Clear Sky Science · pt
Desacordo entre avaliação humana e de IA de planos de tratamento
Por que isso importa para o atendimento médico cotidiano
À medida que ferramentas de inteligência artificial (IA) começam a ajudar médicos na escolha de tratamentos, surge uma pergunta central: em quem confiamos mais — humanos ou máquinas? Este estudo investiga uma possibilidade simples porém inquietante: médicos e sistemas de IA podem discordar não apenas sobre qual tratamento é o melhor, mas também sobre o que conta como um “bom” plano de tratamento. Compreender essa lacuna é essencial se quisermos que a IA apoie, e não distorça silenciosamente, as decisões médicas no mundo real.
Um teste direto de conselhos de tratamento
Os pesquisadores concentraram-se em dermatologia, uma área em que médicos gerenciam condições de pele crônicas que raramente têm uma única resposta “correta”. Dez dermatologistas experientes e dois modelos de linguagem de grande porte (LLMs) — um modelo de uso geral e outro focado em raciocínio — foram cada um solicitados a elaborar planos de tratamento para cinco casos desafiadores e fictícios, como eczema severo, psoríase com outras comorbidades e acne relacionada à gravidez. Para manter a isonomia, os 60 planos foram editados para um formato comum: comprimento, estrutura e tom semelhantes. Quaisquer indícios óbvios sobre se o plano fora escrito por um humano ou por uma IA foram removidos, para que os avaliadores posteriores julgassem o conteúdo, não o estilo.
Como humanos e IA fizeram a avaliação
Os planos então passaram por duas rodadas de pontuação cega usando a mesma rubrica. Primeiro, o mesmo grupo de dez dermatologistas avaliou cada plano quanto à qualidade geral, de 0 a 10, considerando quão eficaz, seguro, prático e centrado no paciente ele era. Em seguida, um modelo de IA separado — usado apenas como avaliador, não como redator — pontuou esses mesmos planos com as mesmas instruções. Crucialmente, nem os avaliadores humanos nem o avaliador de IA sabiam quem havia escrito cada plano. Essa configuração permitiu aos autores isolar um fator chave: se o avaliador era humano ou IA.
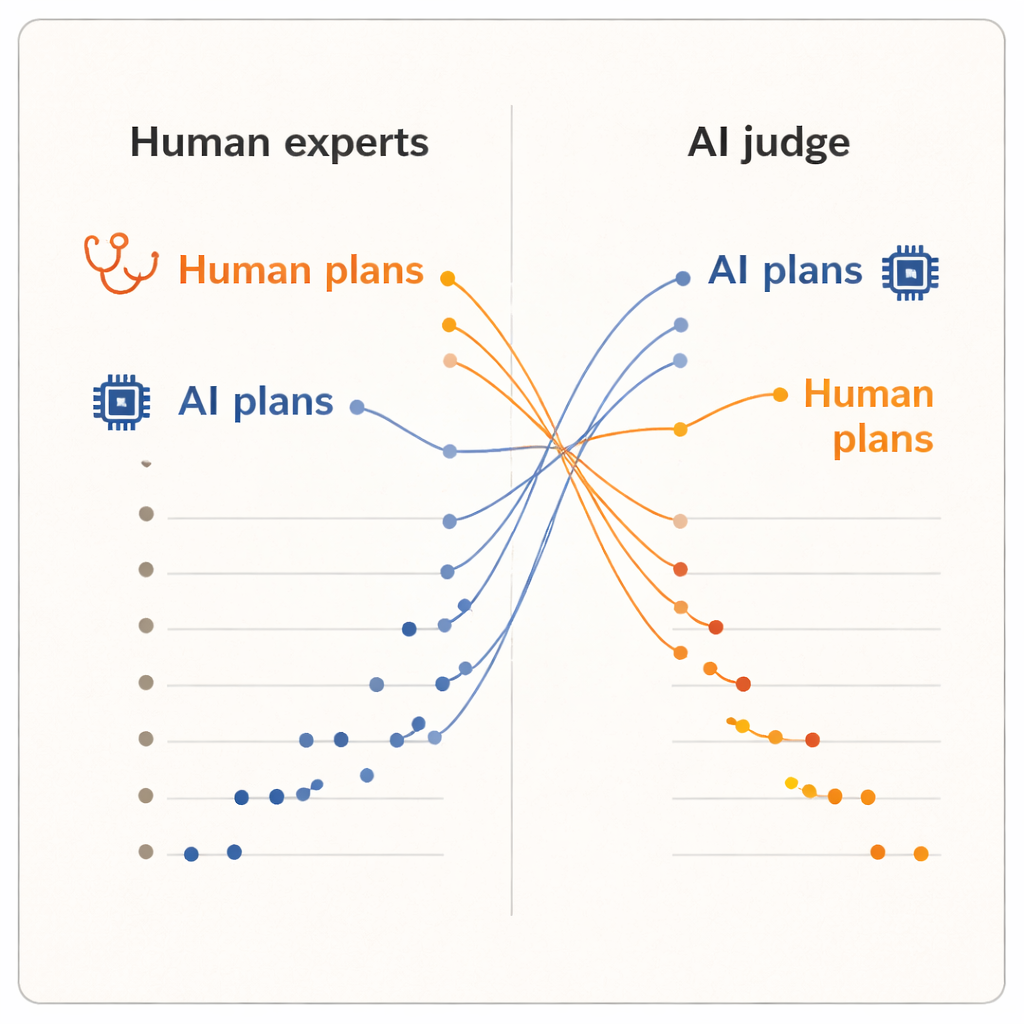
Humanos favorecem humanos, IA favorece IA
Os resultados mostraram um claro “efeito avaliador”. Quando os humanos pontuaram os planos, deram notas mais altas aos planos escritos por seus colegas dermatologistas do que aos produzidos por qualquer um dos sistemas de IA. Os planos gerados por humanos tiveram média um pouco superior e ocuparam as cinco primeiras posições no ranking. Um dos modelos de IA, o sistema avançado de raciocínio, ficou perto do final da lista. Mas quando o avaliador de IA entrou em cena, o quadro se inverteu. Os dois planos escritos pela IA subiram para o topo do ranking, e todos os planos dos dermatologistas ficaram abaixo deles. Em média, o avaliador de IA pontuou os planos gerados por IA mais alto do que os gerados por humanos, mesmo lendo exatamente o mesmo texto padronizado que os dermatologistas haviam visto.
Diferentes ideias sobre o que faz um "bom" plano
Como os planos foram normalizados quanto à redação e os avaliadores estavam cegos quanto à origem, os autores argumentam que essa divisão não pode ser explicada por polimento superficial. Em vez disso, sugere que humanos e sistemas de IA trazem padrões internos diferentes para a avaliação. Clínicos provavelmente se apoiam na experiência do mundo real: o que tende a ser viável em suas clínicas, como os pacientes reagem e quais concessões parecem aceitáveis na prática. Em contraste, um avaliador de IA treinado em grandes coleções de texto pode favorecer planos que seguem padrões comuns na literatura médica ou em diretrizes, mesmo que esses padrões não capturem totalmente restrições locais ou preferências dos pacientes. O estudo é modesto em escala — apenas dez clínicos, cinco casos e um único avaliador de IA — e mede qualidade percebida, não desfechos reais dos pacientes. Ainda assim, a inversão é suficientemente marcante para levantar questões mais profundas sobre como avaliamos a IA clínica.
Repensando como testamos e usamos IA clínica
Com base nesses achados, os autores extraem duas lições gerais. Primeiro, testes tradicionais de “resposta certa” para IA médica deixam de capturar grande parte do que importa no atendimento real, onde planos precisam conciliar eficácia, segurança, custo, logística e desejos dos pacientes. Eles defendem estruturas de avaliação mais ricas e multimetrias que pontuem explicitamente essas dimensões, usem múltiplos avaliadores humanos e de IA e analisem onde e por que surgem discordâncias, em vez de colapsar tudo em uma única nota. Segundo, sugerem que diferenças entre julgamentos humanos e de IA podem ser uma característica, não apenas um defeito. Se usadas com cuidado, propostas geradas por IA podem servir como uma segunda opinião reflexiva que leva os médicos a revisitar suas suposições, enquanto os médicos fornecem o contexto do mundo real e o julgamento ético que a IA não possui. Construir interfaces confiáveis e transparentes que exponham pressupostos, permitam aos clínicos ajustar prioridades e convidem à revisão crítica pode ajudar a transformar essa tensão entre perspectivas humana e de IA em decisões mais seguras e equilibradas.
Citação: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Palavras-chave: suporte à decisão clínica, inteligência artificial na medicina, colaboração humano-IA, planejamento de tratamento, viés de avaliação