Clear Sky Science · pt
Previsão de proteínas associadas às raízes usando um grande modelo de linguagem de proteínas e redes convolucionais em hipergráfico
Por que as raízes e seus auxiliares ocultos importam
Quando pensamos em manter as lavouras saudáveis, geralmente imaginamos folhas e frutos. Mas grande parte do sucesso de uma planta acontece fora de vista, no solo. Ali, proteínas especiais associadas às raízes ajudam as plantas a absorver água e nutrientes e a lidar com estresses como seca ou solo pobre. Encontrar essas proteínas cruciais apenas com experimentos de laboratório é lento e caro. Este estudo apresenta um modelo computacional poderoso, chamado Hypergraph-Root, que pode escanear rapidamente sequências de proteínas e prever quais têm maior probabilidade de estar associadas às raízes, oferecendo um caminho mais rápido para culturas mais resilientes e colheitas melhores.
Trabalhadores ocultos no solo
As raízes das plantas fazem mais do que ancorar a planta no lugar. Elas constantemente percebem o ambiente, absorvem minerais e se comunicam com micróbios do solo. As proteínas associadas às raízes são centrais em tudo isso, moldando como as raízes crescem, como respondem ao calor, à seca ou à escassez de nutrientes, e como interagem com micróbios benéficos. Como essas proteínas influenciam fortemente rendimento e resiliência, agricultores e melhoristas se interessam por elas mesmo que nunca as vejam diretamente. Ainda assim, muitas dessas proteínas permanecem desconhecidas, em grande parte porque métodos tradicionais — como proteômica e estudos de expressão gênica — exigem instrumentos caros, análises complexas e experimentos demorados.
Transformando sequências de proteínas em pistas
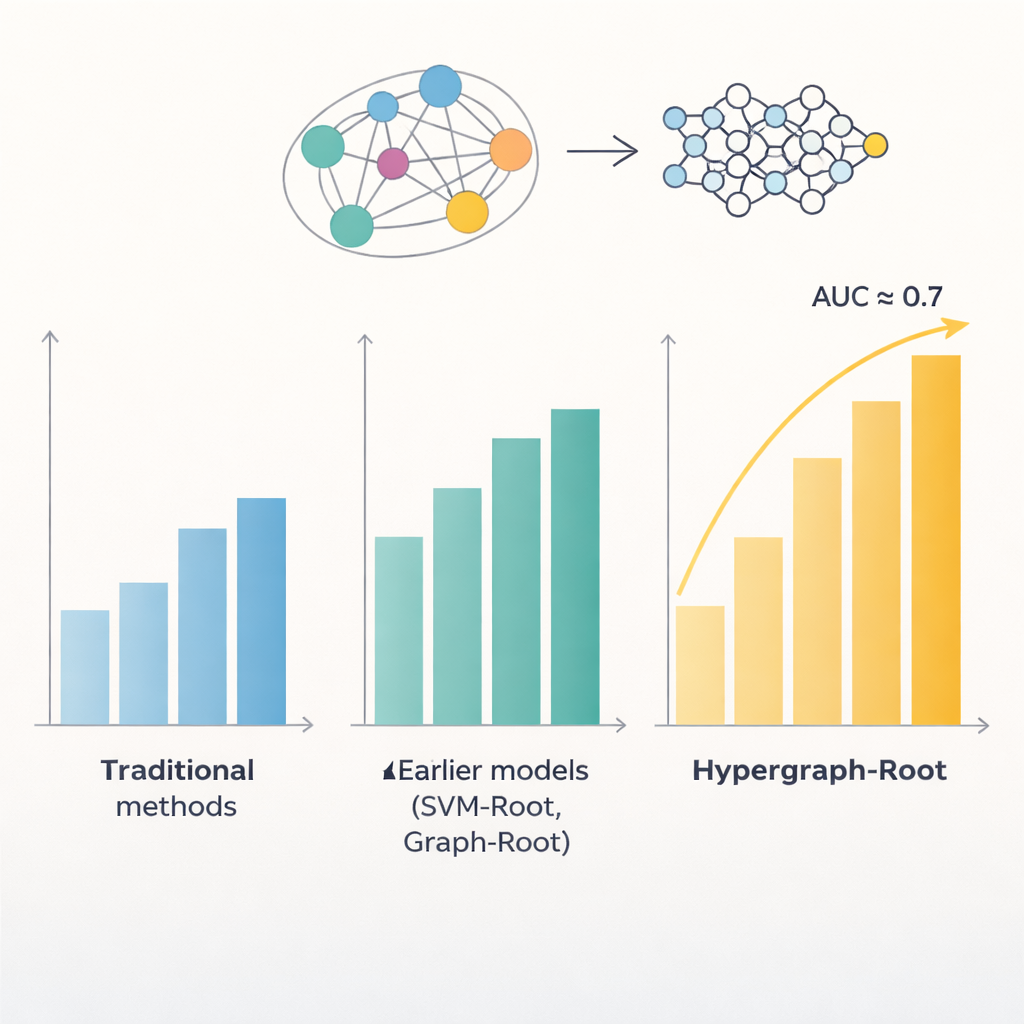
Proteínas são formadas por cadeias de aminoácidos, e padrões nessas cadeias frequentemente revelam onde uma proteína atua na planta e o que ela faz. Modelos computacionais anteriores tentaram explorar esses padrões para detectar proteínas associadas às raízes, mas ficaram limitados a acurácias abaixo de 80%. Um problema é que eles tratavam as relações entre aminoácidos de forma relativamente simples, geralmente como pares. Outro é que dependiam de tipos limitados de características extraídas das sequências. Os autores supuseram que representações mais ricas de cada proteína, juntamente com maneiras mais inteligentes de modelar as relações entre aminoácidos, poderiam revelar padrões mais sutis ligados às funções radiculares.
Tomando emprestado truques da linguagem e das redes
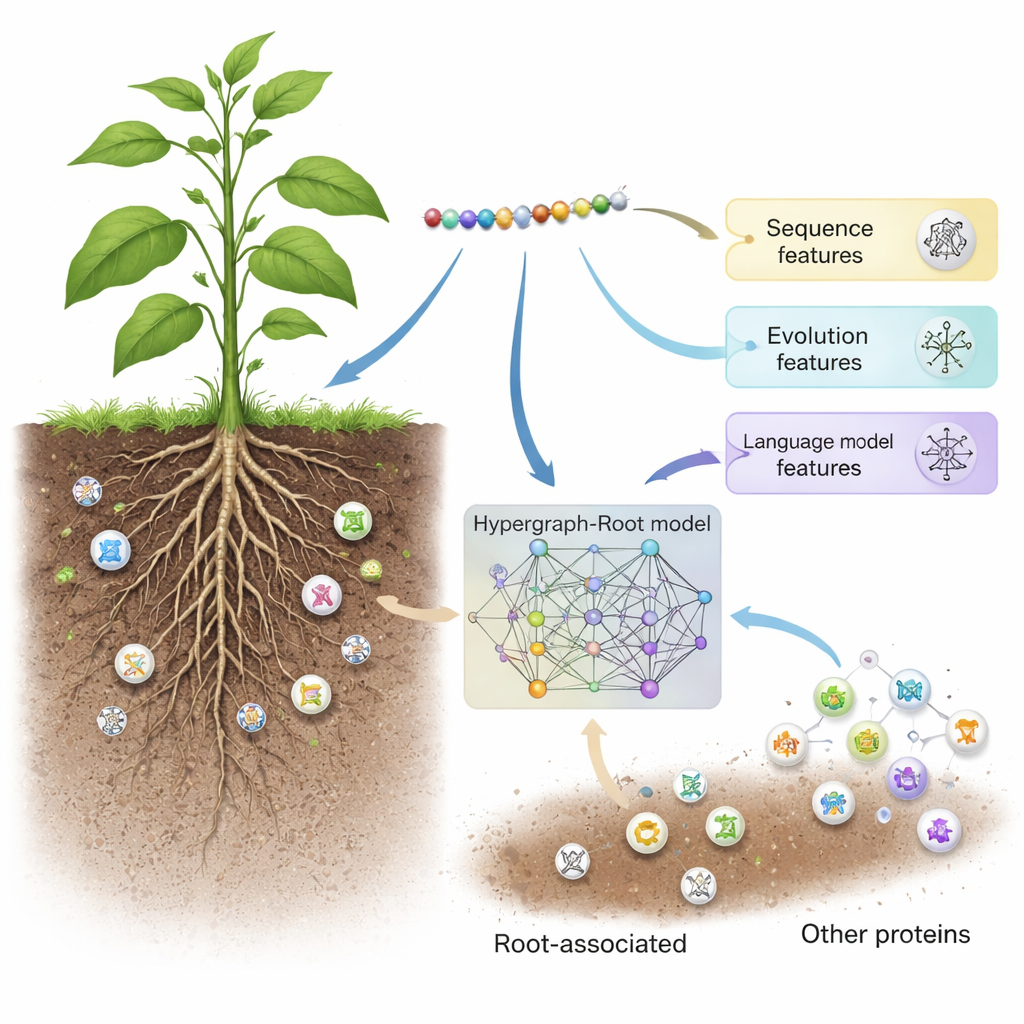
O Hypergraph-Root começa descrevendo cada proteína de três maneiras complementares. Utiliza esquemas tradicionais de pontuação de sequência (BLOSUM62 e matrizes de pontuação específicas por posição) que capturam como aminoácidos tendem a se substituir ao longo da evolução. Em seguida, adiciona uma terceira descrição mais moderna proveniente de um modelo de linguagem de proteínas chamado ProtT5 — um software treinado em milhões de sequências de proteínas, de modo análogo a como um motor de previsão de texto é treinado em linguagem humana. O ProtT5 produz um rico “embedding” numérico para cada aminoácido que codifica pistas estruturais e funcionais. Juntas, essas três visões oferecem uma impressão digital detalhada de cada proteína no estudo.
Mapeando conexões complexas dentro das proteínas
Para ir além de comparações pareadas simples, os pesquisadores previram quão próximos os aminoácidos estão na estrutura 3D da proteína e usaram essa informação para construir um hipergráfico — uma rede na qual uma única conexão pode ligar mais de dois aminoácidos ao mesmo tempo. Uma rede neural especializada, a rede convolucional em hipergráfico, processa essa rede consciente da estrutura e refina as impressões digitais das proteínas em características de nível mais alto. Um módulo de atenção multi-cabeça então aprende quais partes da proteína carregam os sinais mais úteis para decidir se ela está associada às raízes. Finalmente, um classificador padrão transforma essas características destiladas em uma pontuação de probabilidade: associada às raízes ou não. Ao longo de muitos ciclos de treinamento e em conjuntos de teste balanceados e não balanceados, o Hypergraph-Root alcançou acurácias acima de 83% e uma área sob a curva ROC (AUC) em torno de 0,9, superando claramente modelos anteriores.
O que o modelo revela e por que isso importa
Além da acurácia bruta, o modelo forneceu insights sobre quais informações são mais relevantes. As características vindas do modelo de linguagem ProtT5 contribuíram mais do que as características tradicionais de sequência e evolução, sugerindo que modelos grandes pré-treinados podem captar sinais biológicos sutis que métodos antigos não detectam. O componente de hipergráfico também se mostrou importante: removê-lo ou substituí-lo por um modelo de grafo mais simples reduziu o desempenho. Quando os pesquisadores aplicaram o Hypergraph-Root a proteínas não rotuladas previamente como associadas às raízes, ele destacou um punhado de proteínas cujas funções conhecidas — como transporte de membrana e marcação de proteínas em raízes — sugerem fortemente que desempenham papéis na biologia radicular. Esses candidatos agora oferecem às biólogas e biólogos experimentais listas curtas claras para testar no laboratório.
De previsões inteligentes a culturas mais fortes
Em termos cotidianos, o Hypergraph-Root é como um bibliotecário especialista em biologia vegetal: dado apenas as “letras” de uma proteína, ele estima se essa proteína provavelmente atua nas raízes. Ao combinar insights de modelos de linguagem, história evolutiva e relações estruturais complexas, ele melhora muito as ferramentas de predição anteriores. Embora não substitua experimentos, pode reduzir milhares de possibilidades a algumas poucas manejáveis, economizando tempo e dinheiro. A longo prazo, tais modelos podem acelerar a descoberta de proteínas associadas às raízes que ajudam culturas a sobreviver ao calor, à seca ou a solos pobres — um passo importante rumo a uma agricultura mais resiliente em um clima em transformação.
Citação: Chen, L., Xun, X. & Zhou, B. Root-associated protein prediction using a protein large language model and hypergraph convolutional networks. Sci Rep 16, 4876 (2026). https://doi.org/10.1038/s41598-026-35110-7
Palavras-chave: proteínas associadas às raízes, bioinformática vegetal, aprendizado profundo, modelos de linguagem para proteínas, resiliência de culturas