Clear Sky Science · pt
Faster R-CNN adaptativo por domínio para identificação de ausência de EPI em canteiros a partir de imagens corporais e gerais
Por que a falta de equipamentos de segurança ainda passa despercebida
Capacetes, coletes, máscaras, luvas e calçados resistentes deveriam ser inegociáveis em canteiros de obras, mas falhas ainda ocorrem — e podem ser fatais. Muitos projetos atualmente dependem de câmeras e inteligência artificial para sinalizar trabalhadores sem os equipamentos exigidos, mas esses sistemas têm dificuldade porque violações reais são raras e difíceis de captar em vídeo. Este estudo explora uma maneira de treinar detectores mais inteligentes emprestando exemplos de fotos comuns de rua, tornando as checagens automáticas de segurança mais confiáveis sem precisar esperar que acidentes — ou violações — se acumulem.
Transformando fotos do cotidiano em lições de segurança
A ideia central é simples: pessoas em locais públicos ou escritórios raramente usam equipamento de construção, então fotos desses ambientes estão repletas de exemplos de “o que não usar” em um canteiro. O desafio é que essas cenas parecem bem diferentes do trabalho real — fundos, iluminação e ângulos de câmera mudam a aparência das pessoas. O autor trata esses dois mundos como “domínios” distintos: um domínio fonte com muitos exemplos de ausência de EPI em imagens gerais, e um domínio alvo com menos, mas mais realistas, imagens de canteiros — muitas gravadas por câmeras acopladas aos capacetes dos trabalhadores. O artigo mostra que, ao alinhar cuidadosamente o que o computador aprende em ambos os domínios, o sistema consegue detectar a falta de equipamento em locais reais com muito mais precisão do que se fosse treinado apenas com dados de construção.
Como o novo verificador de segurança enxerga uma cena
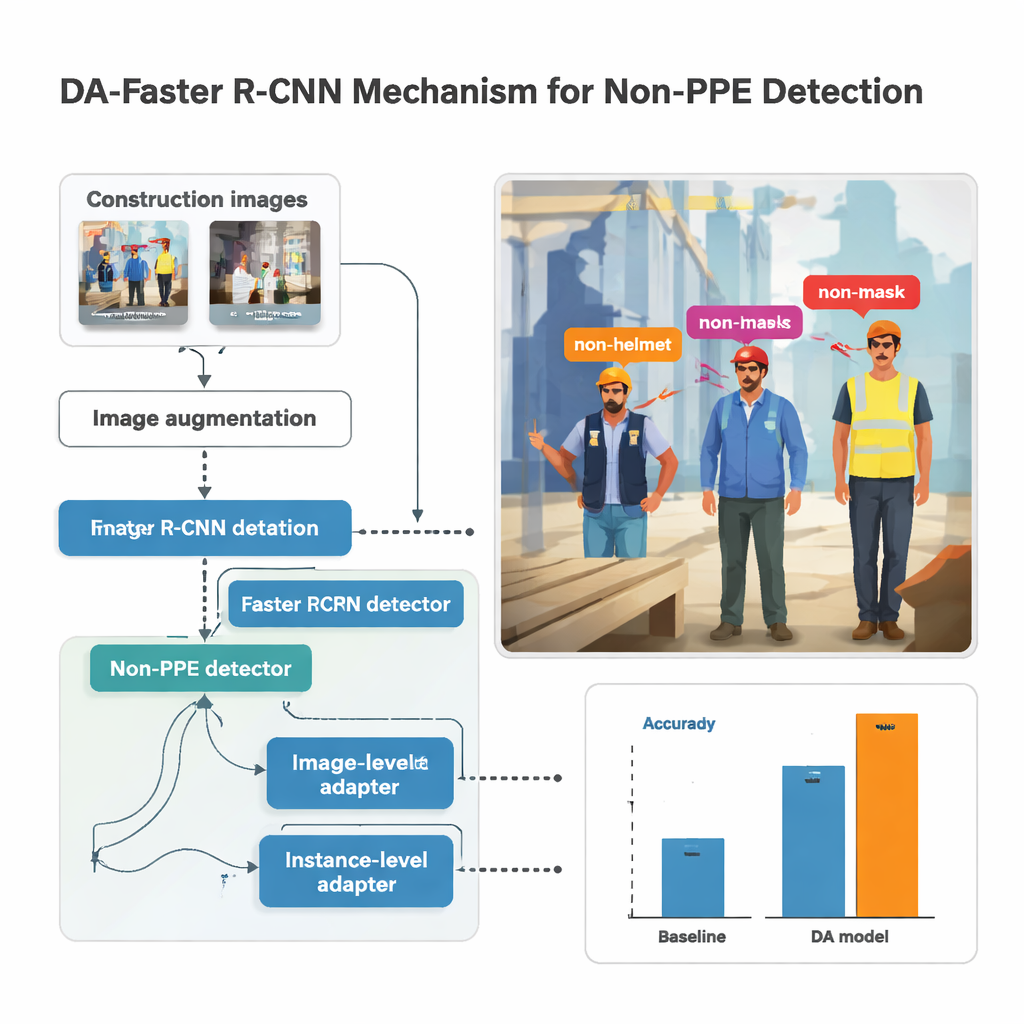
A pesquisa se baseia num sistema popular de detecção de objetos chamado Faster R-CNN, que escaneia uma imagem, propõe regiões prováveis de conter pessoas ou partes do corpo e então classifica o que vê dentro de cada caixa. Aqui, o detector é treinado para reconhecer cinco tipos de ausência de EPI: sem capacete, sem máscara, sem luvas, sem colete e sem calçados de segurança. Antes de as imagens serem fornecidas ao modelo, elas passam por forte aumento de dados — clareadas ou escurecidas, rotacionadas, borradas e distorcidas — para imitar câmeras tremidas, luz solar intensa e ângulos desconfortáveis comuns em canteiros movimentados. Essa variedade sintética ajuda o modelo a se manter estável quando as filmagens do mundo real são imperfeitas, como frequentemente acontece com câmeras corporais.
Ensinando o sistema a ignorar o plano de fundo
Simplesmente misturar fotos de rua com imagens de construção não basta; o modelo pode aprender a associar falta de EPI com calçadas urbanas em vez de com pessoas. Para evitar isso, o estudo introduz módulos de “adaptação de domínio” que direcionam suavemente o sistema para focar nas pessoas e nas roupas em vez da cena ao redor. Um módulo analisa a imagem como um todo, ajustando a rede para que fotos de construção e não construção produzam padrões gerais semelhantes, apesar das diferenças de iluminação ou equipamento. Outro age no nível de cada pessoa detectada, garantindo que a assinatura visual de, por exemplo, uma cabeça desprotegida seja similar tanto num andaime quanto numa rua comercial. Esses módulos são treinados de forma adversarial: um pequeno classificador tenta dizer de qual domínio veio uma imagem, enquanto a rede principal aprende a esconder essa informação, mantendo o foco no equipamento de proteção.
Colocando o método à prova
O autor reuniu um conjunto de dados considerável ao combinar filmagens de câmeras corporais de cinco canteiros na Coreia do Sul com várias coleções públicas de imagens. Após a rotulagem manual de cada ocorrência de faltas de capacete, máscara, luvas, colete e calçados de segurança, o estudo treinou centenas de modelos com diferentes backbones de redes neurais e configurações de parâmetros. O melhor desempenho usou uma rede profunda chamada ResNet‑152 juntamente com aumento de imagem intenso e os módulos de adaptação de domínio. Em imagens de construção não vistas anteriormente, essa configuração alcançou uma média de Precisão Média (mAP) — uma pontuação geral de qualidade de detecção — de cerca de 86,8%, mantendo uma velocidade de aproximadamente 33 quadros por segundo, rápida o suficiente para monitoramento quase em tempo real. Em comparação com sistemas supervisionados mais convencionais, o modelo adaptado melhorou a acurácia em até 14 pontos percentuais, e em até 39 pontos em relação a uma linha de base mais simples.
O que isso significa para canteiros mais seguros
Para não especialistas, a conclusão é que treinos mais inteligentes, não apenas conjuntos de dados maiores, podem tornar a monitoração de segurança automatizada muito mais confiável. Ao aprender tanto com fotos do cotidiano quanto com locais de trabalho reais, e ao ensinar o sistema a ignorar detalhes de fundo irrelevantes, a abordagem proposta identifica capacetes, coletes, luvas, máscaras e calçados de segurança ausentes com alta confiabilidade, mesmo quando violações reais são raras. Embora o trabalho atual foque em cinco tipos de equipamento e num conjunto principal de construção, ele oferece um roteiro prático para sistemas futuros que poderiam rastrear cintos de segurança, cordas e outros equipamentos em vários canteiros, ajudando supervisores a detectar problemas cedo e manter os trabalhadores mais seguros sem precisar vigiar telas de vídeo o dia todo.
Citação: Wang, S. Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images. Sci Rep 16, 4793 (2026). https://doi.org/10.1038/s41598-026-35148-7
Palavras-chave: segurança na construção, equipamento de proteção individual, visão computacional, adaptação de domínio, detecção de objetos