Clear Sky Science · pt
Uma abordagem de aprendizado por reforço profundo para análise de movimentos de dança
Ensinando Computadores a Assistir à Dança Como Nós
Do balé ao hip-hop, a dança é repleta de sutis mudanças de ritmo e pose que os olhos humanos captam instantaneamente — mas que os computadores têm dificuldade em perceber. Este estudo apresenta uma nova forma de fazer a inteligência artificial “assistir” a vídeos de dança mais como um especialista humano, passando por passos rotineiros para focar em breves momentos reveladores que definem cada estilo. O resultado é um sistema que reconhece gêneros de dança com mais precisão enquanto assiste a muito menos vídeo, um potencial avanço para tudo, desde arquivos digitais até tecnologia esportiva e de entretenimento.
Por Que Vídeos de Dança São Difíceis para Máquinas
À primeira vista, treinar um computador para reconhecer estilos de dança parece simples: alimentar com vídeos e deixar o aprendizado profundo encontrar padrões. Na prática, a maioria dos sistemas existentes desperdiça esforço. Modelos de vídeo padrão ou processam cada quadro ou amostram clipes em intervalos fixos, assumindo que todos os momentos são igualmente importantes. Mas os estilos de dança frequentemente se diferenciam por detalhes minúsculos — como o giro do pé, quando um parceiro pivota ou o tempo de uma pirueta — em vez de um movimento constante. Isso significa que muitos quadros são repetitivos ou pouco informativos, e poses-chave podem cair entre pontos de amostragem fixos, levando a confusões entre, por exemplo, Valsa e Foxtrote.
Uma Maneira Mais Inteligente de Percorrer o Vídeo
Os pesquisadores propõem uma estrutura chamada Amostragem Temporal Atenta com Base em Reforço, ou RATS, que trata a análise de vídeo como uma busca ativa em vez de uma visualização passiva. Em vez de avançar quadro a quadro, o sistema divide um vídeo de dança em curtos clipes e primeiro converte cada clipe em uma descrição compacta do movimento usando uma rede convolucional 3D especializada. Esses resumos de movimento são então armazenados em memória. Sobre isso, um agente de tomada de decisão percorre a sequência de clipes, escolhendo se avança por um pequeno salto, um salto maior ou se para e emite uma predição de estilo. Na prática, o sistema aprende a navegar no tempo, demorando-se em padrões reveladores e pulando trechos menos úteis.
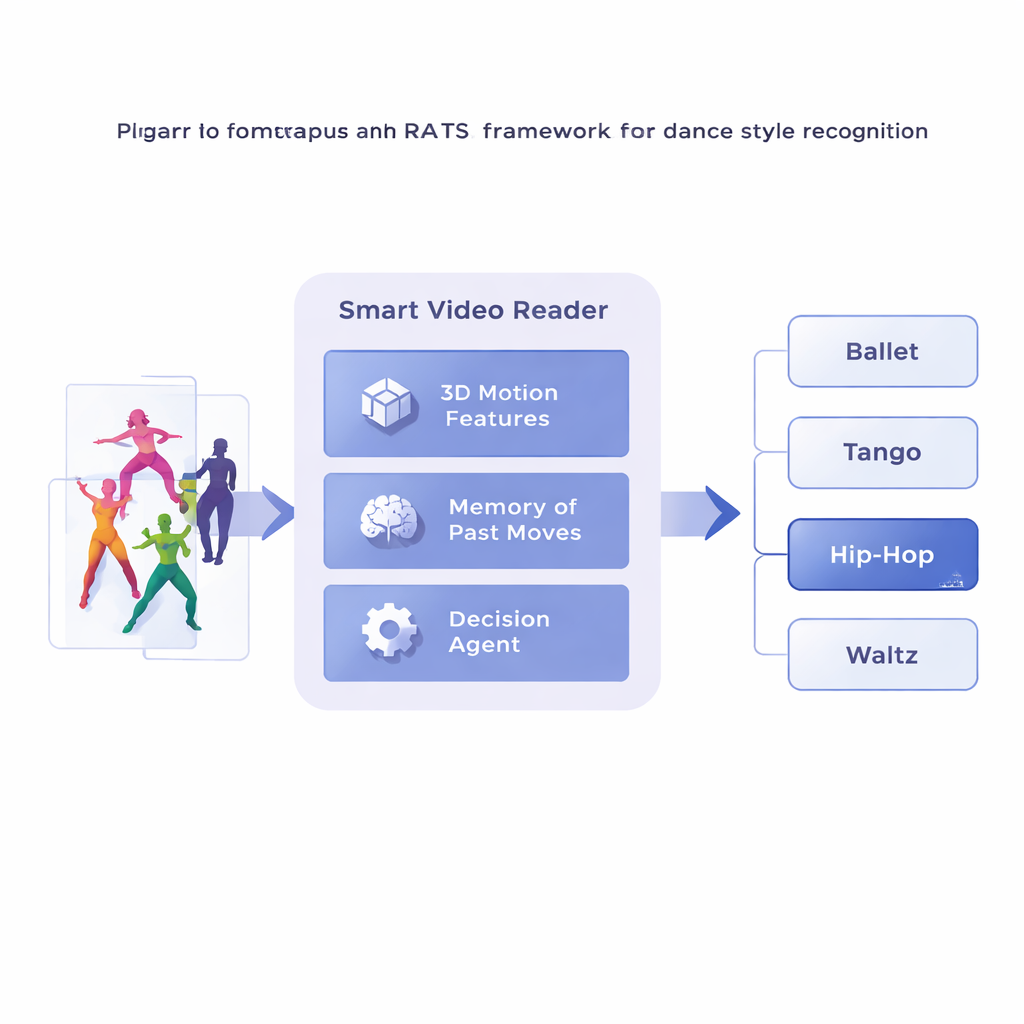
Aprender Quando Olhar e Quando Decidir
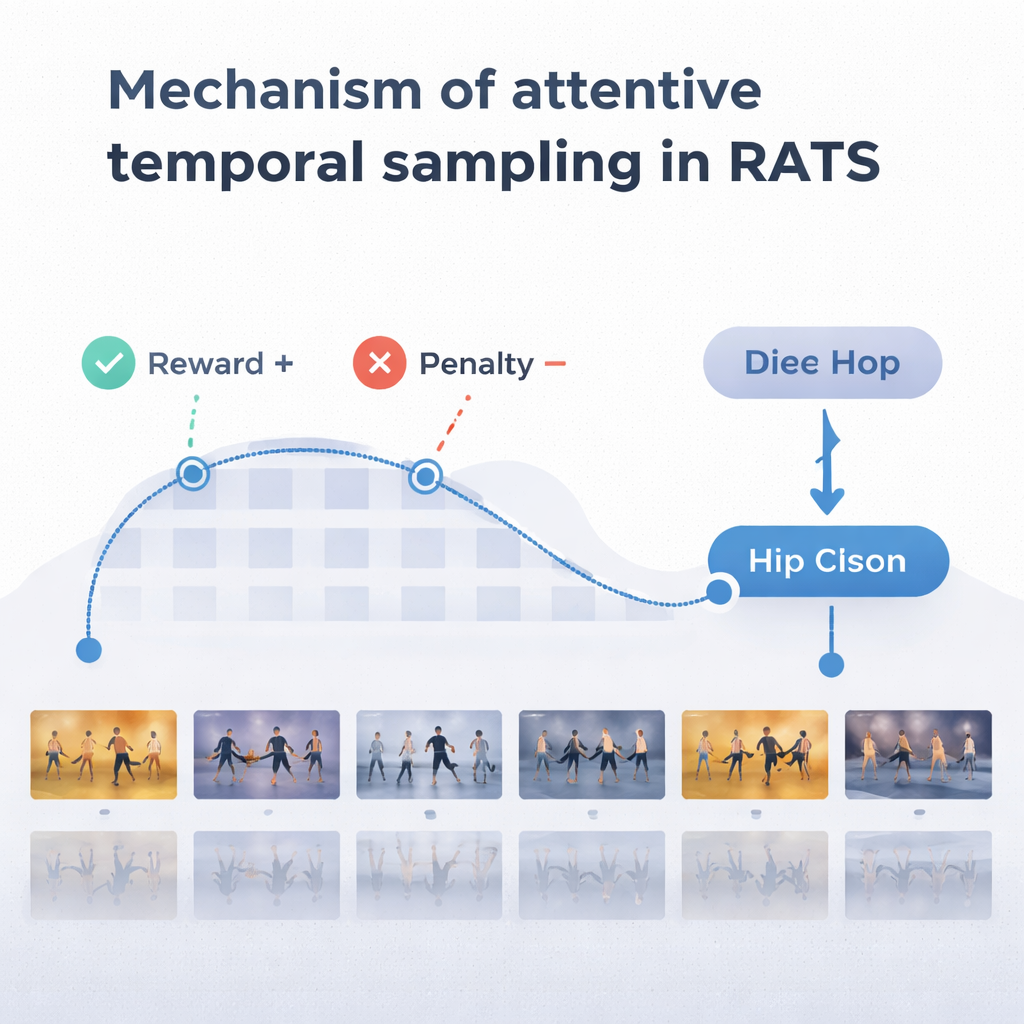
Para tomar decisões sensatas, o agente se apoia em uma forma de memória inspirada em como lembramos tanto o movimento passado quanto o emergente. Uma rede recorrente bidirecional monitora o que o sistema já “viu” e como os clipes atuais se relacionam com esse histórico. A cada passo, o agente avalia três opções: dar um pequeno salto para inspecionar detalhes finos, como o trabalho de pés; pular mais adiante sobre movimentos repetitivos; ou parar e classificar a dança. O sistema é treinado com recompensas e penalidades: ganha uma grande pontuação positiva por uma decisão correta, uma grande pontuação negativa por uma errada e uma pequena penalidade cada vez que avança. Esse equilíbrio incentiva o agente a ser preciso e eficiente — esperar até ter evidências suficientes, mas sem vasculhar o vídeo inteiro.
Superando Classificadores Convencionais de Dança
A equipe testou o RATS no conjunto de dados Let’s Dance, uma coleção desafiadora de 1.000 vídeos cobrindo dez estilos, do Flamenco e Tango ao Swing e Square dance. Em comparação com vários métodos existentes, incluindo redes profundas padrão e outros modelos focados em dança, o RATS alcançou a maior acurácia — cerca de 92% — e o melhor equilíbrio geral entre precisão e recall. Também se mostrou estatisticamente superior a concorrentes fortes, não apenas ligeiramente diferente por acaso. Importante, o sistema obteve esses resultados enquanto, em média, analisava apenas cerca de 38% dos quadros do vídeo. Amostrar uniformemente a cada poucos quadros foi mais rápido, mas perdeu momentos cruciais e reduziu o desempenho; processar todos os quadros foi mais lento e ainda menos preciso do que a abordagem direcionada.
O Que Isso Significa Além da Pista de Dança
Para um não especialista, a mensagem central é direta: os computadores podem ser melhores quando aprendem a ser espectadores seletivos. Ao ensinar uma IA a se concentrar em “momentos de ouro” no tempo, este trabalho mostra que as máquinas podem reconhecer movimentos humanos complexos com mais precisão enquanto usam menos recursos. Embora o estudo enfoque a dança, a mesma ideia pode ajudar sistemas a identificar elementos-chave em rotinas esportivas, filmagens de segurança ou qualquer vídeo longo onde eventos importantes são breves e dispersos. Em outras palavras, assistir de forma mais inteligente — não mais — pode ser o futuro da compreensão de vídeo.
Citação: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
Palavras-chave: reconhecimento de dança, análise de vídeo, aprendizado profundo, aprendizado por reforço, movimento humano