Clear Sky Science · pt
Cálculo da pontuação de similaridade entre sentenças por meio de aprendizado profundo híbrido com foco especial em sentenças com negação
Por que o significado das palavras importa para uma avaliação justa
Quando alunos respondem perguntas com suas próprias palavras, os sistemas que ajudam professores a corrigir essas respostas precisam entender mais do que apenas palavras-chave em comum. Uma pequena palavra como “não” pode virar o sentido de uma frase, e se sistemas automatizados não perceberem essa inversão, alunos podem ser avaliados de forma injusta. Este artigo enfrenta esse problema ao propor uma nova maneira de o computador comparar os significados de sentenças, dando atenção especial a como palavras de negação alteram o que está sendo dito.
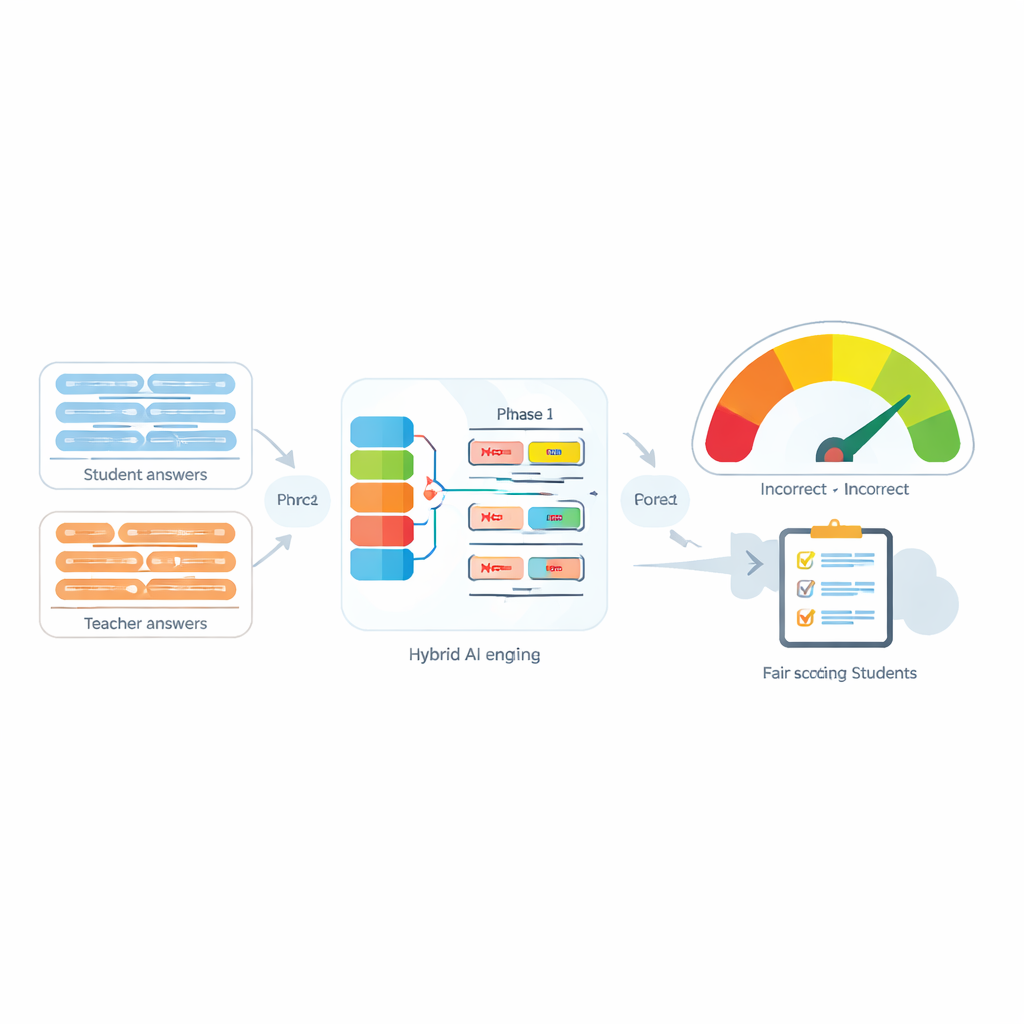
O desafio de palavras pequenas com grande impacto
Sistemas de Avaliação Automática são cada vez mais usados para reduzir a carga de trabalho dos professores comparando a resposta do aluno com a resposta-modelo do instrutor. Muitas ferramentas modernas fazem isso transformando cada sentença em uma “impressão digital” numérica e então medindo quão próximas essas impressões estão. Essas ferramentas funcionam razoavelmente bem quando não há negação, mas frequentemente falham quando aparecem palavras como “não”, “nunca” ou “nenhum”. Por exemplo, “O método é preciso” e “O método não é preciso” podem acabar parecendo surpreendentemente semelhantes para o computador, embora tenham sentidos opostos. Os autores mostram que não apenas a presença da negação, mas também quantas palavras de negação aparecem e onde elas são colocadas na frase, podem mudar completamente o significado pretendido.
Construindo um conjunto de dados que ensina nuances
Para treinar um sistema que realmente entenda a negação, os autores primeiro precisaram de dados que destacassem esses casos difíceis. Eles criaram o Negation-Sentence-Similarity Dataset, contendo 8.575 pares de sentenças de quatro domínios da ciência da computação: sistemas operacionais, bancos de dados, redes de computadores e aprendizado de máquina. Para cada par, humanos atribuíram uma pontuação de similaridade que já leva a negação em conta. O conjunto de dados também registra quantas palavras de negação cada sentença usa e que tipo de padrão de negação ela segue, como um único “não”, um número par ou ímpar de negações, ou casos mais complexos em que a negação interage com conectivos como “porque” ou “mas”. Essa rotulação detalhada dá ao modelo pistas explícitas sobre como a negação molda o significado.
Um motor híbrido que funde múltiplos pontos de vista
O coração do sistema proposto, chamado Negation-Aligned Similarity Scorer, é um motor em duas fases. Na primeira fase, o sistema passa cada sentença por vários modelos de linguagem diferentes, cada um capturando aspectos ligeiramente distintos do significado. As saídas são costuradas e então passadas por uma rede recorrente bidirecional que analisa a sentença como um todo, levando em conta a ordem das palavras e o contexto local. Isso produz um resumo compacto de cada sentença, melhor ajustado a formulações sutis, incluindo a posição das palavras de negação em relação a outras palavras.
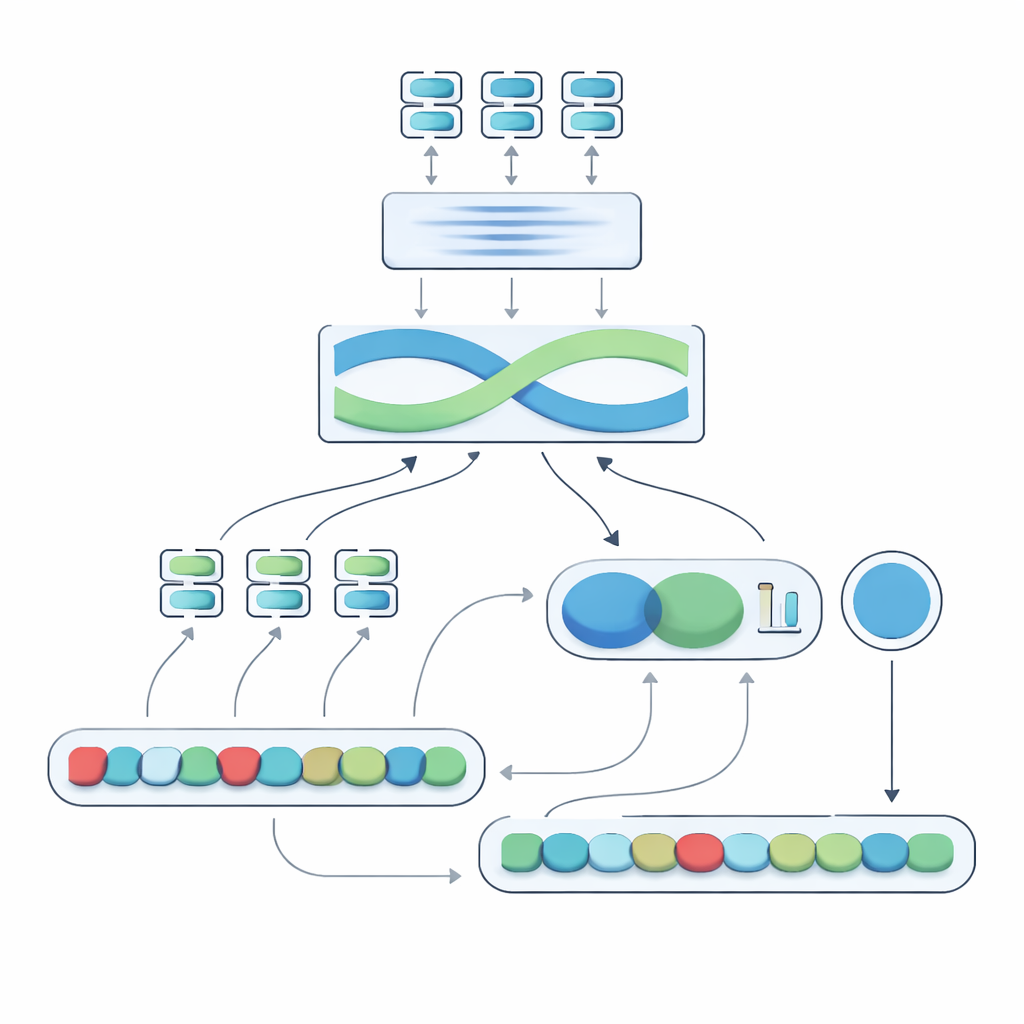
Ensinando o modelo a perceber a inversão causada pela negação
Na segunda fase, o sistema compara os dois resumos de sentença e adiciona informações explícitas sobre negação. Ele examina o quanto os resumos diferem, o quanto se sobrepõem, e combina esses sinais com três recursos simples: a diferença no número de palavras de negação, se as sentenças têm contagens par ou ímpar de negações (o que pode inverter ou cancelar o sentido negativo), e se a negação aparece em posições aproximadamente correspondentes. Todas essas pistas são combinadas em uma pequena rede de predição que gera uma pontuação de similaridade de 0 a 100. Treinada de ponta a ponta no conjunto de dados curado, essa pontuação torna-se sensível à forma como a negação remodela o significado, em vez de tratar “não” como apenas mais uma palavra.
Quão bem o novo avaliador funciona na prática
Para testar sua abordagem, os autores a avaliam tanto em seu conjunto de dados customizado quanto em um benchmark amplamente usado de similaridade de sentenças. Comparado com fortes baselines baseados em transformadores que usam métodos padrão, o novo avaliador alcança menor erro de predição e muito melhor qualidade de classificação, com uma pontuação F1 próxima de 0,97. Em exemplos cuidadosamente escolhidos, ele atribui baixas pontuações de similaridade quando a negação claramente inverte o sentido e altas pontuações quando a dupla negação efetivamente se cancela, enquanto modelos concorrentes ainda tendem a superestimar a similaridade. Um estudo de ablação confirma que ambos os ingredientes-chave — a camada recorrente sensível à sequência e as características explícitas de negação — são importantes para esse ganho de desempenho.
O que isso significa para alunos e ferramentas futuras
Para um leitor não especializado, a conclusão é direta: a forma como dizemos “não” importa, e máquinas podem ser ensinadas a perceber isso. Ao combinar múltiplos modelos de linguagem, processamento contextual e contagens simples e posições de palavras de negação, o avaliador proposto oferece uma maneira mais justa e confiável de julgar quando duas sentenças realmente significam a mesma coisa. Isso pode ajudar sistemas de correção automatizada a evitar erros graves, como tratar “não é permitido” como se fosse “é permitido”. Embora o método seja mais exigente computacionalmente e ainda focado em domínios técnicos, ele aponta para ferramentas futuras que capturam melhor a lógica fina da linguagem cotidiana, tornando as tecnologias de linguagem automatizadas mais inteligentes e mais confiáveis.
Citação: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Palavras-chave: similaridade de sentenças, negação na linguagem, correção automatizada, processamento de linguagem natural, modelos de aprendizado profundo