Clear Sky Science · pt
Pesquisa de IP de alto desempenho por aceleração em GPU para suportar roteamento escalável e eficiente em redes de comunicação orientadas por dados
Por que vias de Internet mais rápidas importam
Cada foto que você compartilha, vídeo que transmite ou mensagem que envia precisa passar por um labirinto de cruzamentos digitais chamados roteadores. Cada roteador deve decidir rapidamente para onde enviar cada pacote de dados a seguir. À medida que o uso global da Internet explode, essas decisões acontecem bilhões de vezes por segundo, e até pequenos atrasos podem se propagar em navegação mais lenta ou redes congestionadas. Este artigo explora uma nova forma de acelerar uma das etapas mais demoradas desse processo de decisão, tirando proveito do enorme poder paralelo dos processadores gráficos — os mesmos chips que impulsionam videogames e IA — para manter as redes futuras rápidas e escaláveis.
O livro de endereços oculto da Internet
No coração de todo roteador está um enorme livro de endereços, chamado tabela de encaminhamento, que mapeia intervalos de endereços IP para o próximo salto na jornada. Quando um pacote chega, o roteador precisa buscar qual entrada melhor corresponde ao destino do pacote, usando a regra de “correspondência de prefixo mais longo”: entre todas as correspondências parciais, escolhe a mais específica. Métodos tradicionais em software armazenam esses prefixos em estruturas em forma de árvore e as percorrem passo a passo. Isso funciona, mas à medida que as tabelas crescem para dezenas ou centenas de milhares de entradas, o processo fica mais lento e consumidor de memória, especialmente em processadores centrais comuns que só lidam com um número limitado de tarefas ao mesmo tempo.
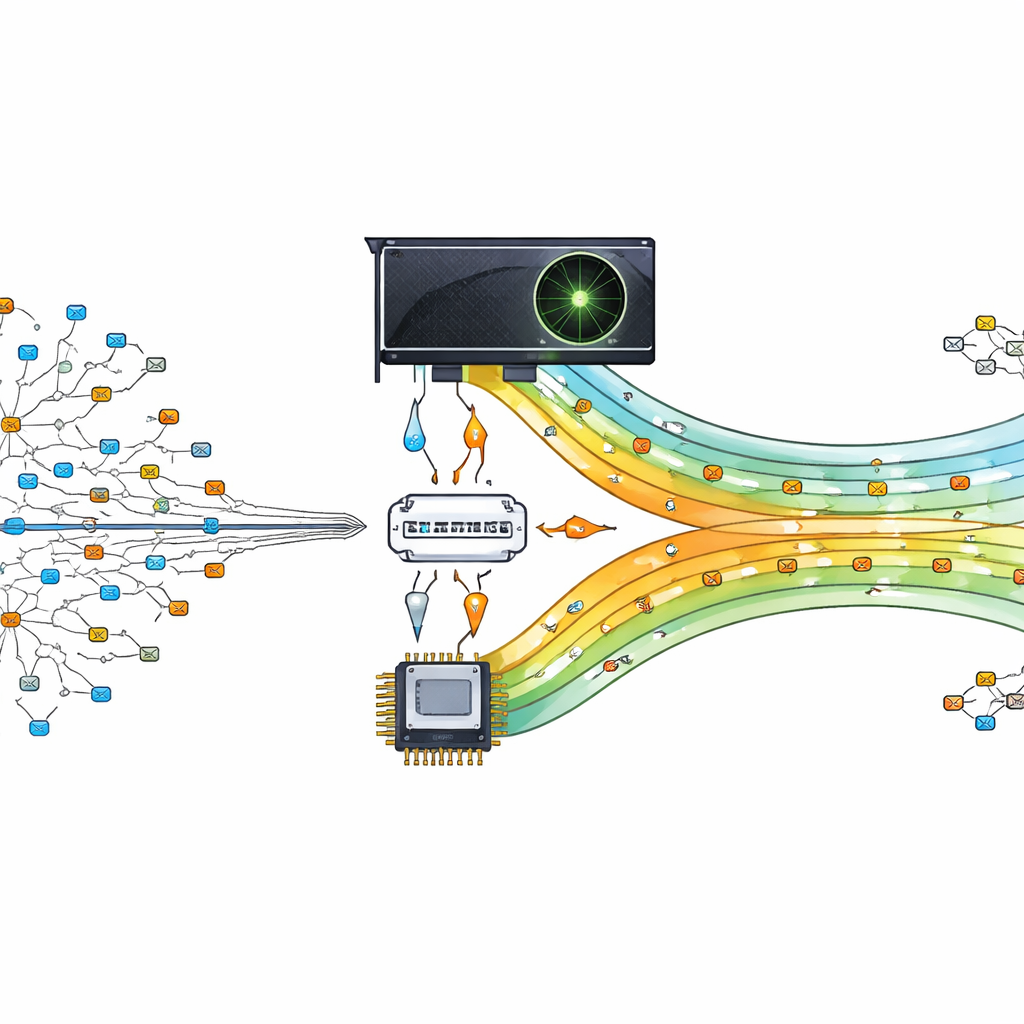
Transformando um chip gráfico em um controlador de tráfego
Os autores propõem descarregar esse pesado trabalho de busca para uma unidade de processamento gráfico (GPU), um chip projetado para executar milhares de pequenas tarefas em paralelo. O projeto trata a GPU como um assistente do processador principal. O processador central prepara e organiza a tabela de roteamento, então envia versões compactas dos dados para a GPU. Quando os pacotes chegam, seus endereços de destino são divididos e enviados para a GPU, onde muitas threads procuram simultaneamente a melhor correspondência. Ao permitir que centenas ou milhares de buscas ocorram em paralelo, o roteador consegue acompanhar as demandas modernas de comunicação orientada por dados.
Encolhendo endereços para acelerar decisões
Um insight chave do trabalho é que endereços mais curtos são mais rápidos de buscar. Em vez de usar endereços IP brutos, os autores os comprimem usando um método sem perdas chamado codificação de Huffman, que atribui códigos mais curtos aos padrões de endereço mais comuns. Isso reduz o número médio de bits necessários para representar cada entrada, cortando tanto o uso de memória quanto a altura da estrutura de busca subjacente. Em seguida, eles armazenam os prefixos em uma árvore “multibit” que examina vários bits de cada vez, em vez de apenas um, reduzindo ainda mais o número de passos necessários. Para aproveitar as forças da GPU, transformam essa árvore em arrays unidimensionais simples, substituindo o complexo encadeamento por ponteiros por cálculos regulares de índice que milhares de threads podem executar de forma eficiente.
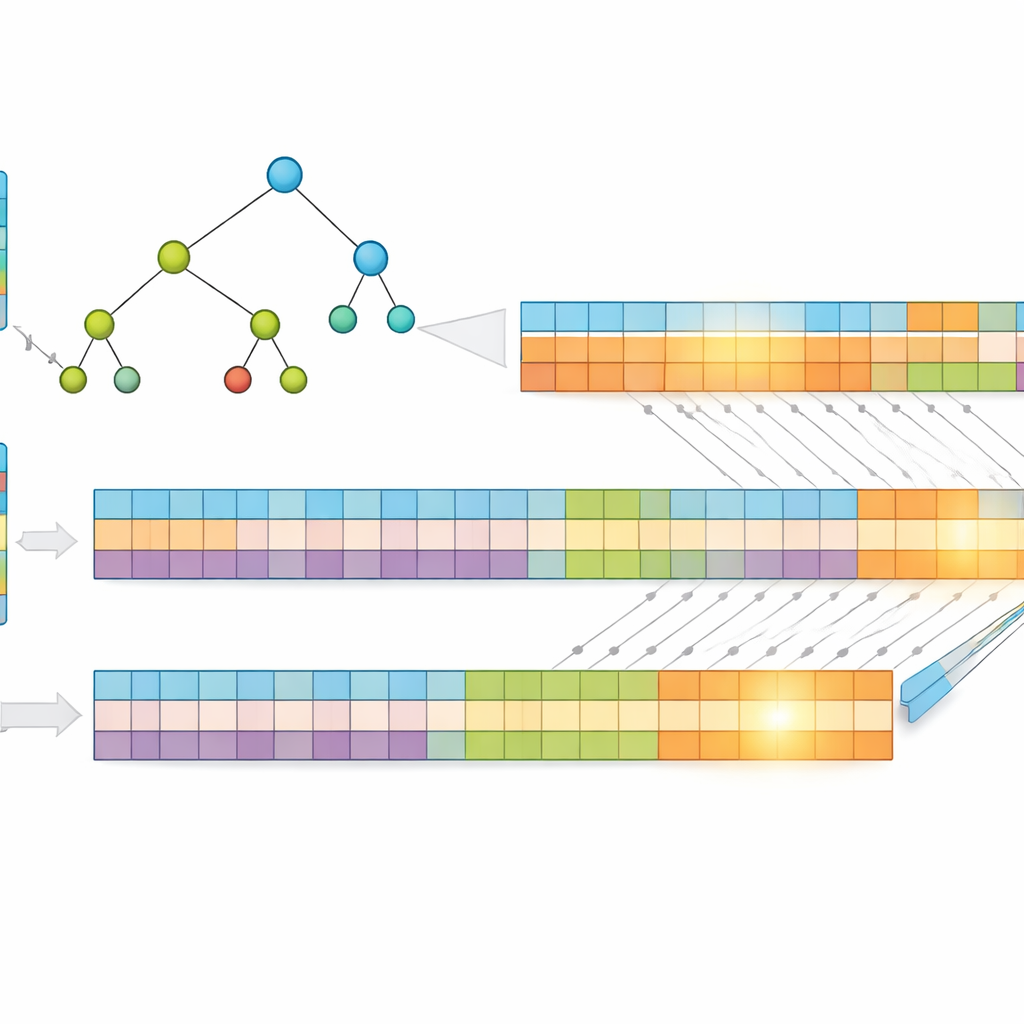
Dividindo o problema para paralelismo massivo
Para ampliar ainda mais o desempenho, os pesquisadores dividem cada endereço comprimido em duas metades iguais e constroem duas árvores separadas — uma para a primeira metade e outra para a segunda. Quando um pacote chega, a GPU busca em ambas as árvores em paralelo. Cada busca retorna um pequeno conjunto de possíveis correspondências, e a resposta final vem da interseção desses conjuntos para encontrar o prefixo compartilhado mais específico. Como o trabalho é dividido e processado simultaneamente, o tempo gasto depende principalmente do comprimento máximo do prefixo e do número de bits examinados por etapa, não de quantas entradas a tabela contém. Testes com dados reais de roteamento da Internet mostram que esse projeto mantém um tempo de consulta quase constante mesmo à medida que a tabela cresce.
O que os experimentos revelam
A equipe comparou seu método baseado em GPU a uma variedade de abordagens bem conhecidas, incluindo árvores binárias clássicas, árvores comprimidas e outros esquemas acelerados por GPU, como hashing e árvores de busca binária. Em conjuntos de dados reais de roteamento, seu sistema apresentou ganhos dramáticos: cerca de 83–91% mais rápido do que os métodos de árvore populares baseados em processador central, e 89–97% mais rápido do que métodos GPU anteriores. A compressão também reduziu o uso de memória em aproximadamente um terço, em média, aliviando a pressão na memória limitada do chip e ajudando a manter as estruturas de busca da GPU rasas e eficientes. Importante, o desempenho do método permaneceu estável em diferentes tamanhos de tabela de roteamento, ressaltando sua adequação para redes em crescimento.
O que isso significa para usuários comuns
Para um não especialista, a conclusão é que os autores mostram como transformar um chip gráfico em um controlador de tráfego altamente eficiente para dados da Internet, usando técnicas inteligentes de encolhimento e divisão das informações de endereço. Ao combinar compressão, layouts de árvore mais inteligentes e busca massivamente paralela, a abordagem encontra a melhor rota para cada pacote muito mais rapidamente do que muitas técnicas existentes, sem ser desacelerada à medida que os livros de endereços da Internet se expandem. Embora o trabalho seja demonstrado principalmente para o sistema de endereços atual, as mesmas ideias podem ser estendidas ao espaço de endereços maior do futuro, ajudando a manter os serviços online responsivos enquanto nosso apetite por dados continua a crescer.
Citação: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
Palavras-chave: roteamento em GPU, consulta de IP, escalabilidade de rede, encaminhamento de pacotes, computação paralela