Clear Sky Science · pt
Detecção de objetos camuflados via interação hierárquica atenta a contexto e textura
Por que identificar formas ocultas importa
De insetos com cor de folha a camuflagens militares e até crescimentos difíceis de ver em exames médicos, nosso mundo está cheio de coisas projetadas para se misturar ao fundo. Ensinar computadores a encontrar esses objetos ocultos de forma confiável pode ajudar a proteger a vida selvagem, melhorar inspeções de segurança e auxiliar médicos a detectar doenças mais cedo. Este artigo apresenta um novo sistema de inteligência artificial, chamado CTHINet, que aprende a ver através da camuflagem ao prestar atenção não apenas ao contexto geral da cena, mas também a pequenas pistas de textura que os olhos humanos frequentemente não percebem.
Ver a floresta e as árvores
A detecção de objetos camuflados é bem mais difícil que a detecção comum porque o alvo muitas vezes combina com o entorno em cor, brilho e forma. Métodos mais antigos dependiam de pistas manuais simples, como movimento, contornos ou textura básica, que falham em cenas congestionadas ou ruidosas. Abordagens modernas de deep learning avançaram treinando grandes redes em coleções especializadas de imagens de animais camuflados e objetos artificiais. Muitas dessas técnicas adicionam indícios extras, como desenhar limites ao redor de objetos ou estimar incerteza, mas elas podem ser facilmente enganadas quando as bordas estão borradas ou ambíguas — exatamente o caso em camuflagens eficazes.
Pequenas pistas de textura que denunciam o truque
Os autores sustentam que mesmo a melhor camuflagem deixa traços reveladores na textura fina da imagem — pequenas diferenças em granulação, padrão ou suavidade que são fáceis de ignorar quando se foca apenas nos contornos. Com base nessa ideia, o CTHINet separa o aprendizado em dois ramos coordenados. Um ramo de “contexto”, baseado em um backbone transformer de visão potente, captura informação ampla e multiescala sobre toda a cena: como as regiões se relacionam, onde grandes formas se situam e quais áreas podem plausivelmente conter um objeto. Em paralelo, um ramo dedicado à “textura” foca estritamente em padrões sutis de superfície, treinado com rótulos de textura especiais que indicam à rede que tipos de detalhe fino pertencem ao objeto oculto em vez do fundo.
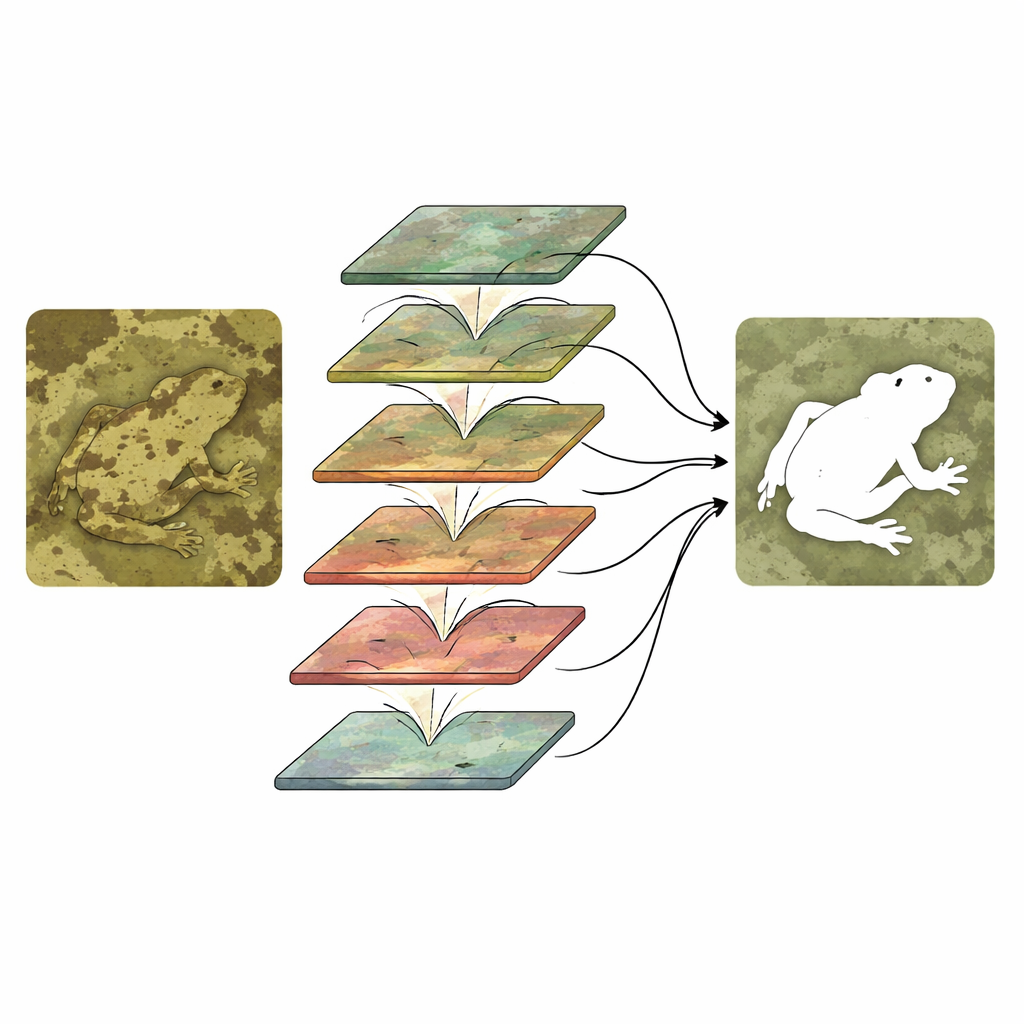
Como os dois ramos trabalham juntos
Executar dois ramos não basta; eles devem interagir de forma inteligente. O CTHINet primeiro refina as características de contexto usando um Módulo de Agregação de Recursos Multi‑cabeça. Este módulo divide a informação em várias partes, cada uma processada com um “nível de zoom” efetivo diferente, para que o sistema possa responder tanto a insetos minúsculos quanto a animais grandes. Em seguida, ele recombina essas visões para que se informem mutuamente sem explodir o custo computacional. Depois, uma série de Módulos de Interação Hierárquica de Escala Mista liga os fluxos de contexto e textura. Em cada estágio, a rede agrupa e mistura canais de ambos os ramos, permite a troca de informação e então re‑pondera esses canais para que as combinações mais informativas sejam amplificadas enquanto as menos úteis são suprimidas. Esse empilhamento do grosseiro ao fino vai gradualmente aguçando o contorno do objeto oculto e separando‑o de detalhes de fundo que distraem.
Comprovando que funciona na natureza e na clínica
Para testar o CTHINet, os pesquisadores o avaliaram em três benchmarks públicos desafiadores de animais e objetos camuflados, contendo milhares de imagens em cenários naturais variados. Em várias medidas padrão de precisão, o novo método superou consistentemente mais de vinte sistemas de ponta, especialmente em cenas difíceis com alvos pequenos, forte correspondência com o fundo ou oclusão parcial. A equipe também aplicou a mesma rede, com mudanças mínimas, em uma tarefa médica: segmentação de pólipos em imagens de colonoscopia. Pólipos frequentemente se confundem com a parede intestinal de forma semelhante à que animais se misturam à folhagem. Aqui também, o CTHINet apresentou os melhores resultados entre vários modelos fortes de imagens médicas, sugerindo que sua forma de combinar contexto e textura é amplamente útil.
O que isso significa para encontrar o quase invisível
Em termos práticos, o CTHINet incorpora uma ideia simples, porém poderosa: para encontrar algo que foi feito para ficar oculto, um computador deve observar tanto o panorama geral quanto os menores detalhes da superfície, e permitir que essas duas visões se informem passo a passo. Ao projetar uma rede que separa claramente essas funções e depois as reúne por meio de interações cuidadosamente escalonadas, os autores alcançam detecção mais precisa de alvos camuflados e mostram potencial para tarefas de inspeção médica e industrial onde estruturas importantes podem ser facilmente negligenciadas. À medida que os dados de imagem continuam a crescer, sistemas sensíveis a contexto e textura podem se tornar ferramentas-chave para revelar o que se pretendia manter invisível.
Citação: Wang, Z., Deng, Y., Shen, C. et al. Camouflaged object detection via context and texture-aware hierarchical interaction. Sci Rep 16, 9328 (2026). https://doi.org/10.1038/s41598-025-32409-9
Palavras-chave: detecção de objetos camuflados, visão computacional, análise de textura, segmentação de imagens médicas, aprendizado profundo