Clear Sky Science · pt
Modelo chinês de extração de relações espaciais integrando recursos semânticos geográficos
Ensinando computadores a entender onde ficam os lugares
Cada dia descrevemos locais com frases simples: uma cidade fica ao sul de um rio, um parque está perto de uma universidade, uma rodovia atravessa uma província. Converter esse tipo de linguagem cotidiana em conhecimento digital preciso é essencial para mapas inteligentes, apps de navegação e pesquisas geográficas. Este artigo apresenta um novo método, chamado PURE‑CHS‑Attn, que ajuda computadores a ler textos em chinês e identificar automaticamente as relações espaciais entre lugares com maior precisão do que antes.
Por que a linguagem espacial importa
Relações espaciais são palavras e expressões que nos dizem como lugares estão conectados no espaço, como “dentro de”, “ao lado de”, “ao norte de” ou “a 30 quilômetros de”. Elas formam uma ponte entre o mundo real que vemos nos mapas e os conceitos que usamos mentalmente. Em sistemas de informação geográfica (SIG), essas relações sustentam a forma como os dados são organizados, buscados e analisados. Também são centrais em outros campos: por exemplo, combinar imagens de satélite, rastrear movimento em vídeo, planejar arranjos industriais ou estudar como clima e relevo influenciam a biodiversidade. Como grande parte dessa informação está escrita em linguagem natural, dispor de ferramentas confiáveis que leiam textos e extraiam relações espaciais automaticamente torna‑se cada vez mais importante.
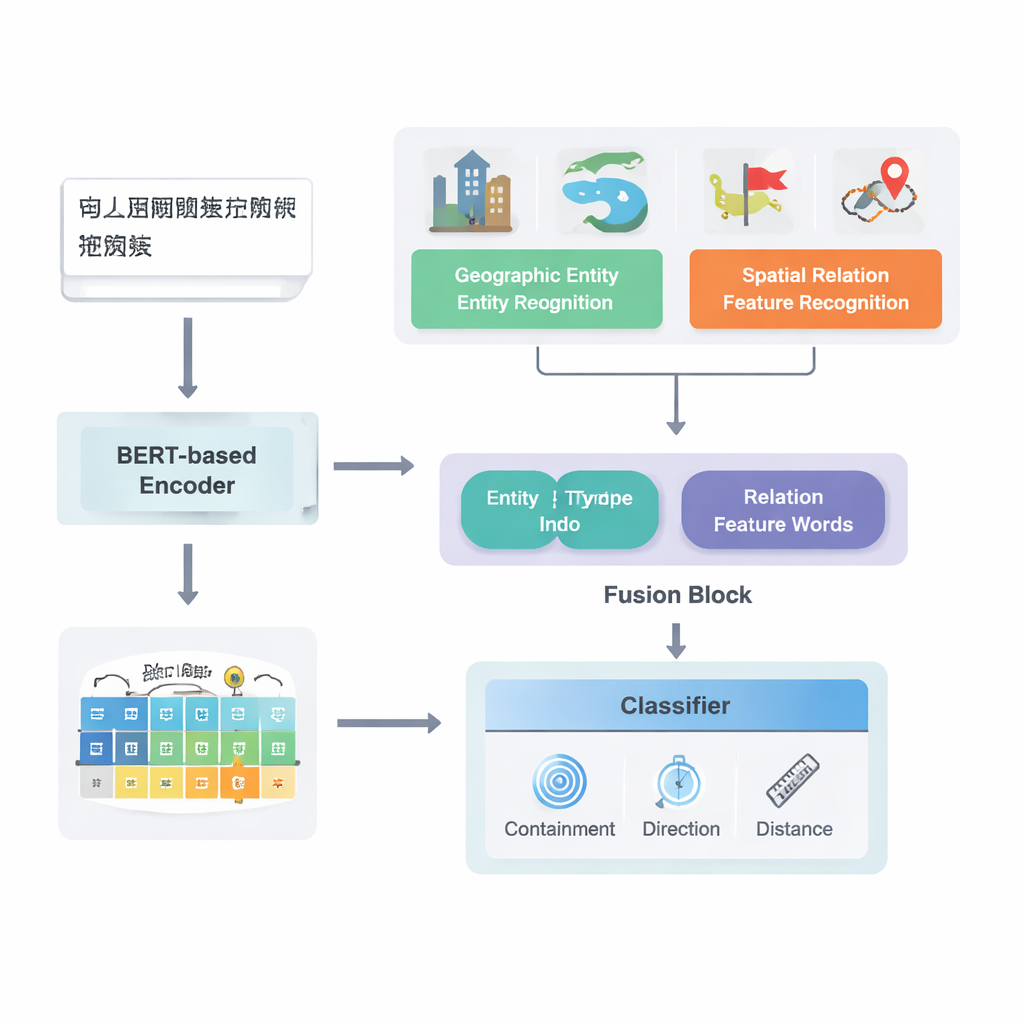
Do texto bruto às relações mapeadas
Os autores focam em textos em chinês e constroem sobre um robusto modelo de pipeline de aprendizado profundo existente conhecido como PURE. Seu modelo aprimorado, PURE‑CHS‑Attn, opera em várias etapas. Primeiro, ele escaneia sentenças para localizar entidades geográficas, como montanhas, rios, cidades e regiões administrativas, e rotula cada uma com um tipo (por exemplo, superfície terrestre, corpo d’água, instalação pública, sítio histórico ou divisão administrativa). Em seguida, detecta “palavras‑características” de relações espaciais como “faz fronteira”, “atravessa”, “ao sul de” ou “perto de”, que sinalizam como dois lugares se relacionam. Um poderoso modelo de linguagem, BERT‑wwm‑ext, converte os caracteres de cada sentença em vetores numéricos que capturam seu significado e contexto. Esses vetores alimentam componentes separados que reconhecem entidades e palavras de relação e depois encaminham seus resultados a um módulo de fusão.
Misturando conhecimento humano com aprendizado de máquina
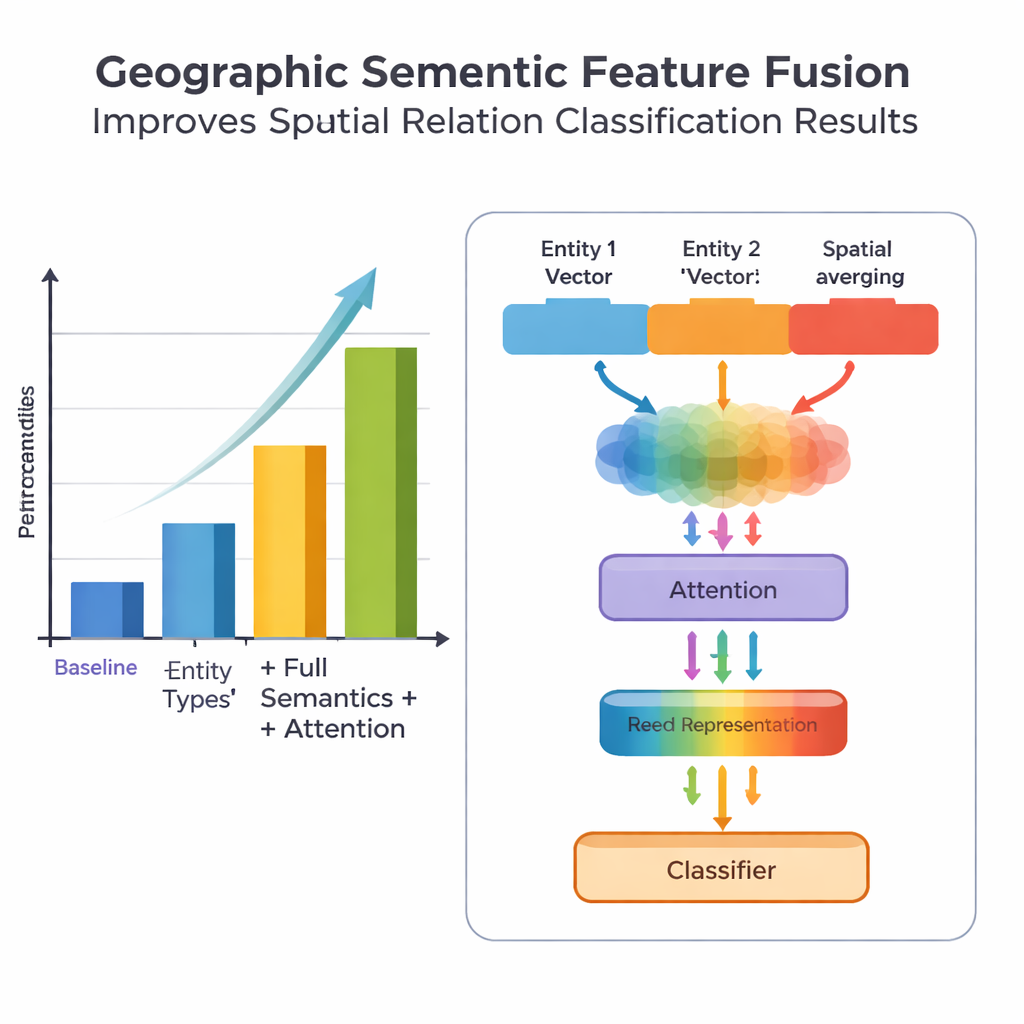
Uma novidade-chave do trabalho está em como ele funde conhecimento geográfico com padrões de texto aprendidos. Em vez de tratar cada palavra igualmente, o modelo explora dois tipos de informação semântica que os humanos usam naturalmente: o tipo de cada entidade geográfica e as palavras‑características espaciais específicas que as conectam. O módulo de fusão primeiro combina os vetores das duas entidades usando pesos que dependem da frequência com que diferentes tipos de lugares (como duas regiões administrativas versus um rio e um condado) participam de distintos tipos de relação. Em seguida, incorpora os vetores das palavras‑características espaciais. Sobre essa “fusão básica”, os autores adicionam um mecanismo de atenção que permite ao modelo focar dinamicamente nas partes mais informativas da combinação entidade–palavra. A representação final fundida é passada a um classificador, que pode atribuir um ou mais tipos de relação — topológica (como contenção ou adjacência), direcional (norte, sul etc.) ou baseada em distância — entre cada par de lugares na sentença.
Colocando o modelo à prova
Para avaliar sua abordagem, a equipe reuniu e anotou cuidadosamente um conjunto de dados extraído da Enciclopédia da China: Geografia Chinesa, contendo 1.381 sentenças e 368 pares de relações espaciais. Compararam várias versões do modelo: um baseline que usa apenas informação de localização grosseira, uma versão com tipos de entidade mais refinados, uma versão que também adiciona palavras‑características espaciais, e seu modelo completo PURE‑CHS‑Attn com o novo desenho de fusão e atenção. Pelas métricas padrão de precisão, recall e F1, o PURE‑CHS‑Attn melhorou o desempenho em cerca de 7% na precisão, 6,5% no recall e 6,7% no F1 em relação ao baseline. Foi especialmente forte no reconhecimento de relações topológicas e direcionais, e lidou melhor com tipos de relação raros de poucas‑amostras do que modelos mais simples. Quando comparado com três sistemas recentes de ponta, incluindo um baseado em grandes modelos de linguagem, o PURE‑CHS‑Attn ficou em um segundo lugar próximo, mantendo‑se muito mais leve e fácil de implantar.
Desafios e direções futuras
Apesar desses ganhos, o modelo ainda tem dificuldades com relações de distância, especialmente quando existem apenas poucos exemplos de treinamento. Os autores mostram que seu conjunto de dados contém muito poucos desses casos, o que limita o que qualquer método dependente de dados pode aprender. Eles também observam que fazer uma média cega de muitas palavras‑características espaciais em uma sentença pode introduzir ruído, problema que o mecanismo de atenção ajuda a mitigar, mas não resolve completamente. Olhando adiante, sugerem dois caminhos promissores: expandir e balancear os dados de treinamento por meio de aumento de dados, e combinar sua fusão semântica geográfica com técnicas de grandes modelos de linguagem e aprendizado baseado em prompts para melhorar ainda mais o desempenho em cenários com poucos dados, mantendo o sistema eficiente.
O que isso significa para o mapeamento do dia a dia
Em termos simples, esta pesquisa ensina os computadores a ler descrições espaciais em chinês de forma mais parecida com os humanos, prestando atenção aos tipos de lugares mencionados e a exatamente como suas relações são formuladas. O modelo PURE‑CHS‑Attn demonstra que misturar conhecimento geográfico estruturado com aprendizado profundo moderno leva a uma extração mais precisa e robusta de “quem está onde, em relação a quê” a partir de textos. Isso abre caminho para sistemas SIG mais inteligentes e automatizados, grafos de conhecimento geográfico mais ricos e melhores ferramentas para explorar como o espaço é descrito na ciência, nas políticas públicas e na comunicação cotidiana.
Citação: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
Palavras-chave: extração de relações espaciais, IA geoespacial, semântica geográfica, mineração de texto em chinês, automação GIS