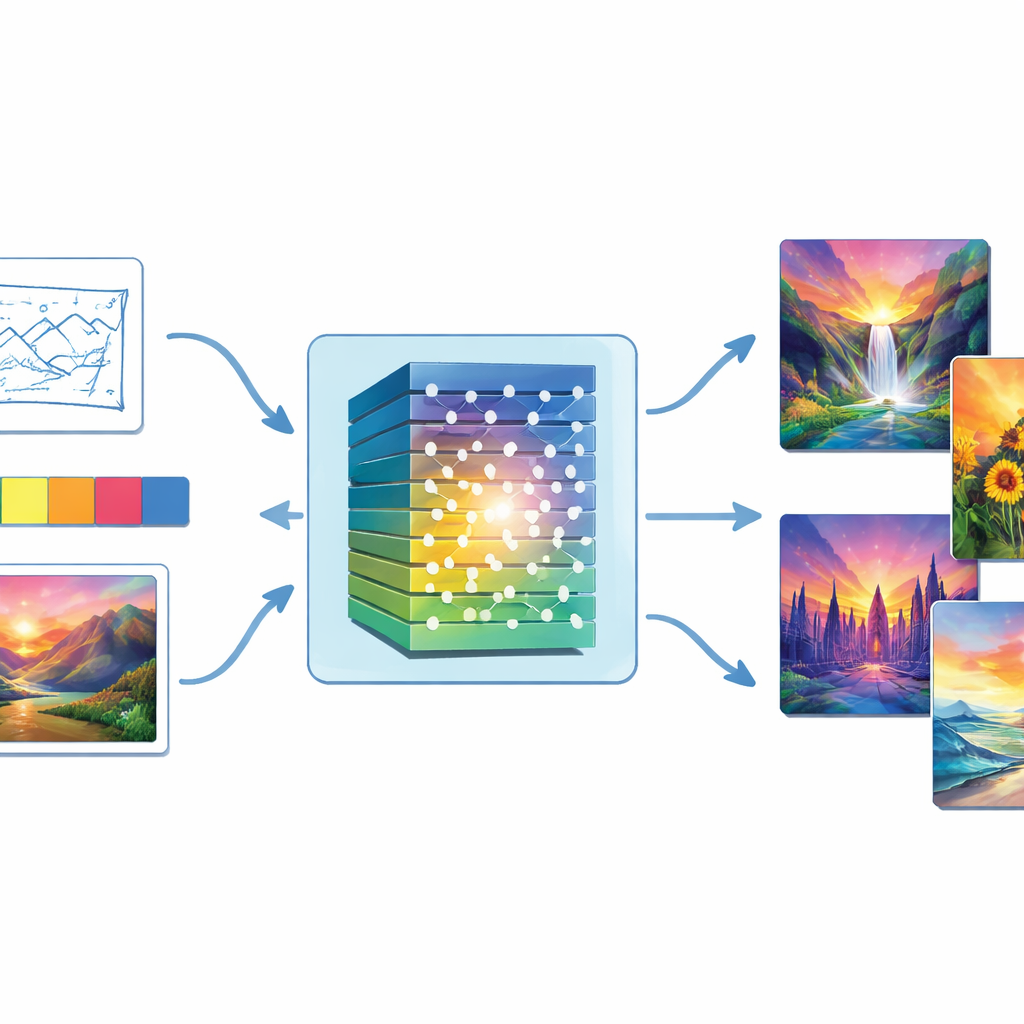
Do ruído aleatório a pinturas concluídas
No cerne do estudo está um tipo de IA chamado Rede Generativa Adversarial, ou GAN. Um GAN é formado por duas partes opostas: um “gerador” que tenta produzir imagens convincentes a partir de ruído aleatório, e um “discriminador” que julga se uma imagem parece real ou falsa. Por meio de muitas rodadas de treinamento, o gerador melhora em enganar o discriminador, e as imagens gradualmente se tornam mais realistas. Os autores fortalecem essa ideia central inserindo uma pilha profunda de processamento de imagem — chamada rede neural convolucional — tanto no gerador quanto no discriminador, para que o sistema capture melhor desde formas amplas até detalhes finos semelhantes a pinceladas.
Ensinando o sistema onde olhar
Embora GANs padrão possam produzir imagens nítidas, eles frequentemente perdem a visão de conjunto: podem supervalorizar pequenos detalhes e perder a estrutura global, ou falhar em manter um estilo artístico consistente. Para tratar isso, a equipe adiciona um mecanismo de atenção adaptativa. Esse módulo analisa os mapas de características internos do gerador e aprende, durante o treinamento, quais regiões da imagem importam mais a cada momento. Em seguida, ele fortalece essas áreas-chave — como contornos, texturas e objetos centrais — enquanto suaviza zonas de fundo menos importantes. Medidas de perda especiais acompanham o quanto a imagem gerada corresponde ao estilo e à textura de uma obra de referência, pressionando o modelo a equilibrar conteúdo reconhecível com um aspecto artístico coerente.
Guiando a máquina com pistas visuais
Diferente de sistemas somente-texto, essa abordagem permite que pessoas orientem a obra com guia visual direta. Usuários podem fornecer um esboço para definir a composição, uma paleta de cores para estabelecer o tom, uma imagem de estilo de referência para imitar ou etiquetas simples de cena. Essas entradas entram no gerador junto ao ruído aleatório. O modelo então calcula propriedades de cor como matiz, saturação e luminância, e ajusta sua saída para que a pintura final respeite tanto as intenções cromáticas do usuário quanto o estilo de referência. Um objetivo de correspondência de cor reforça ainda mais o vínculo entre o que o usuário indica e o que o sistema produz, evitando, por exemplo, que um marazul frio se transforme inesperadamente em um pôr do sol quente.
Aprendendo a melhorar por tentativa e erro
O sistema vai além ao usar aprendizado por reforço profundo, uma técnica inspirada no aprendizado por tentativa e erro. Aqui, um módulo separado de tomada de decisão trata a diferença entre a saída atual e a orientação alvo como seu “estado” e propõe pequenos ajustes em elementos como intensidade do esboço ou pesos da paleta como suas “ações”. Após cada mudança, o sistema mede quanto as métricas de qualidade da imagem melhoram — como relação sinal-ruído de pico, similaridade estrutural e perda de estilo — e usa isso como sinal de recompensa. Com o tempo, esse ciclo aprende uma política que ajusta automaticamente as orientações para conduzir o gerador a imagens que sejam ao mesmo tempo visualmente fiéis e artisticamente consistentes.
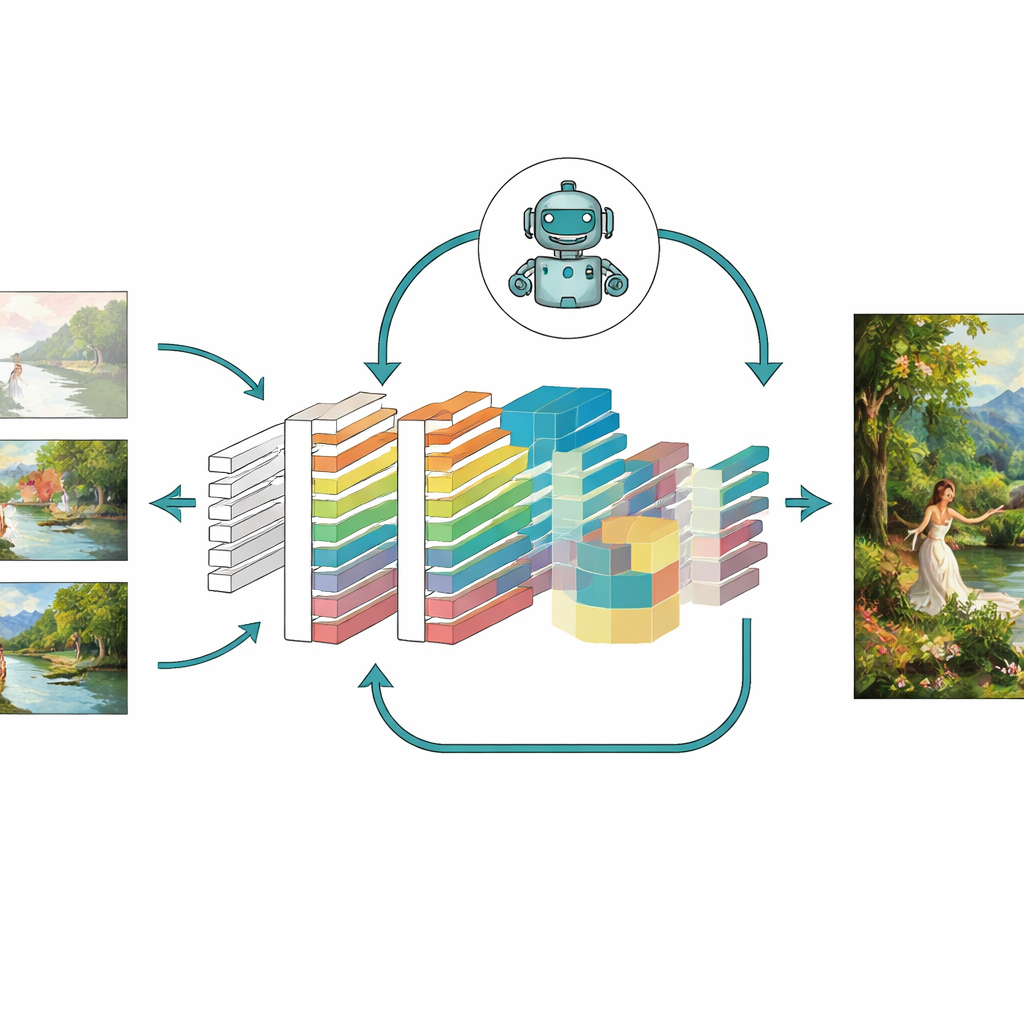
Submetendo o modelo ao teste
Para avaliar se essas ideias realmente ajudam, os autores testaram seu modelo aprimorado — chamado CNN-GAN — em uma grande coleção de pinturas da Universidade de Oxford e em um conjunto personalizado com mais de 5.000 obras coloridas em estilos como retratos, paisagens e cenas abstratas. Eles compararam os resultados com vários sistemas conhecidos, incluindo variantes clássicas de GAN, autoencoders e até geradores modernos baseados em difusão. Em muitas métricas, o novo modelo produziu imagens mais nítidas com menos artefatos, maior correspondência estrutural com obras reais, menor distância perceptual em relação às imagens de referência e maior diversidade nos tipos de cenas que podia gerar. Estudos de ablação, que removeram um módulo por vez, mostraram que atenção, aprendizado por reforço e o desenho combinado das perdas contribuíram cada um com melhorias significativas, e juntos ofereceram o melhor desempenho.
O que isso significa para futuras ferramentas criativas
Em termos simples, o artigo descreve uma máquina de pintar que não apenas aprende com milhares de obras, mas também presta atenção especial às regiões importantes, escuta as dicas visuais dos usuários e gradualmente aprende a ajustar essas indicações para obter melhores resultados. O resultado é uma IA que pode gerar imagens de alta qualidade e estilo unificado de forma mais confiável do que métodos anteriores, mantendo espaço para direção humana. Embora o sistema ainda tenha dificuldades com texturas extremamente intrincadas e dependa de grande volume de dados de treinamento, os autores sugerem extensões futuras — como módulos multiescala e redes mais leves — para torná-lo mais eficiente e amplamente utilizável. Juntos, esses avanços apontam para ferramentas de arte por IA que são mais rápidas, mais fiéis à intenção do usuário e melhores em capturar o caráter sutil de pinturas feitas por humanos.
Citação: Wu, Z. Visual guided AI color art image generation using enhanced GAN. Sci Rep 16, 9345 (2026). https://doi.org/10.1038/s41598-026-35625-z
Palavras-chave: geração de arte por IA, transferência de estilo de imagem, redes generativas adversariais, criatividade artificial, síntese neural de imagens