Clear Sky Science · pt
Primazia do engenharia de características sobre complexidade arquitetural para previsão de demanda intermitente
Por que prever vendas raras importa
Por trás de toda oficina ou armazém de peças há um quebra-cabeça silencioso: quantas peças de reposição de baixa rotatividade devem ficar na prateleira? Esses itens vendem raramente e de forma imprevisível, mas precisam estar disponíveis quando um veículo quebra. Pedir demais prende dinheiro em estoque empoeirado; pedir de menos faz clientes esperarem enquanto as peças são trazidas com pressa. Este artigo aborda esse problema cotidiano, porém oneroso, perguntando algo simples: é melhor usar modelos de previsão cada vez mais complicados ou alimentar modelos existentes com sinais mais inteligentes e cuidadosamente projetados a partir dos dados?
De longos períodos de nada a picos repentinos
Em muitas cadeias de suprimentos, especialmente para peças automotivas, a demanda não é estável como leite ou pão. Em vez disso, há longos períodos de meses com vendas zero, interrompidos por pedidos repentinos de poucas unidades. Os autores analisam mais de 56.000 combinações concessionária–peça, cobrindo cerca de 1,4 milhão de registros mensais, e constatam que a maioria das séries é extremamente esparsa: em média, há muitos meses zerados para cada mês com venda, e o tamanho dos pedidos varia muito. Métodos estatísticos tradicionais, como a abordagem de Croston e suas refinarias, foram desenvolvidos para esse tipo de demanda “ligada–desligada” e fornecem previsões estáveis e interpretáveis, mas tratam cada peça isoladamente e não conseguem usar facilmente informações extras como preços ou atributos do produto. Sistemas modernos de aprendizado de máquina podem, em princípio, usar todas essas informações, mas tendem a ter dificuldades quando os dados são na maior parte zeros e apenas ocasionalmente informativos.
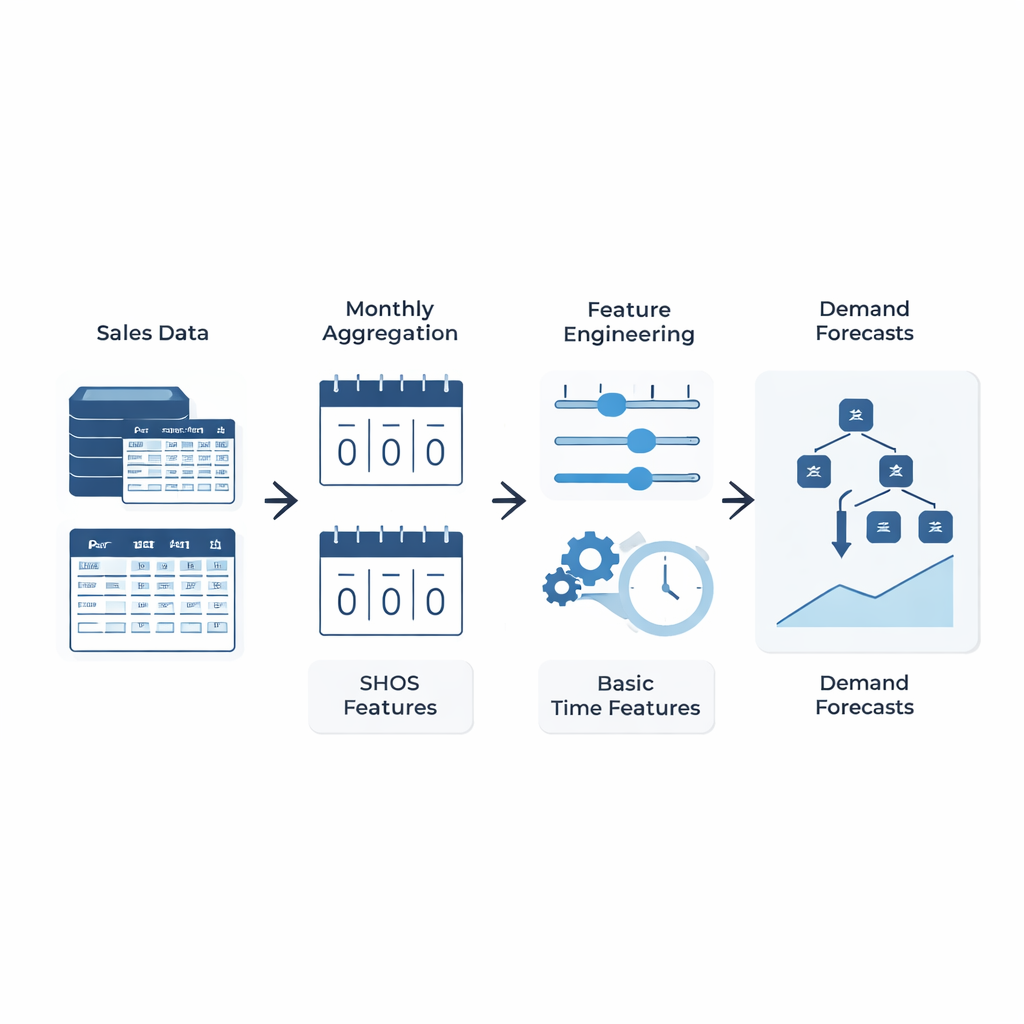
Uma ideia simples: ensinar ao modelo o que realmente importa
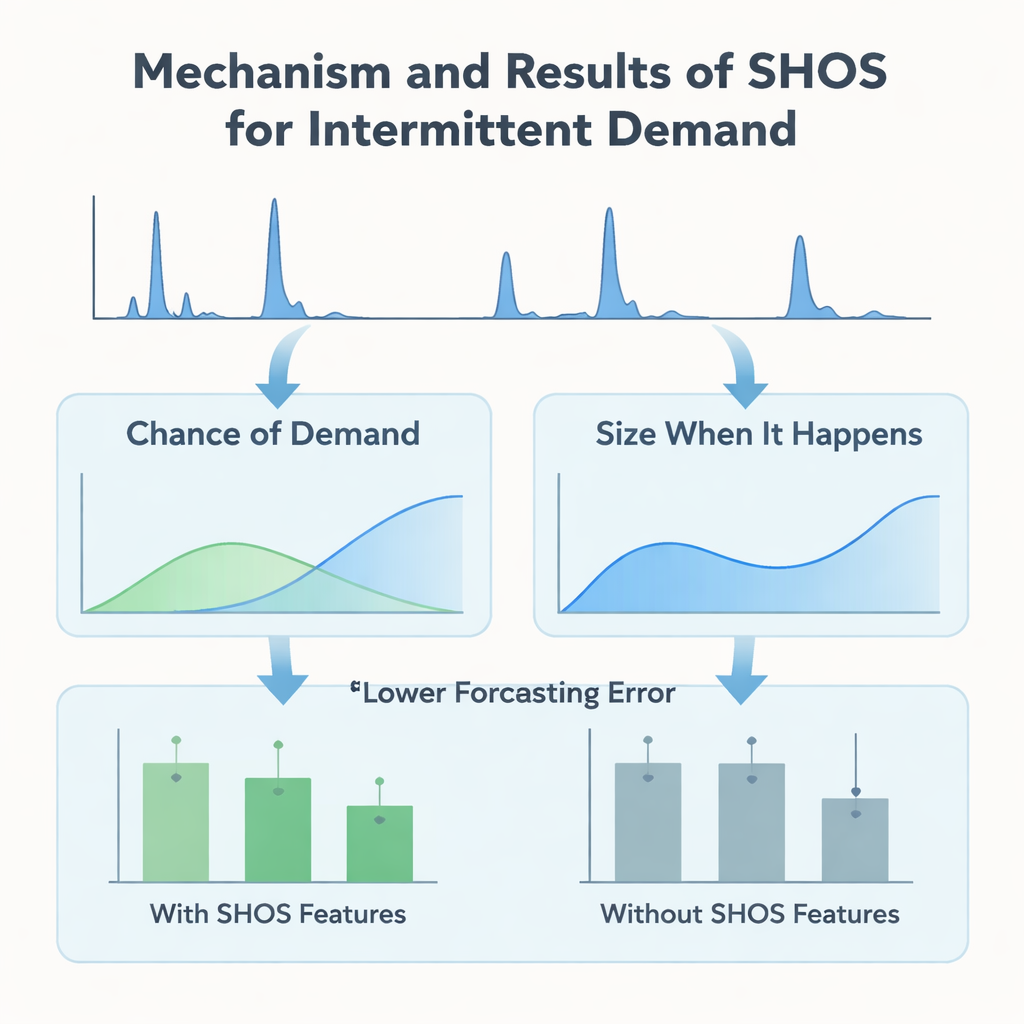
Em vez de projetar arquiteturas de aprendizado de máquina cada vez mais intrincadas, os autores focam no que é alimentado ao modelo. Eles introduzem o framework Smoothed Hybrid Occurrence–Size (SHOS), uma rotina estatística leve que roda sobre cada histórico de demanda. A cada mês, o SHOS produz dois números: a chance estimada de que qualquer demanda ocorra no próximo mês e o tamanho típico dessa demanda caso ocorra. Faz isso suavizando cuidadosamente zeros e não-zeros passados, adaptando seu comportamento para séries muito esparsas e reagindo mais rapidamente quando a demanda retorna de forma abrupta após um longo período de inatividade. Crucialmente, o SHOS não é o modelo de previsão final. Seus outputs tornam-se características extras de entrada para algoritmos padrão de aprendizado de máquina, ao lado de itens simples como vendas recentes, médias móveis e detalhes estáticos do produto.
Priorizar qualidade das características em vez da complexidade do modelo
Para testar se esse “pré-processamento” estatístico realmente ajuda, os pesquisadores constroem um experimento controlado. Eles comparam uma variedade de modelos populares — árvores de gradiente (gradient-boosted), florestas aleatórias e métodos lineares — com e sem as características SHOS, todos treinados no mesmo painel mensal preenchido com zeros e avaliados usando um esquema rigoroso de janelas móveis que imita a implantação real. Eles também testam modelos mais elaborados em duas etapas do tipo “hurdle” que predizem separadamente se a demanda ocorrerá e qual será seu tamanho. Ao longo de 11 janelas de validação, adicionar as características SHOS reduz quase pela metade o erro médio de previsão para itens altamente intermitentes e diminui uma métrica comercial chave, o erro percentual absoluto médio ponderado, em mais de 40%. Surpreendentemente, as arquiteturas em duas etapas, embora mais complexas e adaptadas a esse tipo de dado, não superam um único regressor simples que simplesmente incorpora os sinais do SHOS.
Ver como o modelo faz suas escolhas
A equipe vai além da acurácia de manchete e investiga como os modelos realmente usam a informação que recebem. Usando o SHAP, uma ferramenta padrão para interpretar predições de aprendizado de máquina, mostram que as características baseadas no SHOS — “chance de demanda” e “tamanho quando ocorre” — estão consistentemente entre as entradas mais influentes. Durante longos períodos de demanda zero, uma baixa probabilidade SHOS empurra as previsões para zero, evitando acúmulo espúrio de estoque. Quando um surto de demanda aparece após um período seco, um ajuste de recência no SHOS eleva rapidamente as estimativas de probabilidade e tamanho, permitindo que o modelo responda sem reagir em excesso a um pico isolado. Esses comportamentos são observados tanto no modelo simples de estágio único quanto nas versões hurdle mais complexas, ressaltando que o ganho principal vem da qualidade dos sinais, não de artifícios arquiteturais.
O que isso significa para decisões cotidianas de inventário
Para os profissionais que tentam manter as peças certas na prateleira, a mensagem é prática e reconfortante. O estudo mostra que características cuidadosamente projetadas e fundamentadas estatisticamente podem proporcionar grandes melhorias na previsão de vendas raras e irregulares sem recorrer a conjuntos de modelos frágeis e difíceis de manter. Uma árvore de gradiente modesta e bem ajustada equipada com características SHOS supera ou iguala pipelines mais elaborados, permanecendo mais fácil de implantar e monitorar em dezenas de milhares de itens. Em termos simples, alimentar seu sistema de previsão com resumos melhores sobre com que frequência e quanto os clientes provavelmente irão pedir pode importar mais do que atualizar para o algoritmo mais recente e complexo. Essa ênfase em blocos construtivos simples e interpretáveis torna a abordagem atraente para cadeias de suprimentos em grande escala e sugere que estratégias similares centradas em características podem compensar em outras indústrias que enfrentam demanda intermitente.
Citação: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
Palavras-chave: demanda intermitente, previsão de peças de reposição, engenharia de características, análise da cadeia de suprimentos, aprendizado de máquina