Clear Sky Science · pt
Abordagem de aprendizado de máquina para identificação de variedades de trigo usando imagem de uma única semente
Por que triagem de sementes mais inteligente importa
Para agricultores e empresas de sementes, distinguir uma variedade de trigo de outra é essencial. Plantar o tipo errado pode significar rendimentos menores, menor resistência a doenças e cultivos inadequados ao solo ou clima local. No entanto, a olho nu, diferentes variedades de trigo parecem quase idênticas. Este estudo explora como inteligência artificial e fotos digitais de sementes individuais podem distinguir de forma confiável variedades intimamente relacionadas, abrindo caminho para um controle de qualidade de sementes mais rápido, barato e objetivo.
Do exame especializado à verificação por câmera
Hoje, muitos sistemas de inspeção de sementes ainda dependem de especialistas humanos que julgam visualmente a variedade e pureza das sementes. Esse processo é lento, caro e sujeito a discordâncias, sobretudo porque muitos cultivares de trigo diferem apenas por mudanças sutis na forma ou no padrão da superfície. Os autores buscaram substituir essa abordagem subjetiva por um sistema automatizado que usa imagens de grãos de trigo individuais feitas em uma pequena caixa com iluminação controlada. Ao padronizar cuidadosamente iluminação, distância e cor de fundo, eles criaram um registro visual limpo de seis variedades comuns iranianas de trigo, gerando dezenas de milhares de fotos de sementes para treinar e testar modelos computacionais.
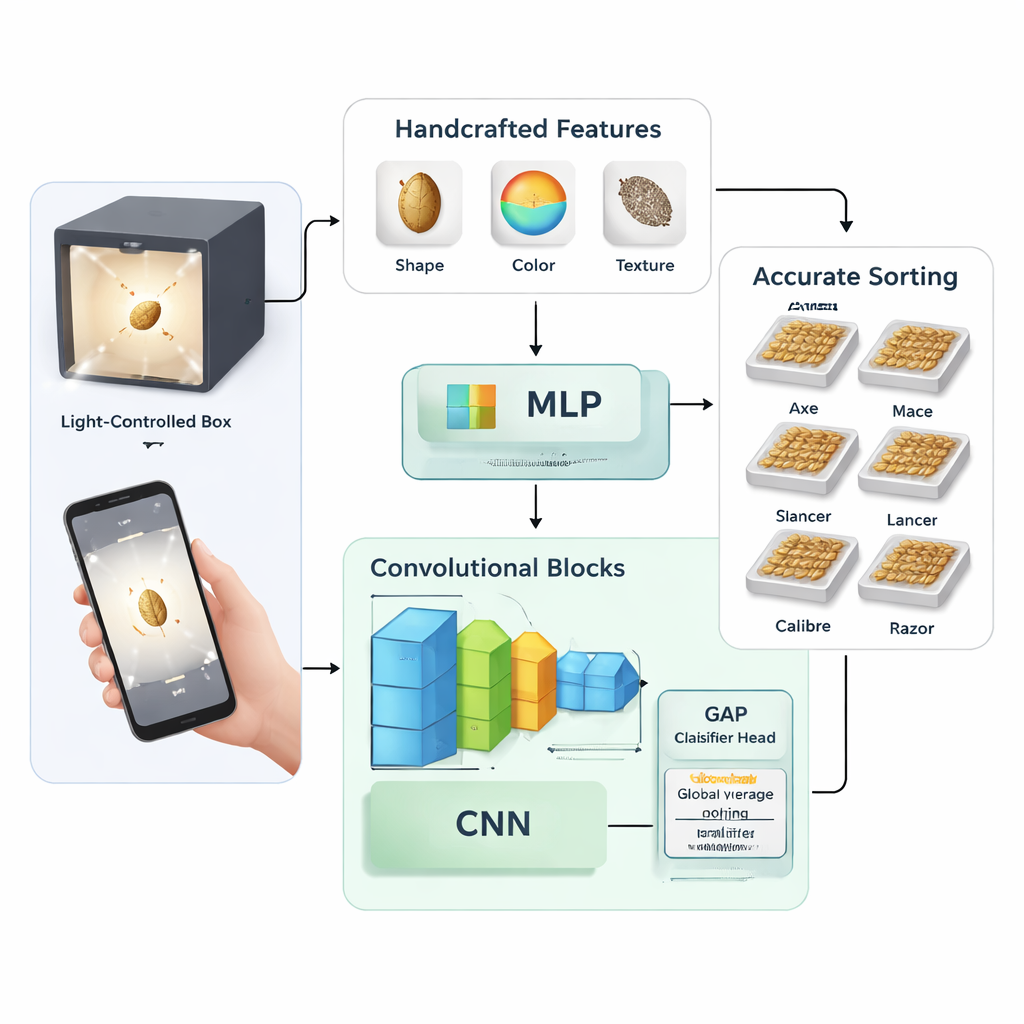
Duas maneiras de ensinar um computador a ver sementes
O estudo compara duas estratégias amplas para ensinar uma máquina a reconhecer variedades de trigo. Na primeira, os pesquisadores extraíram manualmente 58 medidas numéricas de cada imagem de semente, incluindo formas básicas (como comprimento e área), estatísticas de cor em diferentes espaços de cor e padrões de textura. Em seguida, usaram uma técnica chamada análise de componentes principais para condensar essas medidas em 27 características-chave, que foram alimentadas a uma rede neural tradicional chamada perceptron multicamadas. Na segunda estratégia, pularam o desenho manual de características e treinaram redes neurais convolucionais — modelos de IA voltados para imagem — para aprender padrões úteis diretamente dos dados brutos de pixels.
Construindo um modelo de aprendizado profundo enxuto, mas potente
A abordagem de aprendizado profundo foi testada em várias formas. Os autores projetaram sua própria rede relativamente pequena com dois a quatro blocos convolucionais empilhados e experimentaram diferentes configurações de treinamento, como taxas de aprendizado, níveis de dropout e tamanhos de lote. Também compararam duas formas de finalizar a rede: uma clássica camada “totalmente conectada” versus um método mais compacto chamado global average pooling, que substitui grandes camadas densas por uma simples etapa de média antes da classificação final. Para comparação, ajustaram finamente duas arquiteturas pesadas e amplamente usadas — Inception-ResNet-v2 e EfficientNet-B4 — no mesmo conjunto de dados de trigo para ver como um modelo pequeno e sob medida se compara a redes profundas de uso geral.
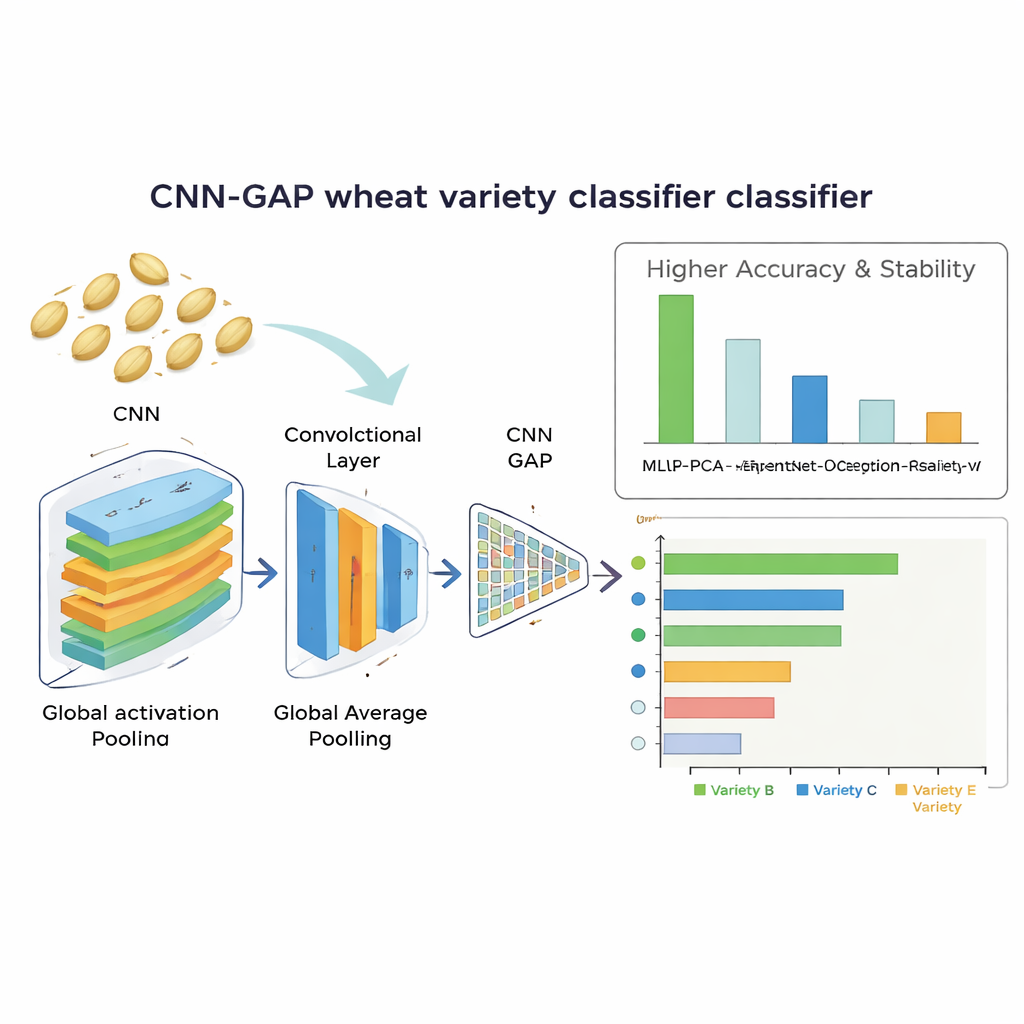
Quão bem o sistema lê o grão
O melhor desempenho foi da rede convolucional construída sob medida usando global average pooling. Ela identificou corretamente as variedades de trigo em cerca de 92% dos casos e apresentou resultados muito estáveis em execuções de treinamento repetidas. Esse modelo não só superou as grandes redes pré-treinadas como também superou a abordagem de características manuais, que alcançou cerca de 86% de acurácia após a redução de dimensionalidade. A análise dos padrões de confusão mostrou que o modelo mais leve teve desempenho especialmente bom ao separar variedades que pareciam muito semelhantes, enquanto os modelos mais profundos com transferência de aprendizado tendiam a sobreajustar o conjunto de dados limitado. Importante, a rede vencedora era eficiente: processava cada imagem de semente em aproximadamente 13,6 milissegundos e continha cerca de 2,1 milhões de parâmetros ajustáveis, tornando-a viável para uso em equipamentos de triagem em tempo real e baixo custo.
Limites, uso no mundo real e próximos passos
Quando o mesmo modelo foi testado em uma cultura totalmente diferente — sementes de grão-de-bico — sua acurácia caiu acentuadamente, revelando que um sistema ajustado para diferenças finas entre grãos de trigo não se generaliza automaticamente para outras espécies. Da mesma forma, como todas as imagens de treinamento vieram de uma câmara cuidadosamente controlada, o desempenho pode diminuir sob iluminação variável em campo ou com grãos parcialmente ocultos. Ainda assim, o trabalho mostra que um modelo de aprendizado profundo compacto e bem projetado, alimentado por imagens padronizadas de sementes individuais, pode distinguir de forma confiável variedades de trigo quase indistinguíveis a olho nu. Com dados de treinamento mais amplos e condições de imagem mais variadas, sistemas similares poderiam se tornar ferramentas práticas para certificação automatizada de sementes, ajudando agricultores a garantir lotes de sementes mais puros e colheitas mais previsíveis.
Citação: Bagherpour, H., Shamohammadi, S. Machine learning approach for wheat variety identification using single-seed imaging. Sci Rep 16, 6472 (2026). https://doi.org/10.1038/s41598-026-35252-8
Palavras-chave: sementes de trigo, aprendizado profundo, classificação baseada em imagem, qualidade de sementes, agricultura de precisão