Clear Sky Science · pt
Identificação automatizada de entidades biomédicas contextualmente relevantes com LLMs fundamentados
Por que marcar melhor os artigos médicos importa
Cada ano, surgem milhares de estudos biomédicos, repletos de detalhes sobre genes, tipos celulares, doenças e tratamentos. No entanto, a maior parte dessa informação fica presa em longos PDFs, dificultando que outros cientistas encontrem os dados exatos de que precisam. Este artigo explora como a inteligência artificial moderna — grandes modelos de linguagem, ou LLMs — pode extrair automaticamente esses termos biomédicos-chave de artigos científicos, ajudando a transformar publicações dispersas em recursos bem organizados e pesquisáveis.
De artigos desordenados a blocos de construção pesquisáveis
Centros de pesquisa biomédica, como os Centros Colaborativos de Pesquisa da Alemanha, dependem de dados claros e estruturados para tornar estudos reutilizáveis por anos. Tradicionalmente, pesquisadores precisavam marcar manualmente seus conjuntos de dados com entidades importantes, como organismos, linhagens celulares e genes — uma tarefa tediosa e demorada. LLMs podem ler textos completos e entender o contexto, tornando-se ferramentas promissoras para automatizar essa marcação. Mas há um porém: decidir quais termos são realmente relevantes depende da questão científica e de como os dados serão reutilizados. Os autores trabalham dentro de um esquema de metadados cuidadosamente desenhado pelo CRC focado em nefrologia, o “NephGen”, que indica à IA que tipos de entidades procurar e como elas devem ser organizadas.
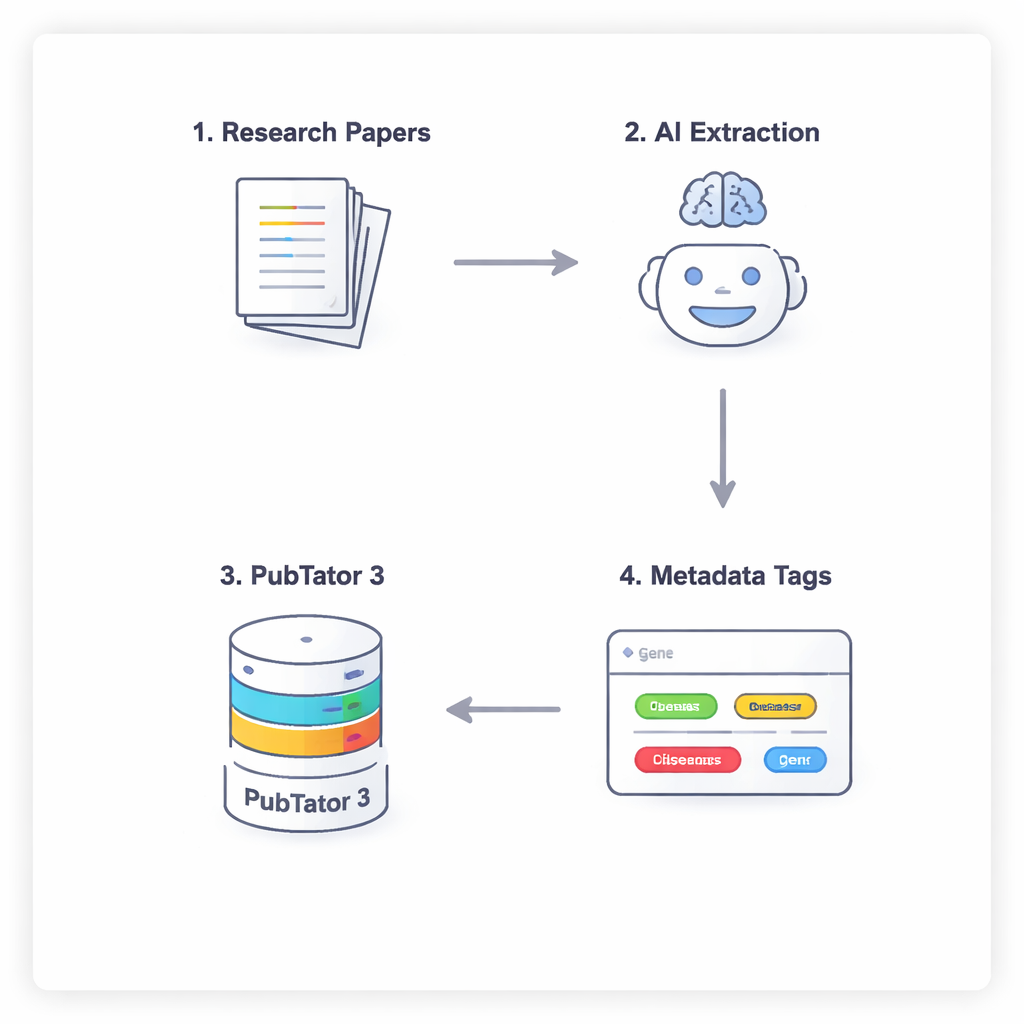
Uma conversa em quatro etapas entre a IA e um banco de dados biológico
Para impedir que a IA simplesmente chute ou “alucine” fatos biomédicos, os pesquisadores usam um processo em quatro etapas que força os modelos a raciocinar com cuidado e checar suas respostas. Primeiro, o modelo escaneia o texto completo do artigo (ignorando discussão e referências) para sugerir entidades potencialmente relevantes. Em segundo lugar, deve consultar uma ferramenta externa, o PubTator 3, um grande banco de dados biomédico, para confirmar que cada termo sugerido realmente existe e tem um identificador reconhecido. Terceiro, a IA atribui cada entidade confirmada a um campo no esquema de metadados do NephGen, que organiza entidades em uma estrutura hierárquica projetada por humanos. Finalmente, o modelo consolida tudo isso em uma saída JSON estruturada, basicamente um resumo legível por máquina e organizado das principais entidades biomédicas no artigo.
Testando oito modelos de IA com pesquisa real em rim
A equipe implementou esse fluxo de trabalho usando APIs de 14 LLMs diferentes e descobriu que apenas oito conseguiam seguir de forma confiável os requisitos estritos, como retornar JSON válido e usar corretamente ferramentas. Eles então aplicaram esses oito modelos a seis artigos de pesquisa em nefrologia e pediram que o autor de cada artigo revisasse a lista final de entidades gerada pela IA em uma breve entrevista presencial. Como não existe um número “correto” fixo de entidades a extrair, os autores focaram na precisão: que fração das entidades sugeridas os cientistas julgaram corretas. Usando métodos de meta-análise estatística adaptados para proporções próximas de 100%, estimaram a precisão de cada modelo levando em conta a variação entre os artigos.
Alta acurácia, mas compensações em esforço, custo e velocidade
Entre todos os modelos, os sistemas de IA alcançaram uma precisão geral de cerca de 91%, ou seja, a grande maioria das entidades sugeridas foi julgada correta. GPT-4.1, GPT-4o Mini e Gemini 2.0 Flash apresentaram as maiores precisões — em torno de 94% a 98% — embora as diferenças entre eles não tenham sido estatisticamente claras. Modelos Gemini tenderam a propor mais entidades no total, resultando em mais marcações corretas, mas também em mais itens para revisão humana. Alguns modelos menores ou mais baratos, como GPT-4.1 Nano, foram mais rápidos e econômicos, porém consideravelmente menos precisos. Os autores visualizaram essas tensões usando frentes de Pareto, identificando combinações de modelos que equilibram precisão, número de entidades corretas, custo e tempo de processamento: por exemplo, o GPT-4o Mini emergiu como particularmente atraente quando tanto a precisão quanto o baixo custo são prioridades.
Por que os humanos ainda devem estar no circuito
Apesar do bom desempenho, o estudo destaca limitações importantes. Os modelos às vezes confundiram informações sobre o artigo publicado com detalhes que não eram realmente relevantes para o conjunto de dados subjacente que futuros usuários poderiam querer reutilizar. Essa confusão reflete um desafio mais amplo na mineração automatizada de texto: artigos científicos discutem muito mais do que aquilo que acaba em um conjunto de dados compartilhado. Os autores, portanto, recomendam que especialistas humanos continuem a revisar as anotações geradas pela IA antes da publicação. Observam também que a avaliação abrange apenas seis artigos de nefrologia, de modo que testes mais amplos em outras áreas são necessários. Ao longo do tempo, um fluxo de trabalho rotineiro com “human-in-the-loop” pode construir um conjunto de referência consensual, possibilitando medir não apenas a precisão, mas também quantas entidades a IA deixou de captar.
O que isso significa para o compartilhamento futuro de dados biomédicos
O estudo mostra que, quando guiados cuidadosamente e fundamentados em bases de dados confiáveis, os LLMs modernos podem ajudar de forma confiável a anotar artigos biomédicos, reduzindo muito o esforço manual dos pesquisadores. Os melhores modelos se aproximam da precisão em nível de especialista, ao mesmo tempo em que oferecem diferentes trade-offs entre abrangência, custo e velocidade. Por ora, a revisão humana continua essencial para garantir que as anotações correspondam realmente aos conjuntos de dados e ao contexto da pesquisa. Mas à medida que as ferramentas e modelos de código aberto amadurecem, fluxos de trabalho como este podem se tornar a espinha dorsal padrão para transformar a enxurrada atual de artigos médicos em futuros commons de dados bem organizados e reutilizáveis.
Citação: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
Palavras-chave: mineração de texto biomédico, grandes modelos de linguagem, anotação de metadados, IA fundamentada, pesquisa em nefrologia