Sempre que governos, cientistas ou institutos de pesquisa tentam aprender algo sobre uma população inteira — como renda média, produtividade de culturas ou níveis de poluição — raramente medem todo mundo. Em vez disso, extraem uma amostra e ampliam os resultados. Isso funciona bem apenas se os dados se comportarem de forma estável. Na prática, porém, pesquisas e medições estão repletas de erros e valores extremos que podem distorcer fortemente os resultados. Este artigo apresenta uma nova forma de calcular médias populacionais que permanece confiável mesmo quando os dados são problemáticos, tornando decisões baseadas em pesquisas mais dignas de confiança.
Quando médias simples falham
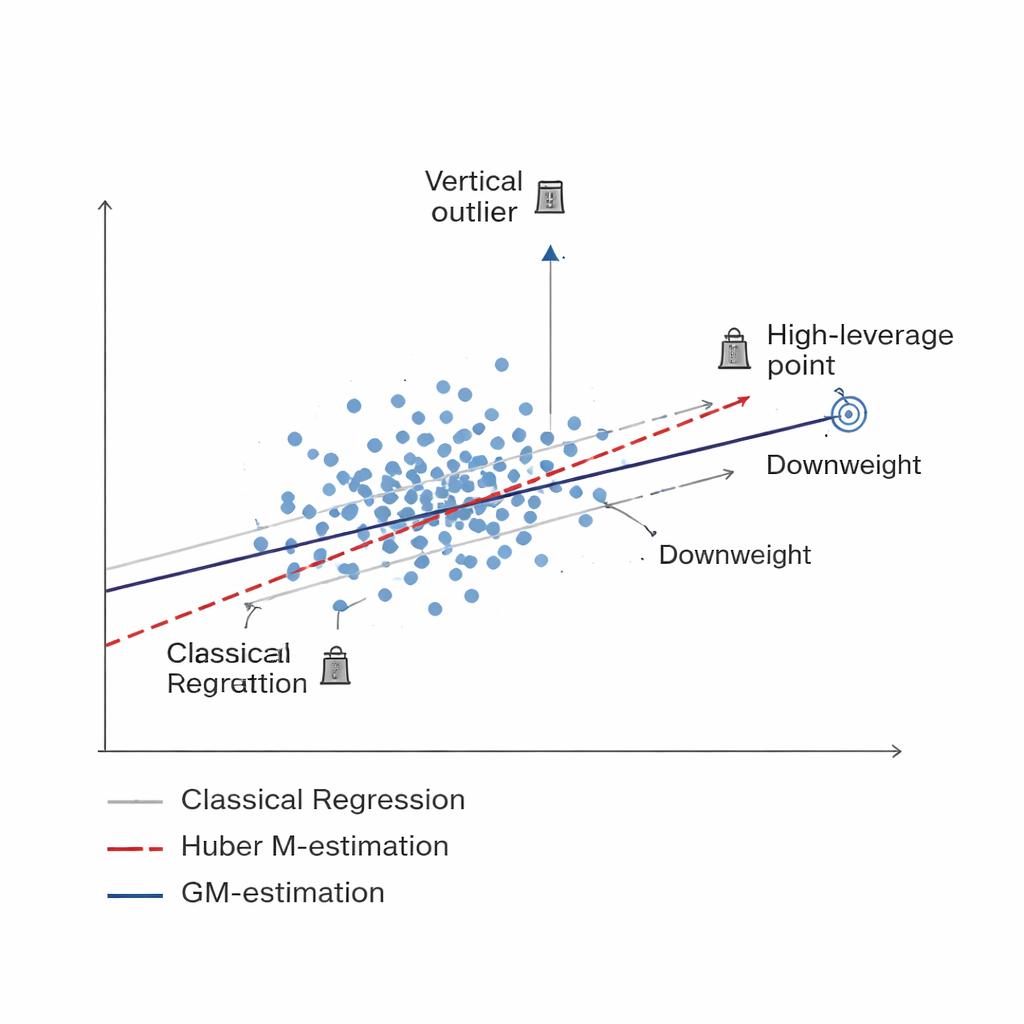
Ferramentas padrão para estimar uma média populacional, como a média amostral simples ou regressão ordinária, assumem que a maioria dos pontos de dados segue padrões suaves, sem outliers extremos ou casos incomuns. Em pesquisas sociais e econômicas, monitoramento ambiental e estatísticas agrícolas, essa expectativa muitas vezes não se confirma. Algumas leituras defeituosas, eventos raros porém extremos, ou respostas registradas incorretamente podem afastar as estimativas da verdade, aumentando tanto o viés quanto a incerteza. Trabalhos anteriores tentaram atenuar o impacto desses outliers usando métodos ditos robustos, incluindo uma abordagem popular conhecida como estimação M de Huber. Embora úteis, esses métodos protegem principalmente contra valores extremos na variável de desfecho e continuam vulneráveis a padrões incomuns nas variáveis explicativas associadas.
Uma forma mais inteligente de reduzir o peso de dados ruins Figure 1.
O estudo desenvolve uma nova família de estimadores baseada na estimação M generalizada, ou GM-estimação. Em vez de tratar cada unidade amostrada igualmente, os métodos GM atribuem pesos adaptativos que dependem de duas coisas ao mesmo tempo: quão extremo é o valor observado de uma unidade (um outlier vertical) e quão incomum é a informação associada a ela (um ponto de alta alavancagem). Três versões específicas — chamadas Mallows-GM, Schweppes-GM e SIS-GM — foram projetadas para cenários comuns de amostragem, incluindo amostragem aleatória simples sem reposição e desenhos estratificados mais complexos, onde a população é dividida em grupos relativamente homogêneos. Ao controlar conjuntamente ambos os tipos de observações problemáticas, esses estimadores buscam manter a estimativa final da média populacional estável mesmo quando os dados contêm contaminação séria.
Submetendo os novos estimadores ao teste
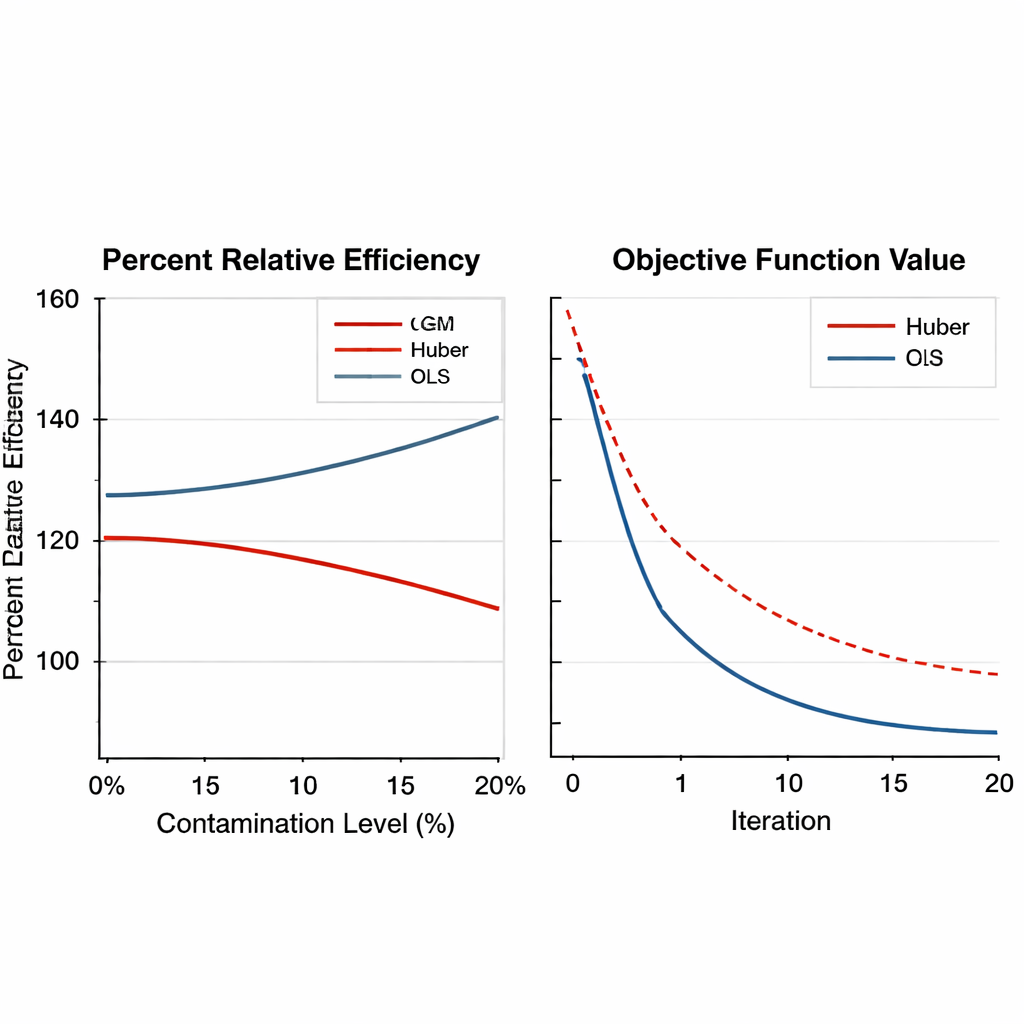
Para avaliar o desempenho dos estimadores baseados em GM, o autor realiza extensos experimentos numéricos. Primeiro, dados reais da agricultura do tabaco são analisados em duas formas: uma versão limpa e outra deliberadamente contaminada onde uma unidade é substituída por valores extremos. Os novos estimadores são comparados com métodos tradicionais de regressão e com métodos robustos baseados em Huber usando uma medida chamada eficiência relativa percentual, que reflete quanto menor é o erro de estimação. Ao longo de uma ampla faixa de tamanhos amostrais, os estimadores GM superam consistentemente os métodos anteriores, especialmente quando os dados incluem valores extremos. Em alguns cenários, o estimador GM de melhor desempenho reduz o erro em mais de 50% em comparação com a abordagem de Huber.
Robustez entre desenhos, cenários e escolhas de ajuste Figure 2.
O artigo amplia então os testes usando simulações computacionais em larga escala. Populações artificiais são geradas sob várias formas — distribuições normal, assimétrica e de cauda pesada — e contaminadas com frações crescentes de outliers, de nenhuma até 20%. Consideram-se planos de amostragem simples e estratificados, e a força da relação entre a variável principal e suas auxiliares é variada de fraca a forte. Os estimadores GM não apenas mantêm sua vantagem sob forte contaminação, frequentemente alcançando ganhos de eficiência acima de 150%, como também mostram convergência numérica suave e confiável. Importante, seu desempenho varia pouco quando os parâmetros internos de ajuste são alterados dentro de faixas razoáveis, o que significa que os praticantes não precisam refiná-los minuciosamente para cada nova pesquisa.
O que isso significa para pesquisas do mundo real
Em termos simples, o artigo demonstra que os estimadores propostos baseados em GM oferecem uma forma mais segura de transformar amostras imperfeitas em estimativas de médias populacionais. Em condições ideais e com dados limpos, eles são tão precisos quanto os métodos clássicos. Mas quando os dados incluem erros de medição, valores incorretamente relatados ou eventos extremos raros — como ocorre frequentemente em pesquisas nacionais, monitoramento ambiental e estatísticas financeiras — eles fornecem respostas substancialmente mais confiáveis. Por serem computacionalmente viáveis e funcionarem bem em diferentes desenhos e cenários, esses estimadores oferecem aos profissionais de pesquisa uma atualização prática que pode tornar decisões baseadas em evidências mais resilientes à inevitável bagunça dos dados do mundo real.
Citação: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5
Palavras-chave: amostragem por inquérito, estimação robusta, valores-atípicos, estimação M generalizada, média de população finita