Clear Sky Science · pt
Combinando fragmentação de parâmetros e embaralhamento em grupo para defender-se contra o servidor não confiável em aprendizado federado
Por que proteger modelos compartilhados importa
Nossos telefones, hospitais e bancos são cada vez mais movidos por inteligência artificial. Frequentemente, muitas organizações gostariam de treinar um modelo compartilhado em conjunto, mas leis e o bom senso dizem que não se deve reunir os dados brutos em um único lugar. O aprendizado federado foi criado para resolver essa tensão: cada participante treina em seu próprio dispositivo e compartilha apenas atualizações do modelo. Mas este artigo mostra que até mesmo essas atualizações podem vazar informações privadas se o servidor central for curioso ou desonesto — e então apresenta um novo método para manter tanto nossos dados quanto nossas identidades mais seguros.
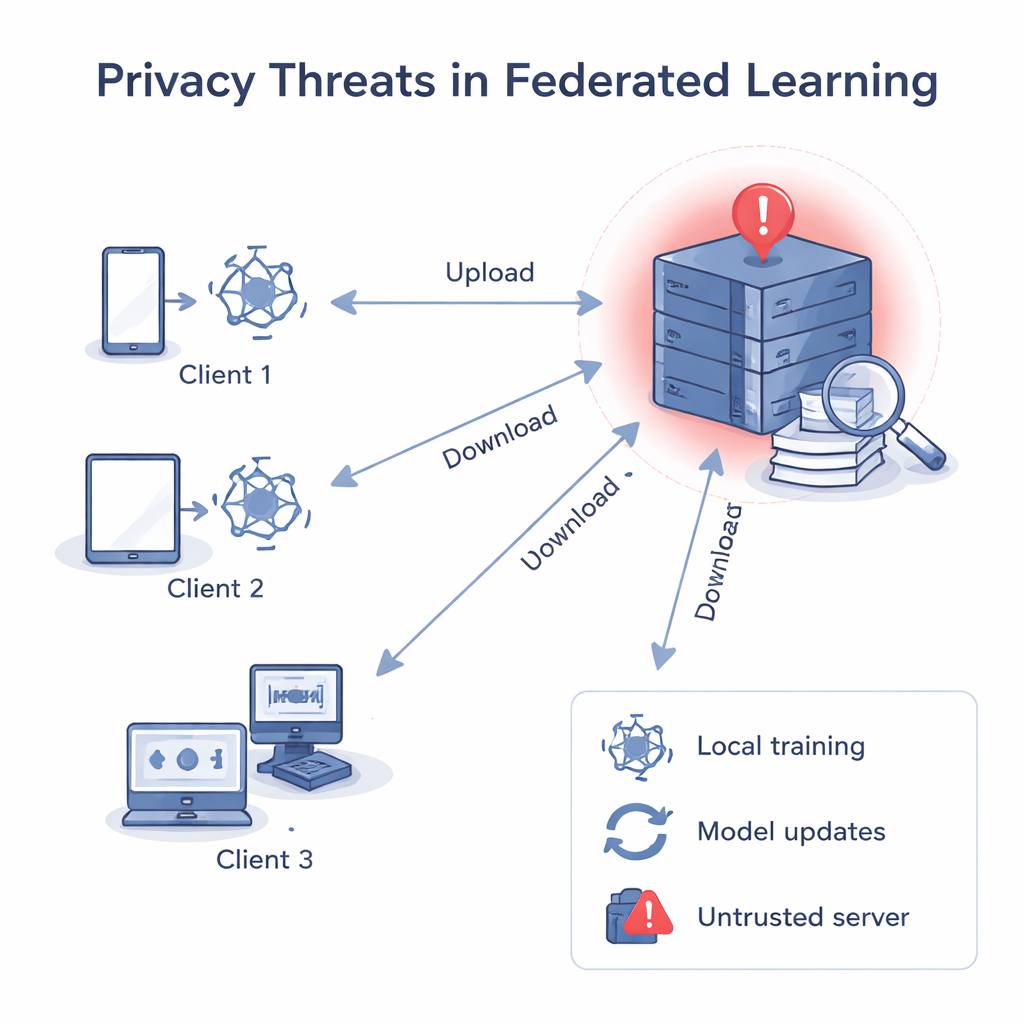
Quando o servidor não deve ser confiável
No aprendizado federado clássico, um servidor central envia um modelo comum, cada cliente o aprimora usando seus próprios dados e então envia o modelo atualizado de volta. O servidor faz a média dessas atualizações para obter um modelo global melhor. Mesmo que os dados brutos nunca saiam dos dispositivos, pesquisas anteriores mostraram que gradientes e pesos — os números dentro do modelo — podem ser “executados ao contrário” para reconstruir dados privados, como imagens ou textos, ou para adivinhar se um registro específico foi usado no treinamento. Se o servidor central não for confiável, ele pode analisar a atualização de cada cliente separadamente, aprender sobre os dados locais desse cliente e até vincular uma atualização a uma pessoa ou organização específica.
Quebrando atualizações em pedaços inofensivos
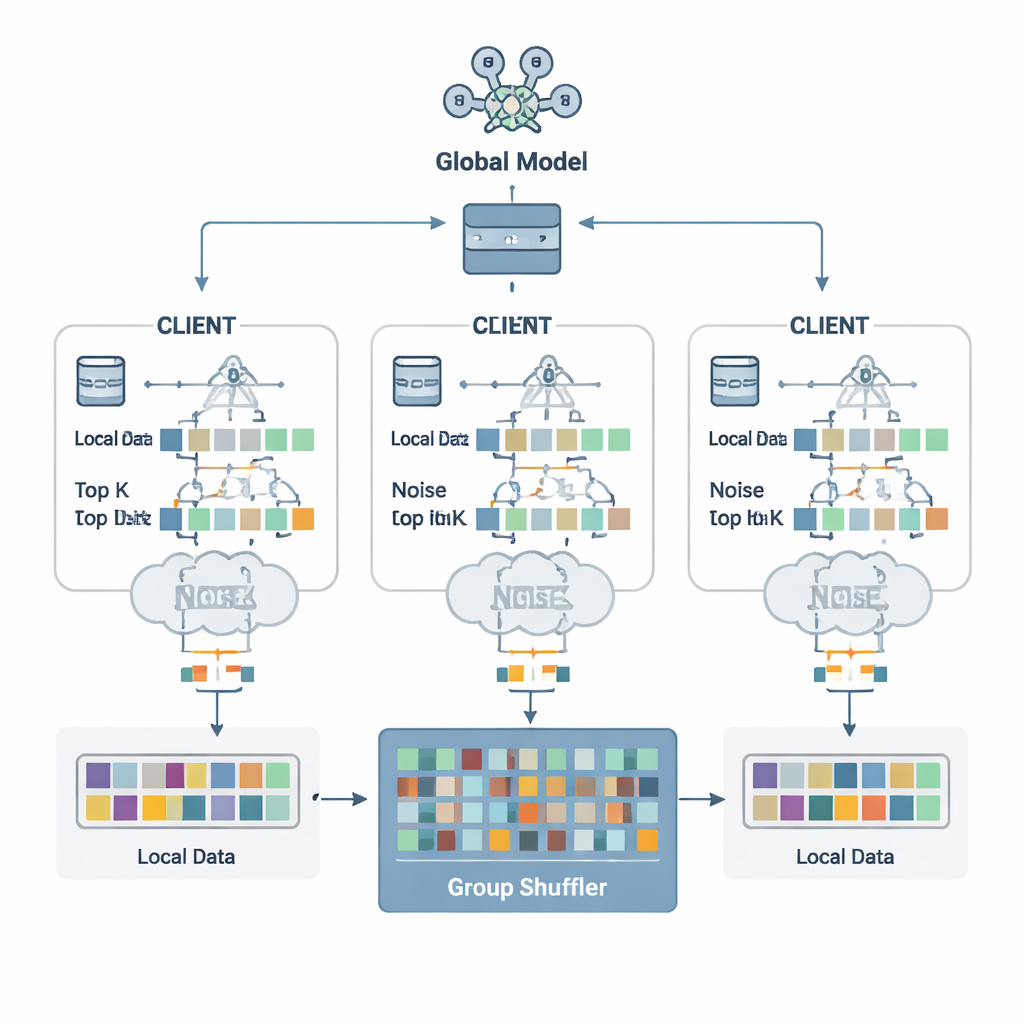
Os autores propõem um esquema de defesa chamado Segurança por Fragmentação de Parâmetros e Embaralhamento em Grupo (SDPFGS). A primeira ideia é simples, mas poderosa: nunca enviar uma atualização completa. Em vez disso, cada cliente divide sua atualização de modelo em vários “fragmentos” artificiais. A maior parte desses fragmentos é preenchida com números aleatórios, e apenas o último é ajustado para que todos os fragmentos ainda somem à atualização verdadeira. Qualquer fragmento isolado, ou mesmo vários deles, parece ruído e revela quase nada sobre os dados originais. Esse truque matemático é semelhante ao compartilhamento secreto: só combinando todas as partes é possível recuperar o todo.
Adicionando ruído e mexendo o conjunto
Enviar muitos fragmentos ainda poderia ser custoso e, se examinados em conjunto, poderia permitir que um atacante inferisse mais informações. Para evitar isso, cada cliente seleciona apenas os valores de fragmentos mais importantes — as Top-K entradas que mais importam para o aprendizado — e adiciona ruído aleatório cuidadosamente calibrado a eles, seguindo os princípios da privacidade diferencial. Esse ruído torna estatisticamente difícil dizer se os dados de uma pessoa específica influenciaram um determinado valor. Em seguida vem o segundo ingrediente chave: o embaralhamento em grupo. Em vez de enviar fragmentos diretamente ao servidor, os clientes os encaminham a um “embaralhador” confiável que mistura fragmentos de muitos clientes em grupos antes de repassá-los. Após essa mistura, o servidor não consegue mais dizer de qual cliente veio cada fragmento, rompendo o vínculo entre atualizações e identidades.
Manter a precisão enquanto reduz vazamentos
A equipe testou o SDPFGS em benchmarks padrão de imagem e texto, incluindo dígitos manuscritos (MNIST), fotos de roupas (Fashion-MNIST) e imagens coloridas (CIFAR-10 e CIFAR-100), além de uma tarefa de classificação de notícias. Eles compararam seu método com várias técnicas de privacidade de ponta que usam apenas ruído, apenas embaralhamento ou compressão simples de gradientes. Ao longo desses experimentos, o SDPFGS igualou ou superou consistentemente a precisão dos métodos concorrentes, enquanto usou menos comunicação e tempo de treinamento do que muitos deles. Mais notavelmente, sob ataques de inversão de modelo — em que um adversário tenta reconstruir exemplos de treinamento — o SDPFGS teve a menor taxa de sucesso dos ataques, ou seja, foi o que menos vazou sobre os dados subjacentes.
O que isso significa para usuários comuns
Para um leigo, a mensagem principal é que “esconder os dados” não é suficiente; também devemos ocultar o que nossos dispositivos enviam durante o treinamento. O SDPFGS faz isso transformando cada atualização de modelo em fragmentos barulhentos e embaralhados que são inúteis sozinhos, mas ainda se combinam em um modelo global de alta qualidade. O resultado é uma proteção mais forte contra um servidor curioso ou comprometido, com apenas um custo menor para precisão e eficiência. À medida que o aprendizado federado se espalha pela saúde, finanças e dispositivos inteligentes, técnicas como o SDPFGS podem ajudar a garantir que as pessoas se beneficiem de modelos compartilhados poderosos sem entregar as chaves de suas vidas privadas.
Citação: Guo, H., Chen, W., Li, J. et al. Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning. Sci Rep 16, 5097 (2026). https://doi.org/10.1038/s41598-026-35420-w
Palavras-chave: aprendizado federado, privacidade de dados, privacidade diferencial, ataques de inversão de modelo, agregação segura