Clear Sky Science · pt
Uma abordagem multimodal para reconhecer notícias falsas e nós influentes em sua propagação usando aprendizado profundo e análise de redes
Por que isso importa no dia a dia
Todos os dias, milhões de pessoas percorrem redes sociais, vendo publicações sobre saúde, política, dinheiro e mais. Misturados com informações úteis estão rumores e notícias falsas que podem provocar medo, confusão ou até danos no mundo real. Este estudo apresenta uma maneira poderosa de fazer duas coisas ao mesmo tempo: primeiro, identificar automaticamente postagens falsas ou enganosas; segundo, mapear quem é mais responsável por espalhá‑las dentro de uma comunidade online. O trabalho foca em mensagens do Twitter sobre Covid‑19, mas as ideias podem ajudar plataformas, jornalistas e o público a responder mais rapidamente e com mais precisão à desinformação prejudicial em várias áreas da vida.
Como rumores se espalham por multidões online
Redes sociais como Twitter, Facebook ou aplicativos de mensagens podem ser vistas como enormes teias de pessoas (nós) conectadas por suas interações (ligações). Quando um usuário publica uma mensagem e outros respondem ou compartilham, essa informação pode se propagar rapidamente pela rede. Rumores — alegações não verificadas ou falsas — comportam‑se de modo semelhante a doenças contagiosas: podem pular de pessoa para pessoa, crescer rapidamente e ser difíceis de conter. Pesquisas anteriores frequentemente trataram duas questões separadamente: como identificar se uma determinada postagem é um rumor e como encontrar os “propagadores”-chave que ajudam esse rumor a alcançar muitos outros. Os autores defendem que abordar ambas as questões em conjunto, prestando também atenção à configuração da rede e às mudanças de atividade ao longo do tempo, oferece uma imagem muito mais clara de como histórias falsas se movem.
Ensinar um computador a ler e sinalizar publicações duvidosas
A primeira parte do método foca no conteúdo de cada tweet. Os pesquisadores tratam cada tweet como um documento curto e o limpam removendo ruído como símbolos extras, substituindo links e endereços de e‑mail por tags simples e eliminando palavras de enchimento que pouco acrescentam ao significado. Em seguida, eles traduzem cada palavra em um vetor numérico usando uma técnica amplamente empregada chamada GloVe, que captura como as palavras tendem a aparecer juntas em grandes coleções de texto. Ao fazer a média desses vetores de palavras, cada tweet torna‑se um resumo numérico compacto de seu significado. Esses resumos são então alimentados em uma rede neural convolucional unidimensional — um tipo de modelo de aprendizado profundo que pode detectar padrões sutis — para decidir se um tweet é genuíno ou um rumor.
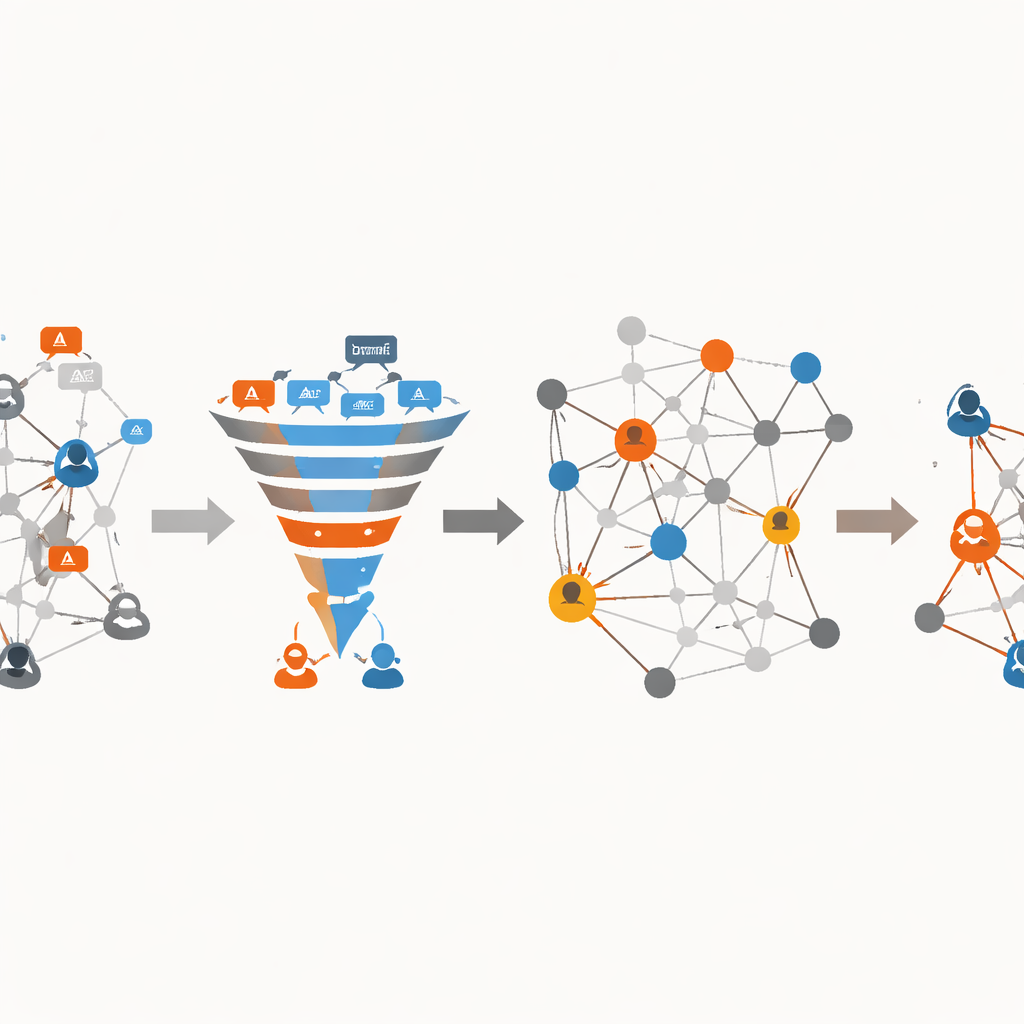
Encontrando os propagadores-chave dentro da rede
Depois que o sistema separa tweets de rumor dos reais, a segunda parte da abordagem volta-se para a estrutura da própria rede social. Cada usuário é um ponto em um grafo direcionado e ponderado, e cada resposta ou retweet vira uma ligação cuja força reflete com que frequência um usuário reage às mensagens de outro. Usando essa informação, os autores primeiro agrupam usuários em comunidades — conjuntos que interagem mais entre si do que com estranhos — construindo uma representação em árvore especial da rede e então mesclando subgrupos fortemente conectados com base em quão bem eles se encaixam. Dentro dessas comunidades, eles calculam com que frequência cada usuário aparece nos caminhos mais importantes entre outros, uma medida conhecida como intermediação (betweenness). Usuários que surgem repetidamente em caminhos de alto valor são tratados como propagadores influentes. Os pesos das conexões são então atualizados para refletir tanto a frequência de interação quanto a centralidade dos usuários conectados, revelando as rotas mais prováveis que os rumores seguem pela rede ao longo do tempo.
O que o estudo de caso sobre Covid‑19 revelou
Para testar sua estrutura, os pesquisadores a aplicaram a um enorme conjunto de dados do Twitter sobre Covid‑19: quase 100 milhões de tweets envolvendo mais de 150.000 usuários, dos quais extraíram mais de 14.000 mensagens únicas rotuladas como informação autêntica ou rumores. Nesse conjunto, o modelo de aprendizado profundo classificou corretamente cerca de 99% dos tweets, superando vários métodos existentes, incluindo outros detectores avançados de notícias falsas. Na segunda etapa, eles compararam sua lista de usuários influentes com um modelo matemático bem conhecido de como a informação se propaga, encontrando o maior grau de concordância entre os métodos testados. Também mostraram que, quando analisaram períodos de tempo mais longos — 120, 240 e depois 360 dias — a capacidade do modelo de identificar propagadores-chave e as principais rotas de rumores melhorou, e o fez com menor tempo de processamento do que técnicas concorrentes baseadas em redes.
O que isso significa para o combate à desinformação
Em termos simples, o estudo mostra que é possível construir um sistema que não apenas identifica notícias provavelmente falsas com altíssima precisão, mas também traça como elas circulam e quem é mais responsável por sua disseminação. Em vez de tratar todos os usuários e conexões como iguais, o método destaca um conjunto menor de comunidades e indivíduos cujo comportamento importa mais para controlar histórias prejudiciais. Embora o trabalho tenha sido feito com dados anonimados do Twitter sobre Covid‑19 e possa não se generalizar diretamente a todas as plataformas ou temas, ele sugere um caminho para respostas mais direcionadas e orientadas por dados a boatos online — como direcionar checagens de fatos, alertas ou intervenções da plataforma onde possam ter maior impacto, ao mesmo tempo em que se preserva a privacidade individual e o uso ético.
Citação: Zhang, W., Qian, M. & Zhang, Q. A multi-modal approach for recognizing fake news and influential nodes in spreading them using deep learning and network analysis. Sci Rep 16, 9775 (2026). https://doi.org/10.1038/s41598-026-35342-7
Palavras-chave: notícias falsas, redes sociais, propagação de boatos, aprendizado profundo, usuários influentes