Clear Sky Science · pt
Geolocalização de usuários sociais baseada em K-medoids e rede de atenção em grafos com núcleo Gaussiano
Por que seus tweets podem revelar onde você mora
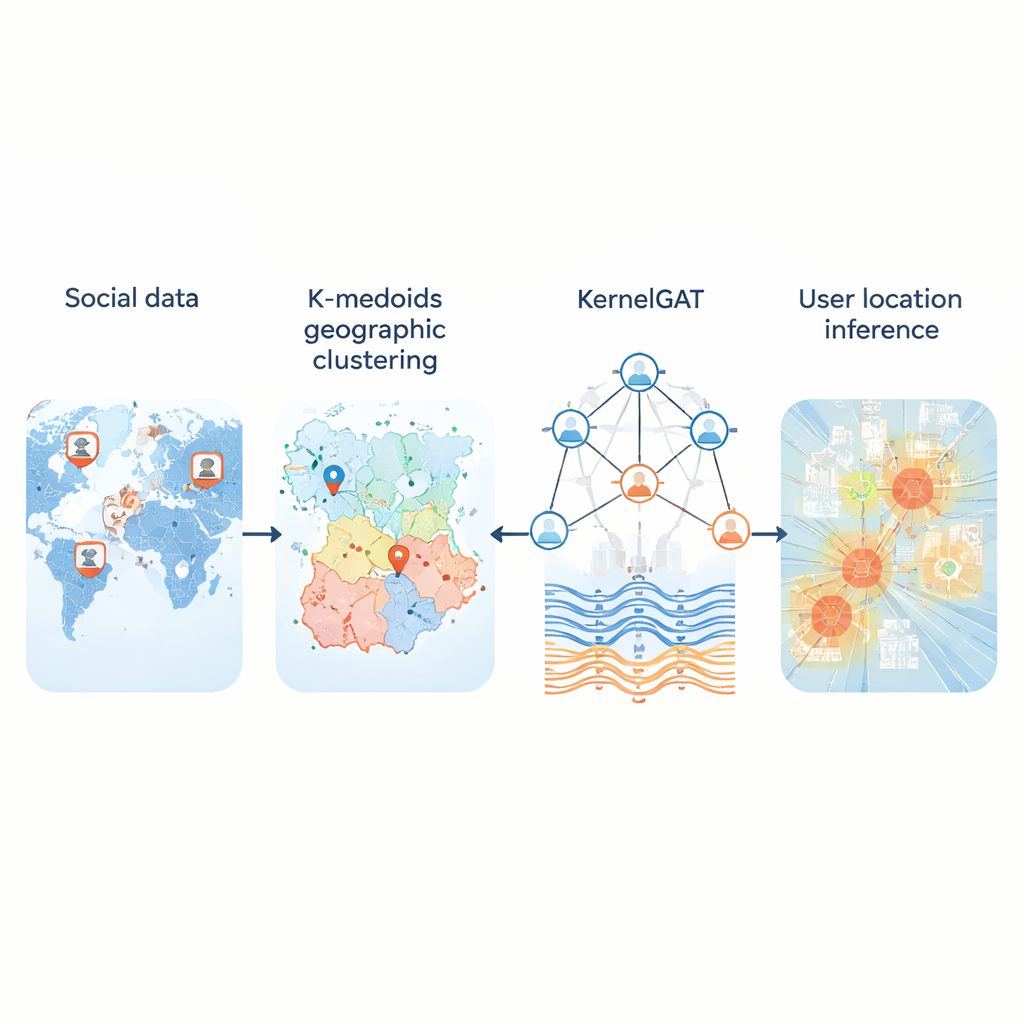
Todos os dias, milhões de pessoas postam em redes sociais sem compartilhar suas coordenadas GPS. Ainda assim, essas postagens deixam pistas sobre onde os usuários vivem, trabalham e viajam. Conseguir inferir a localização a partir desse rastro público é importante para tudo, desde resposta a emergências e rastreamento de doenças até recomendações locais e serviços direcionados. Este artigo apresenta um novo método, chamado KMKGAT, que usa tanto o conteúdo do que as pessoas dizem quanto como estão conectadas online para estimar sua localização com mais precisão do que abordagens anteriores.
Do papo online a lugares do mundo real
Quando usuários escrevem tweets ou microblogs, eles podem mencionar nomes de lugares, usar gírias locais ou interagir com amigos próximos. Empresas como o Twitter (agora X) conhecem o endereço de internet do usuário, mas pesquisadores externos e provedores de serviço normalmente não. Em vez disso, eles precisam trabalhar com informações públicas: o próprio texto, perfis de usuário e quem conversa com quem. Métodos anteriores se dividiam em três grupos. Métodos só de conteúdo mineravam palavras e hashtags para estimar locais. Métodos só de rede baseavam-se no fato de que as pessoas tendem a interagir com usuários próximos. Uma terceira família, mais poderosa, combinava ambas as visões, mas ainda tinha pontos cegos — especialmente para pessoas em áreas pouco povoadas e para usuários cujas conexões online abrangem grandes distâncias.
Agrupamento geográfico mais inteligente com centros reais de usuários
Um problema central é como transformar o globo contínuo em um conjunto de regiões que um computador possa aprender a prever. Muitos sistemas fatiam o mapa em uma grade fixa. Isso funciona razoavelmente bem nas cidades, mas falha em áreas rurais, onde células enormes cobrem muitas centenas de quilômetros. O novo método substitui grades rígidas por clustering k-medoids, uma forma de agrupar usuários de modo que cada região seja centrada em um usuário real em vez de um ponto artificial. Isso torna as regiões compactas e menos sensíveis a outliers, particularmente onde os usuários são escassos. Em testes em três grandes conjuntos de dados do Twitter cobrindo os Estados Unidos e o mundo, esse particionamento adaptativo reduziu erros típicos em comparação com esquemas baseados em grade e forneceu “regiões residenciais” mais realistas para os usuários.
Deixando a rede focar em usuários próximos e semelhantes
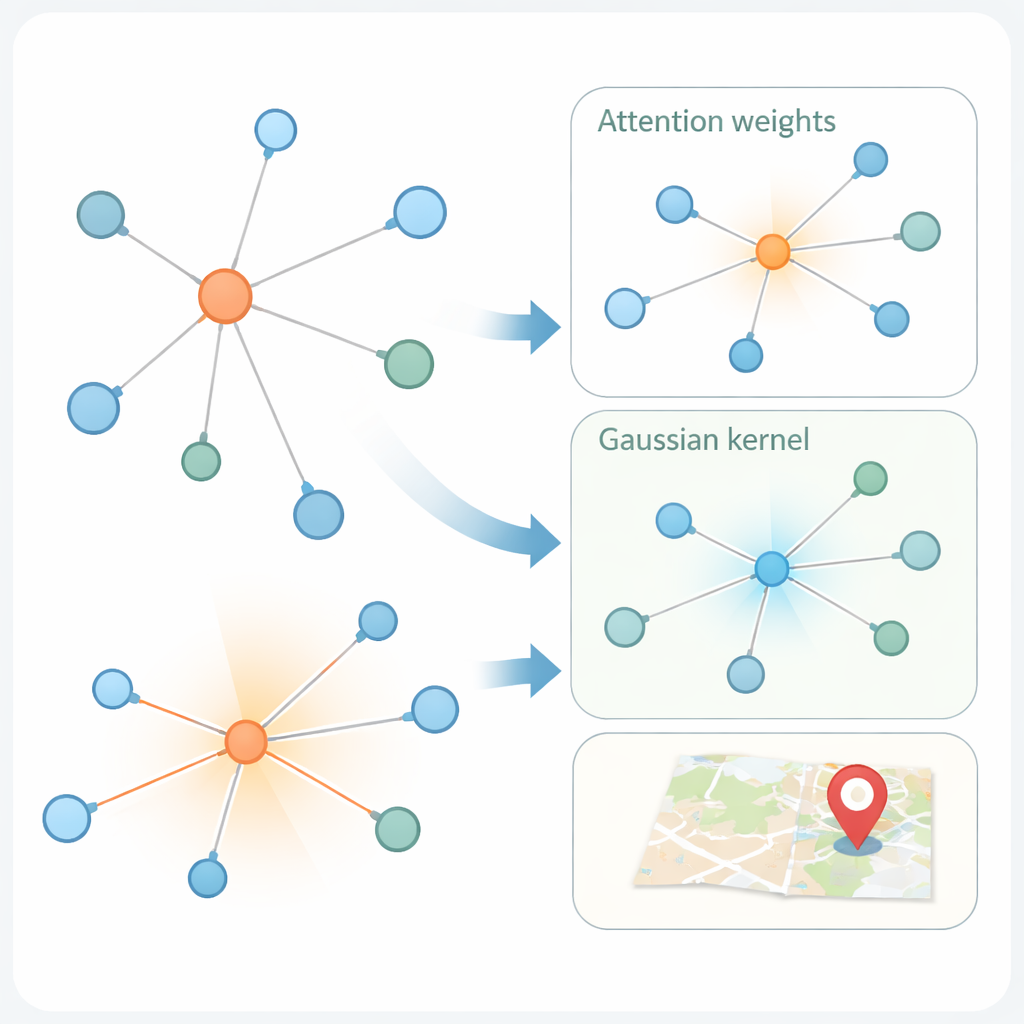
A segunda inovação está em como o modelo aprende a partir do grafo social. Redes modernas de “atenção em grafos” já ponderam os vizinhos de um usuário de forma diferente, com base em quão semelhantes são suas representações de características. Mas a similaridade por si só pode enganar: uma conta em Nova York e outra em Londres podem usar linguagem semelhante e ainda assim estar longe geograficamente. KMKGAT amplia a atenção com um núcleo Gaussiano, um filtro matemático que favorece vizinhos cujas características aprendidas são próximas ao usuário-alvo e diminui a influência de vizinhos distantes. Múltiplos núcleos desse tipo, combinados como uma mistura de lentes, permitem que o modelo capture localidade em diferentes escalas. Isso respeita o princípio simples, porém poderoso, de que interações online são frequentemente mais fortes entre pessoas fisicamente mais próximas.
Características de texto leves que ainda carregam pistas de localização
Em vez de depender de pesados modelos de linguagem profunda, que podem ter dificuldade com o estilo ruidoso e cheio de gírias dos tweets, os autores usam uma técnica clássica chamada TF–IDF para transformar a coleção de postagens de cada usuário em um conjunto de palavras-chave ponderadas. Palavras comuns como “the” ou “lol” recebem pouco peso, enquanto termos raros e específicos de região sobem ao topo. Essas características de texto são então associadas a cada usuário no grafo social e passadas pela rede de atenção aprimorada. Curiosamente, os melhores resultados foram obtidos quando a maioria das características de texto era aleatoriamente descartada durante o treinamento, sugerindo que apenas uma pequena fração das palavras realmente ajuda na localização e o resto adiciona principalmente ruído.
Superando o estado da arte em escala
Para avaliar o desempenho, os pesquisadores mediram a distância, em quilômetros, entre o centro da região prevista e as coordenadas conhecidas de cada usuário, e qual porcentagem de usuários foi posicionada dentro de 161 km (100 milhas) de sua localização real. Em três conjuntos de dados de referência do Twitter, o KMKGAT consistentemente igualou ou superou sistemas fortes existentes, melhorando a acurácia dentro de 161 quilômetros em até alguns pontos percentuais — um ganho significativo nesse nível de maturidade. Os benefícios foram mais claros em redes pequenas e de porte médio, enquanto em um grafo global massivo o método foi limitado pela necessidade de amostrar apenas vizinhos imediatos durante o treinamento.
O que isso significa no dia a dia
Para não especialistas, a conclusão é que torna-se cada vez mais viável estimar onde usuários de redes sociais estão, mesmo se nunca compartilharem uma marcação de localização. Ao agrupar usuários em regiões realistas com base em contas reais e ao ensinar o modelo a confiar principalmente em vizinhos próximos e semelhantes na rede social, o KMKGAT aproxima a estimativa de onde alguém provavelmente mora ou publica. Isso pode ajudar socorristas a encontrar pessoas durante desastres, melhorar busca e recomendações locais e apoiar estudos sobre como a informação se espalha entre lugares. Ao mesmo tempo, ressalta quanto nossas interações online ordinárias podem revelar sobre nossa vida offline, sublinhando a importância do uso cuidadoso dos dados e de proteções de privacidade.
Citação: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
Palavras-chave: geolocalização em redes sociais, localização de usuários no Twitter, redes neurais em grafos, serviços baseados em localização, privacidade online