Clear Sky Science · pt
QPSODRL: uma otimização por enxame de partículas quânticas aprimorada e protocolo inteligente de clusterização e roteamento baseado em aprendizagem por reforço profundo para redes de sensores sem fio
Redes de Sensores Mais Inteligentes para um Mundo Conectado
Da agricultura de precisão a sistemas de alerta para desastres, redes de sensores sem fio monitoram discretamente nosso mundo, coletando dados de centenas ou milhares de pequenos dispositivos espalhados por grandes áreas. Sua maior fraqueza é também sua característica definidora: cada sensor funciona com uma pequena bateria que é difícil ou impossível de substituir. Este artigo apresenta uma nova maneira de organizar e direcionar o fluxo de dados nessas redes para que as baterias durem mais, a informação viaje com mais confiabilidade e a rede se adapte quando as condições mudam.
Por Que Dispositivos Pequenos Precisam de Grande Inteligência
Em uma rede de sensores sem fio, cada nó pode detectar, computar e comunicar, mas energia é um recurso precioso. Se alguns nós fizerem trabalho demais, eles morrem cedo, criando “zonas mortas” onde nenhum dado pode ser coletado. Para evitar isso, os projetistas normalmente agrupam os nós em clusters. Dentro de cada cluster, um nó se torna o cabeçalho do cluster: ele reúne leituras dos vizinhos e as encaminha em direção a uma estação base central. Escolher quais nós devem ser cabeçalhos e como os dados devem saltar pela rede é um quebra-cabeça complexo que muda conforme as baterias se esgotam. Soluções tradicionais baseadas em regras ou em um único algoritmo frequentemente convergem cedo para padrões subótimos ou falham quando a forma da rede e os níveis de energia evoluem ao longo do tempo.
Misturando Enxames Inspirados em Quantum com Máquinas de Aprendizado
Este estudo introduz o QPSODRL, um protocolo que combina duas ideias poderosas: um método de enxame inspirado em mecânica quântica para formar clusters e um motor de aprendizagem por reforço profundo para roteamento. Na primeira etapa, “partículas” virtuais exploram diferentes maneiras de atribuir cabeçalhos e membros aos clusters. O comportamento delas é guiado por uma medida de quão uniformemente a energia está distribuída pela rede, conhecida como entropia. Quando o uso de energia está desequilibrado, o algoritmo incentiva uma ampla exploração de novas configurações de cluster; quando as coisas parecem estáveis, ele aperfeiçoa arranjos promissores. Uma etapa especial de “perturbação de elite” ocasionalmente empurra os melhores candidatos em novas direções, ajudando a busca a escapar de becos sem saída locais e evitar o uso excessivo dos mesmos nós de alta energia. 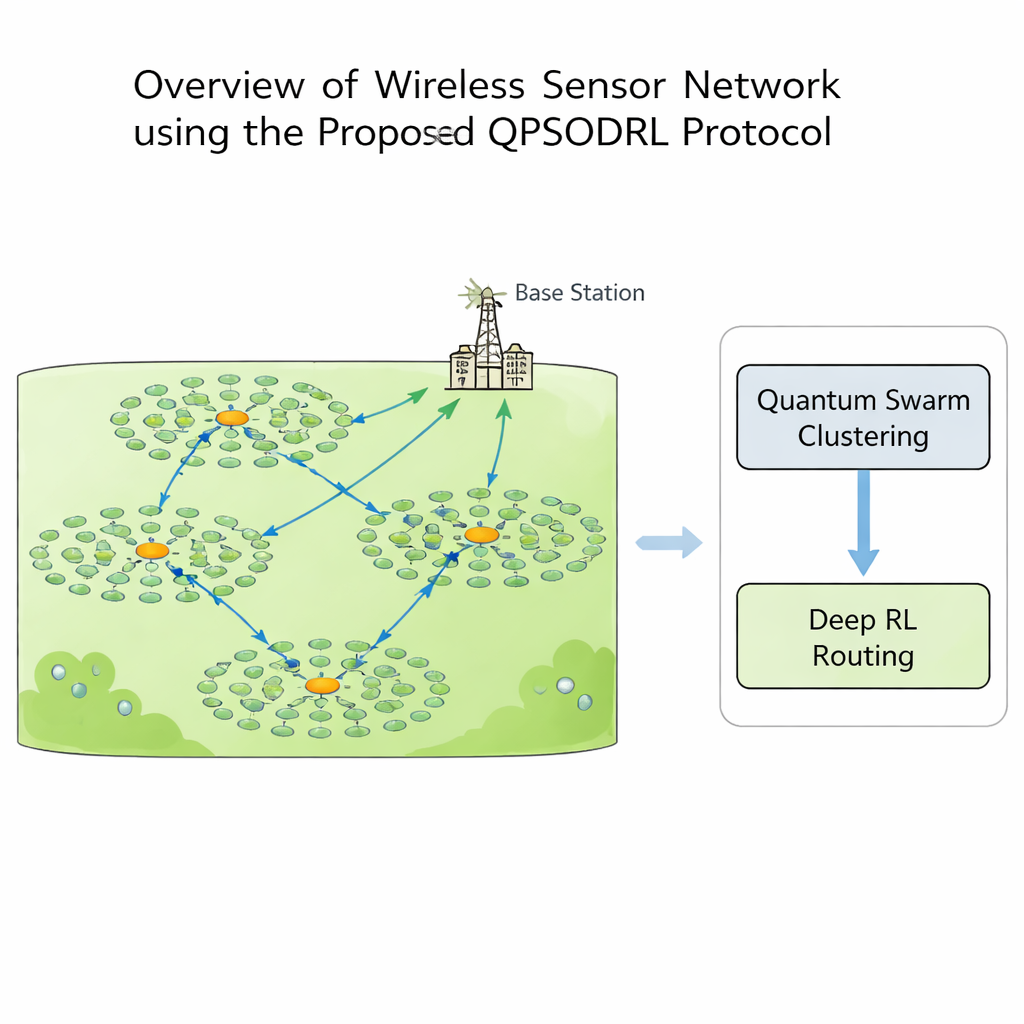
Ensinando a Rede a Aprender Rotas Melhores
Uma vez formados os clusters, a segunda etapa decide como cada cabeçalho de cluster deve enviar seus dados para a estação base. Em vez de seguir rotas fixas, o QPSODRL trata cada cabeçalho como um agente em um processo de aprendizagem. A cada passo, o agente observa sua própria energia restante, a energia e a distância dos cabeçalhos vizinhos e atrasos estimados, então escolhe o próximo salto. Uma forma especializada de Q‑learning profundo, chamada Dueling Double Deep Q‑Network, estima quão boa cada escolha é a longo prazo. Os autores adicionam um termo de “entropia” para desencorajar o sistema de ficar confiante demais muito rapidamente, de modo que ele continue explorando rotas alternativas. Eles também projetam um mecanismo aprimorado de replay de experiência que deliberadamente foca o aprendizado nas situações mais informativas — como quando a energia está baixa ou os atrasos aumentam — de modo que o modelo melhore mais rápido nos cenários que mais importam. 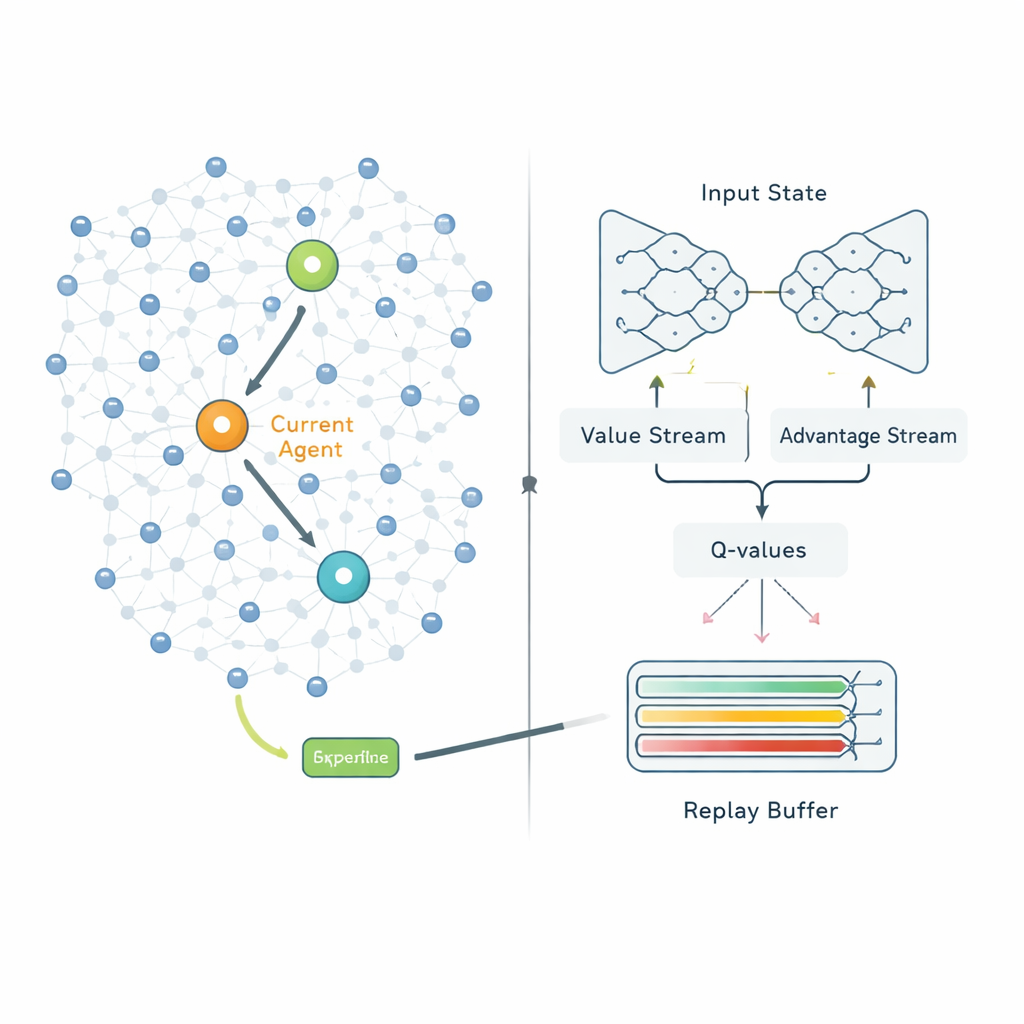
Colocando a Abordagem à Prova
Para avaliar o desempenho do QPSODRL, o autor executa simulações de computador detalhadas de redes com 100 e 200 nós distribuídos por áreas de tamanhos diferentes e com diferentes frações de nós atuando como cabeçalhos de cluster. O novo protocolo é comparado com quatro concorrentes recentes e avançados que usam enxames de partículas, otimização por baleia, lógica fuzzy ou outros esquemas híbridos e baseados em aprendizado. Em todas as configurações testadas, o QPSODRL mantém a rede viva por mais rodadas de comunicação, entrega mais pacotes de dados à estação base e consome menos energia total. Também distribui a carga de trabalho entre os cabeçalhos de cluster de forma mais uniforme, conforme mostrado por uma menor variação na quantidade de tráfego que cada cabeçalho maneja. Esses ganhos são especialmente pronunciados em layouts mais desafiadores, nos quais a estação base está posicionada na borda do campo, forçando saltos mais longos para alguns nós.
O Que Isso Significa para Sistemas do Mundo Real
Para não especialistas, a mensagem-chave é que dar às redes de sensores a capacidade de otimizar globalmente sua estrutura e aprender localmente com a experiência pode estender significativamente sua vida útil. A clusterização inspirada em quantum do QPSODRL mantém o uso de energia equilibrado, enquanto seu roteamento baseado em aprendizado profundo se adapta às condições mutáveis sem ajuste humano constante. Embora os resultados sejam baseados em simulações com nós fixos e sem mobilidade, eles sugerem que futuras implantações de sensores — de cidades inteligentes a observatórios ambientais — poderiam operar por mais tempo, falhar menos e fazer uso mais eficiente da limitada energia das baterias adotando estratégias de controle inteligente semelhantes.
Citação: Guangjie, L. QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks. Sci Rep 16, 5526 (2026). https://doi.org/10.1038/s41598-026-35365-0
Palavras-chave: redes de sensores sem fio, roteamento energeticamente eficiente, aprendizagem por reforço profundo, otimização por enxame, clusterização de rede