Clear Sky Science · pt
Um modelo híbrido de previsão da concentração de PM2.5 baseado em IMF de alta e baixa frequência com decomposição EMD
Por que previsões de ar mais limpo importam na vida cotidiana
Partículas finas no ar, conhecidas como PM2.5, são pequenas o suficiente para penetrar profundamente nos pulmões e até entrar na corrente sanguínea. No Norte da China, onde a indústria pesada e o aquecimento de inverno se concentram, essas partículas frequentemente atingem níveis que podem gerar avisos sanitários, interromper o transporte e até forçar o fechamento de fábricas e escolas. Este estudo pergunta algo muito prático: podemos prever, hora a hora, os níveis de PM2.5 com mais precisão, para que cidades e moradores recebam avisos mais cedo e mais confiáveis antes que a qualidade do ar se torne perigosa?
Um olhar mais atento sobre o ar poluído do Norte da China
Os pesquisadores focaram em seis grandes cidades do Norte da China: Pequim, Tianjin, Shijiazhuang, Taiyuan, Jinan e Zhengzhou. Essas cidades representam áreas densamente povoadas e industrializadas onde episódios de poluição são frequentes, especialmente no inverno. Usando dados oficiais de monitoramento, a equipe coletou leituras horárias de PM2.5 ao longo de todo o ano de 2021, resultando em 8.760 pontos de dados para cada cidade. Eles descobriram que os níveis de poluição variaram amplamente entre as cidades; por exemplo, Taiyuan teve a maior média de PM2.5, enquanto Pequim apresentou a menor. Eventos extremos foram marcantes: em Taiyuan, as concentrações dispararam para 652 microgramas por metro cúbico durante um episódio de poeira e poluição em março, empurrando o índice de qualidade do ar para o nível máximo, sinal claro de ar seriamente poluído.
Por que prever PM2.5 é tão difícil
Os níveis de PM2.5 são influenciados simultaneamente por muitas forças — emissões locais de tráfego e fábricas, transporte regional de poeira e fumaça, velocidade do vento, umidade e mais. Como resultado, o registro de poluição se comporta menos como uma curva suave e mais como um batimento cardíaco irregular. Ferramentas estatísticas tradicionais ou mesmo redes neurais modernas podem ter dificuldade com esse tipo de dado: elas podem captar a tendência geral, mas perder disparos súbitos, ou podem funcionar bem em uma cidade e falhar em outra. Estudos anteriores tentaram melhorar previsões adicionando mais detalhes físicos (como modelos de transporte químico) ou confiando exclusivamente em métodos sofisticados de aprendizado de máquina. Este artigo, em vez disso, combina vários métodos, cada um escolhido para lidar com um “ritmo” diferente nos dados.
Dividindo o sinal em ritmos rápidos e lentos
O passo chave é uma técnica chamada decomposição modal empírica, que divide a série temporal original de PM2.5 em vários componentes mais simples. Alguns desses componentes oscilam rapidamente e capturam picos de curto prazo e ruído; outros mudam lentamente e refletem a tendência subjacente. Os autores agrupam os primeiros cinco componentes como partes de “alta frequência” e os restantes, além de um resíduo de tendência, como partes de “baixa frequência”. As parcelas de alta frequência, que são mais irregulares e fortemente não lineares, são alimentadas em uma rede LSTM (long short-term memory), um tipo de modelo de aprendizado profundo bem adequado para aprender padrões ao longo do tempo. Os componentes mais suaves e de baixa frequência são encaminhados a um método clássico de séries temporais conhecido como ARIMA, eficaz quando os dados se comportam de forma mais regular e quase linear.
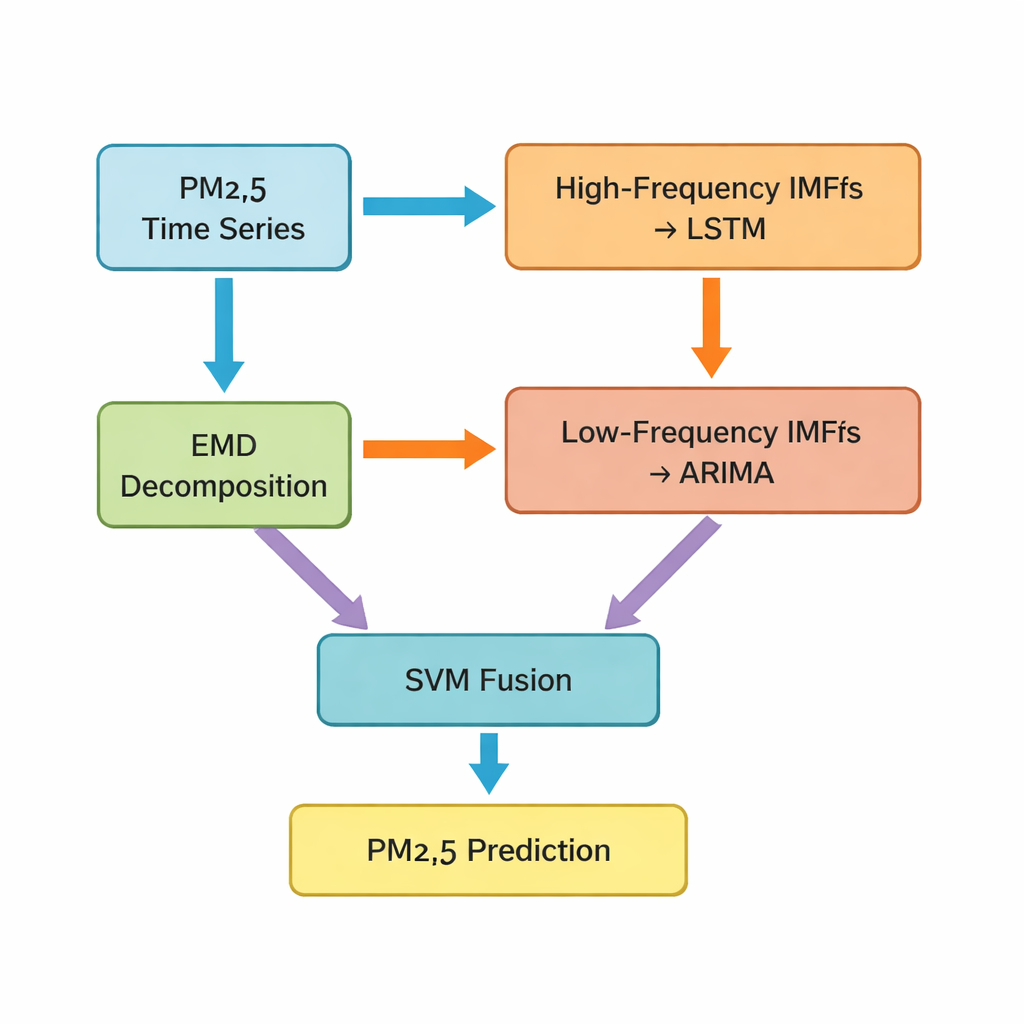
Combinando diferentes modelos em uma previsão mais inteligente
Após os modelos LSTM e ARIMA gerarem suas previsões parciais, o estudo ainda enfrenta um desafio: como fundir essas previsões separadas em um único valor final de PM2.5 para a próxima hora. Para isso, os autores usam uma máquina de vetores de suporte (SVM), outro método de aprendizado de máquina que aprende a ponderar e combinar as duas entradas. Em essência, a SVM atua como um árbitro, decidindo quando a visão “rápida” do mundo (padrões de alta frequência) importa mais e quando a visão “lenta” (tendências de longo prazo) deve dominar. O sistema combinado, que os autores chamam de Hybrid‑EMDHL, é então avaliado usando vários indicadores de desempenho, incluindo erro médio, quão próximas as previsões estão dos valores observados e quão bem o modelo acerta a direção da mudança — se os níveis vão subir ou cair.
Avisos mais claros e melhor planejamento
O modelo híbrido supera cada um de seus componentes principais usados isoladamente em todas as seis cidades. Ele não apenas reduz erros médios e quadráticos, mas também melhora consideravelmente a capacidade de antecipar corretamente se o PM2.5 vai subir ou cair na próxima hora — uma característica crítica para emitir avisos de saúde em tempo hábil. Em muitos casos, a abordagem híbrida corta as medidas de erro pela metade ou mais em comparação com um único modelo de rede neural, e sua “precisão de direção” excede 0,69, o que significa que em muito mais de dois terços dos casos de teste ele prevê corretamente a tendência. Para um leigo, isso significa previsões de qualidade do ar no estilo meteorológico que são mais nítidas e confiáveis. Para planejadores urbanos e autoridades de saúde, oferece uma ferramenta prática para apoiar ações direcionadas e antecipadas — como ajuste de operações industriais ou controle de tráfego — antes que um episódio de poluição atinja o pico, ajudando a reduzir a exposição e proteger a vida diária em algumas das regiões urbanas mais poluídas da China.
Citação: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
Palavras-chave: previsão de PM2.5, poluição do ar, Norte da China, aprendizado de máquina, decomposição de séries temporais