Clear Sky Science · pt
Integração de conhecimento para regressão simbólica informada por física usando grandes modelos de linguagem pré-treinados
Ensinando Computadores a Adivinhar as Fórmulas da Natureza
Muitas das grandes ideias da ciência estão capturadas em equações concisas: desde como uma bola cai até como ondas de luz se propagam pelo espaço. Este artigo explora uma nova forma de ajudar computadores a redescobrir automaticamente essas equações a partir de dados brutos, permitindo que consultem um grande modelo de linguagem — o mesmo tipo de IA que alimenta chatbots modernos — para que suas suposições não sejam apenas precisas, mas também fisicamente plausíveis.
De Dados Brutos a Leis Legíveis por Humanos
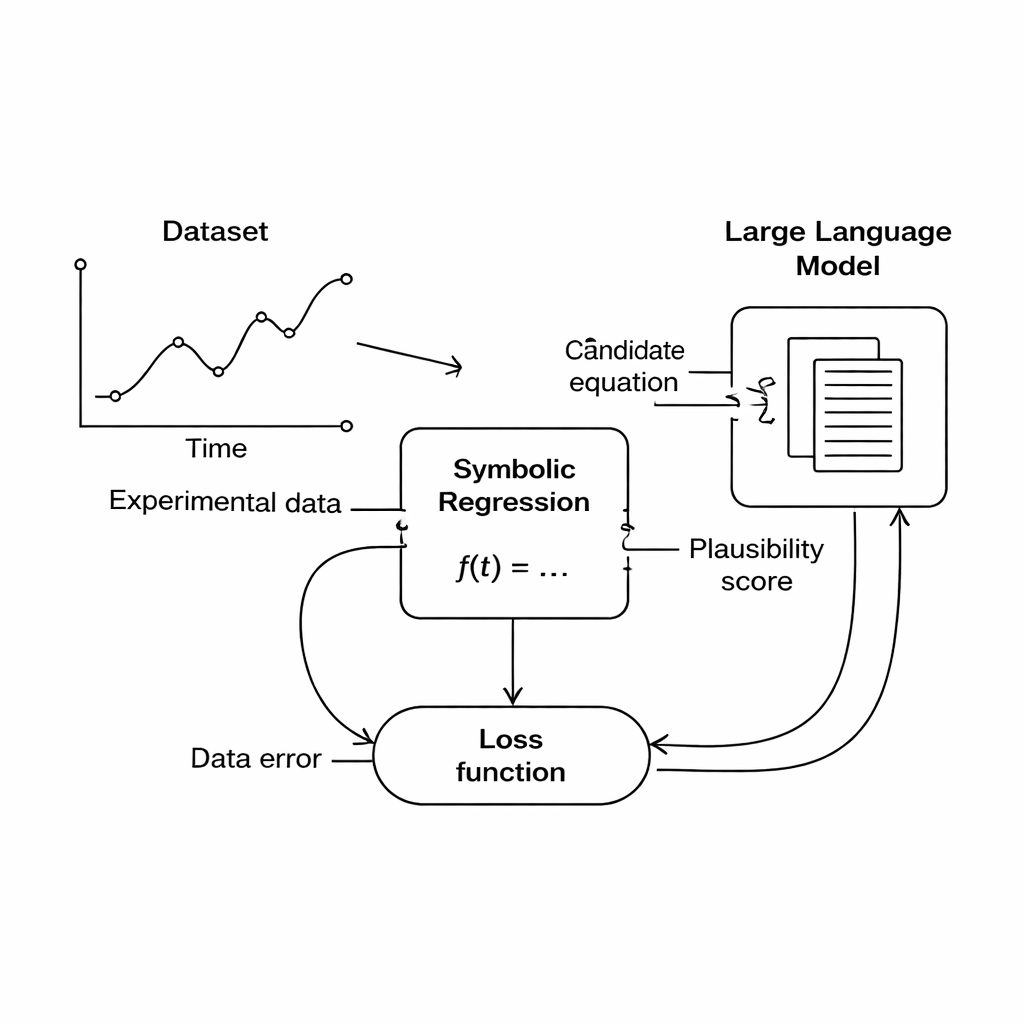
Os autores se concentram em uma técnica chamada regressão simbólica, que procura uma fórmula matemática que relacione entradas e saídas medidas. Diferente do ajuste de curva comum, a regressão simbólica não parte de uma forma de fórmula fixa; em vez disso, ela constrói e evolui equações candidatas até que uma se ajuste bem aos dados. Isso a torna uma ferramenta promissora para a descoberta científica, pois pode potencialmente revelar novas relações que ninguém havia escrito antes. Ainda assim, há um porém: uma fórmula que se ajusta perfeitamente aos dados pode continuar sendo sem sentido do ponto de vista físico — por exemplo, somar uma distância a um tempo ou produzir unidades que não correspondem a nenhuma grandeza real.
Por Que a Intuição Física Ainda Importa
Para evitar esse tipo de absurdo, pesquisadores desenvolveram versões “informadas por física” da regressão simbólica que incorporam regras conhecidas da natureza na busca. Esses métodos recompensam equações que, por exemplo, conservam energia ou respeitam consistência dimensional. No entanto, codificar esse conhecimento tem tipicamente exigido especialistas para criar restrições e funções de perda especiais para cada novo problema. Isso torna a abordagem poderosa, mas difícil de generalizar. Cada novo sistema físico pode exigir um trabalho de projeto cuidadoso, limitando a acessibilidade dessas ferramentas a não especialistas.
Deixando Modelos de Linguagem Avaliarem as Equações
Este estudo propõe um caminho diferente: em vez de codificar rigidamente as regras do domínio, usar um grande modelo de linguagem (LLM) como um avaliador flexível da plausibilidade científica. Durante a busca, o mecanismo de regressão simbólica produz equações candidatas que se ajustam aos dados em certo grau. Cada equação é então traduzida em texto e enviada ao LLM, junto com um curto prompt descrevendo as grandezas envolvidas e quaisquer restrições físicas conhecidas. O LLM retorna pontuações para três aspectos: se as unidades da equação fazem sentido, quão simples ela é e se parece fisicamente realista. Essas pontuações são incorporadas na função objetivo principal, de modo que o computador passa a equilibrar “ajusta-se aos dados” com “parece boa física” ao escolher quais equações continuar refinando.
Colocando o Método à Prova
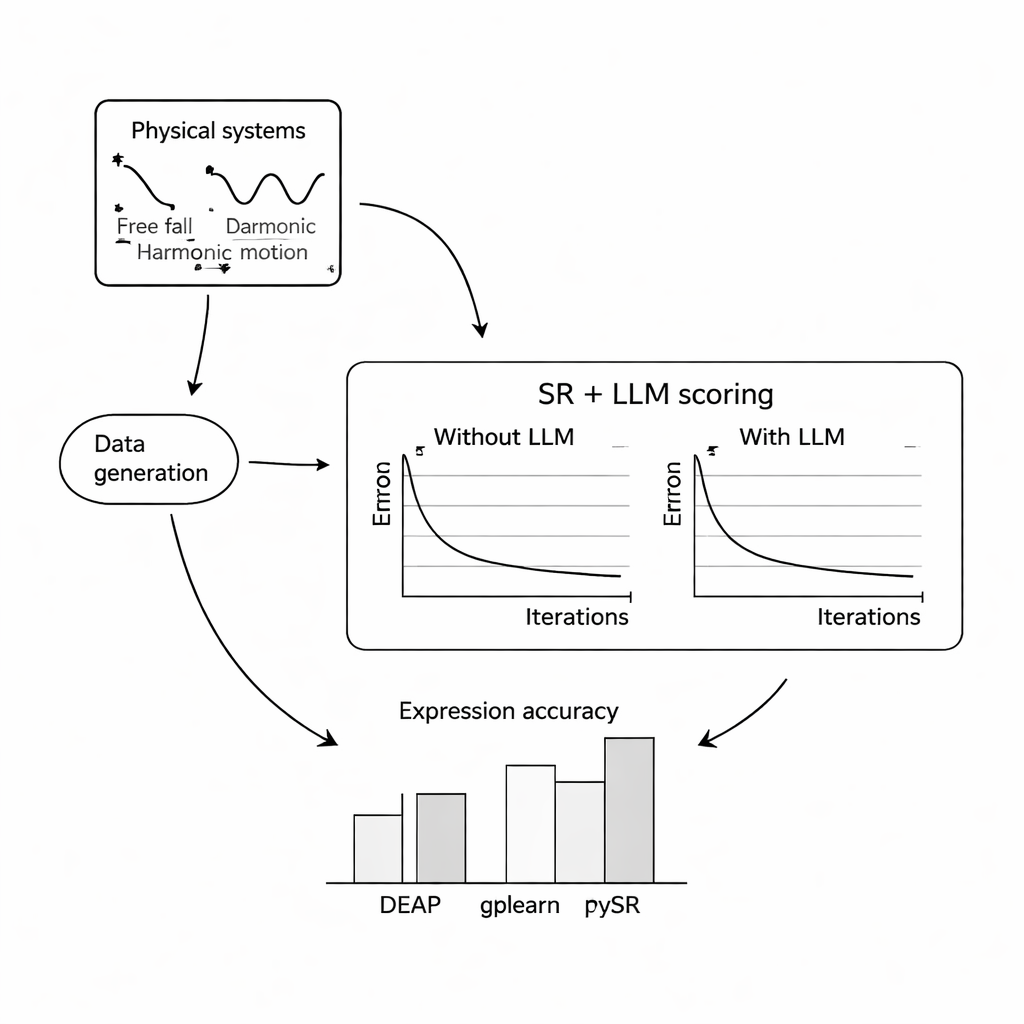
Para avaliar o desempenho, os autores realizaram experimentos computacionais extensivos em três problemas clássicos: a queda livre de uma bola na gravidade terrestre, o movimento harmônico simples de uma massa em uma mola e uma onda eletromagnética amortecida. Para cada sistema, eles simularam milhares de medições ruidosas sob condições variadas e pediram a três programas populares de regressão simbólica que recuperassem as equações subjacentes, com ou sem auxílio de um LLM. Testaram três modelos de linguagem compactos e de código aberto — Mistral, Llama 2 e Falcon — e exploraram como diferentes designs de prompt, desde contexto mínimo até descrições completas e até a fórmula verdadeira, alteravam a orientação do LLM. Na maioria das configurações, adicionar a pontuação do LLM melhorou o quão próximas as equações recuperadas estavam das leis conhecidas e as tornou mais robustas ao ruído, com a combinação do PySR (uma biblioteca de regressão simbólica) e Mistral geralmente apresentando o melhor desempenho.
Quando Palavras Guiam a Matemática
Uma descoberta-chave é que a redação do prompt afeta fortemente os resultados. Quando os prompts incluíam descrições claras das variáveis, da natureza do experimento e, às vezes, a fórmula alvo exata, a busca guiada pelo LLM convergia de forma mais confiável para a estrutura correta. Nesses casos mais ricos, as equações descobertas frequentemente eram estruturalmente idênticas às leis verdadeiras, não apenas próximas numericamente. Os autores também testaram como a abordagem se comporta com níveis crescentes de ruído aleatório nas medições. Embora todos os métodos se degradassem à medida que os dados se tornavam mais ruidosos e as equações subjacentes mais complexas, as versões aumentadas por LLM tendiam a perder precisão mais lentamente que suas contrapartes padrão, sugerindo que o senso de plausibilidade do modelo de linguagem pode atuar como uma influência estabilizadora.
O Que Isso Significa para Descobertas Futuras
Para leitores em geral, a mensagem principal é que IAs baseadas em texto podem fazer mais do que escrever ensaios ou responder perguntas — elas também podem guiar outros algoritmos em direção a equações científicas que “parecem corretas” conforme nosso conhecimento existente da natureza. O método apresentado aqui não garante que toda equação descoberta esteja correta, e ainda depende de supervisão humana e de prompts cuidadosamente elaborados. Mas demonstra que grandes modelos de linguagem, treinados em oceanos de texto científico, podem servir como uma fonte reutilizável de conhecimento de domínio, ajudando ferramentas automatizadas a evoluir de ajustar dados às cegas para propor leis que cientistas podem interpretar, verificar e desenvolver.
Citação: Taskin, B., Xie, W. & Lazebnik, T. Knowledge integration for physics-informed symbolic regression using pre-trained large language models. Sci Rep 16, 1614 (2026). https://doi.org/10.1038/s41598-026-35327-6
Palavras-chave: regressão simbólica, IA informada por física, grandes modelos de linguagem, descoberta científica, aprendizado de equações