Clear Sky Science · pt
Um Conjunto de Dados Unificado para o Projeto de Anticorpos e Nanocorpos Incluindo Sequência, Estrutura e Dados de Afiliação
Por que ferramentas imunes minúsculas e big data importam
Anticorpos e seus parentes menores, os nanocorpos, são os mísseis guiados de precisão do organismo contra infecções e câncer. Desenvolvedores de medicamentos agora tentam projetar essas moléculas em computadores, assim como engenheiros projetam aeronaves. Mas, até recentemente, a matéria‑prima para esse desenho por inteligência artificial — dados confiáveis sobre componentes de anticorpos, formas e o quão fortemente eles se ligam aos alvos — estava dispersa por muitos bancos de dados incompatíveis. Este artigo apresenta o Antibody and Nanobody Design Dataset (ANDD), um recurso público unificado construído para fornecer aos pesquisadores dados limpos e abrangentes necessários para criar a próxima geração de terapias direcionadas.
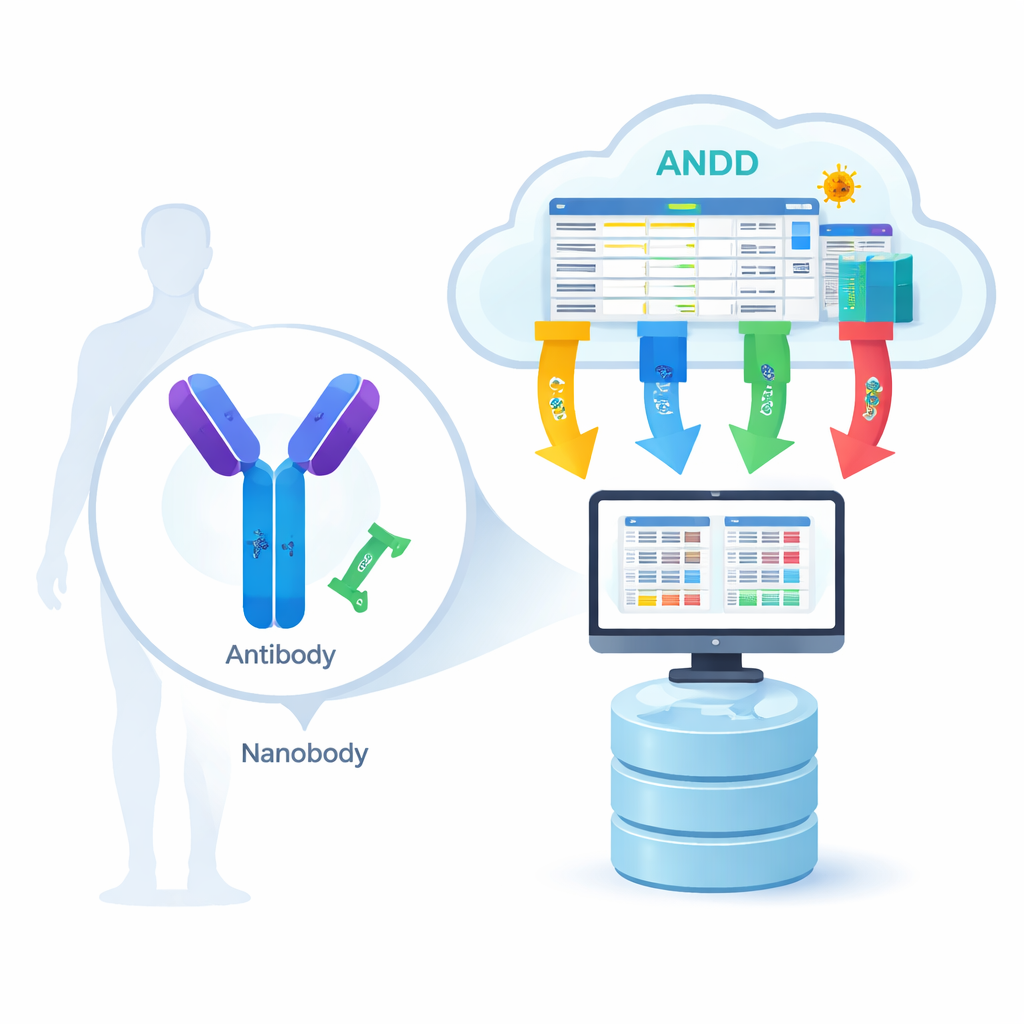
Do mecanismo de fechadura e chave biológico ao plano digital
Anticorpos são proteínas grandes em forma de Y, enquanto nanocorpos são versões muito menores e de peça única encontradas em animais como lhamas e alpacas. Ambos reconhecem “fechaduras” específicas em vírus, células cancerígenas ou outras proteínas associadas a doenças. Para que modelos computacionais aprendam como esse reconhecimento funciona, eles precisam de quatro tipos de informação para muitos exemplos diferentes: a sequência de aminoácidos (a lista de peças), a estrutura 3D (a forma), o antígeno (o alvo) e a força de ligação (o quão firmemente os dois se mantêm unidos). Até agora, a maioria dos recursos capturava apenas uma ou duas dessas peças por vez, obrigando cientistas a alternar entre bancos de dados e a montar manualmente as informações, o que retardava o progresso e introduzia erros.
Reunindo peças dispersas em uma biblioteca organizada
A equipe do ANDD coletou dados de 15 fontes principais, incluindo bancos de dados dedicados a anticorpos e nanocorpos, repositórios gerais de proteínas e até documentos de patentes. Em seguida, passaram essas entradas brutas por um pipeline cuidadosamente roteirizado: download, reformatação para um esquema compartilhado, verificação cruzada de identificadores, remoção de duplicatas e harmonização de regras de nomenclatura. Quando bancos de dados divergiam, deram prioridade a fontes curadas e a experimentos diretos. O resultado final é uma única tabela, além de um conjunto de arquivos de estrutura que conectam sequência, estrutura, alvo e informação de ligação de maneira consistente, com cada registro marcado para que os usuários possam rastrear exatamente sua origem e como foi processado.
Detalhamento em camadas para diferentes necessidades de pesquisa
Nem toda entrada no ANDD tem o mesmo nível de riqueza, por isso os autores organizaram a coleção em camadas de detalhe crescente. No nível mais amplo, há 48.683 entradas de anticorpos e nanocorpos com informação de sequência. Um grande subconjunto adiciona estruturas 3D, e um subconjunto menor inclui também as sequências das proteínas‑alvo. A camada mais detalhada — milhares de entradas — acrescenta afinidade de ligação medida ou prevista. Para anticorpos, por exemplo, 18.464 entradas têm sequências; o mesmo número combina sequência e estrutura; mais de 8.000 incluem também sequências de antígenos; e 7.737 têm sequência, estrutura, antígeno e dados de afinidade completos. Existe uma hierarquia paralela para nanocorpos, oferecendo tanto a experimentalistas quanto a desenvolvedores de modelos flexibilidade: eles podem escolher conjuntos de dados grandes e simples ou subconjuntos menores e mais ricos em informação.
Preenchendo as lacunas na afinidade de ligação
A afinidade de ligação é crucial para o desenho de medicamentos, mas valores experimentais são escassos e relatados de forma desigual. Para enfrentar essa lacuna sem confundir dado com predição, os autores usaram uma ferramenta de deep learning especializada, ANTIPASTI, para estimar a afinidade apenas para entradas que tinham estruturas mas careciam de medições. Esses 2.271 valores previstos são claramente rotulados e mantidos separados dos cerca de 7.000 valores medidos experimentalmente. A equipe então verificou a consistência geral usando outro modelo, AlphaBind, e comparando medidas matematicamente relacionadas de ligação. Correlações fortes e erro baixo sugeriram que os valores experimentais curados são confiáveis e que os valores previstos seguem tendências sensatas, sem serem tratados como verdade absoluta.
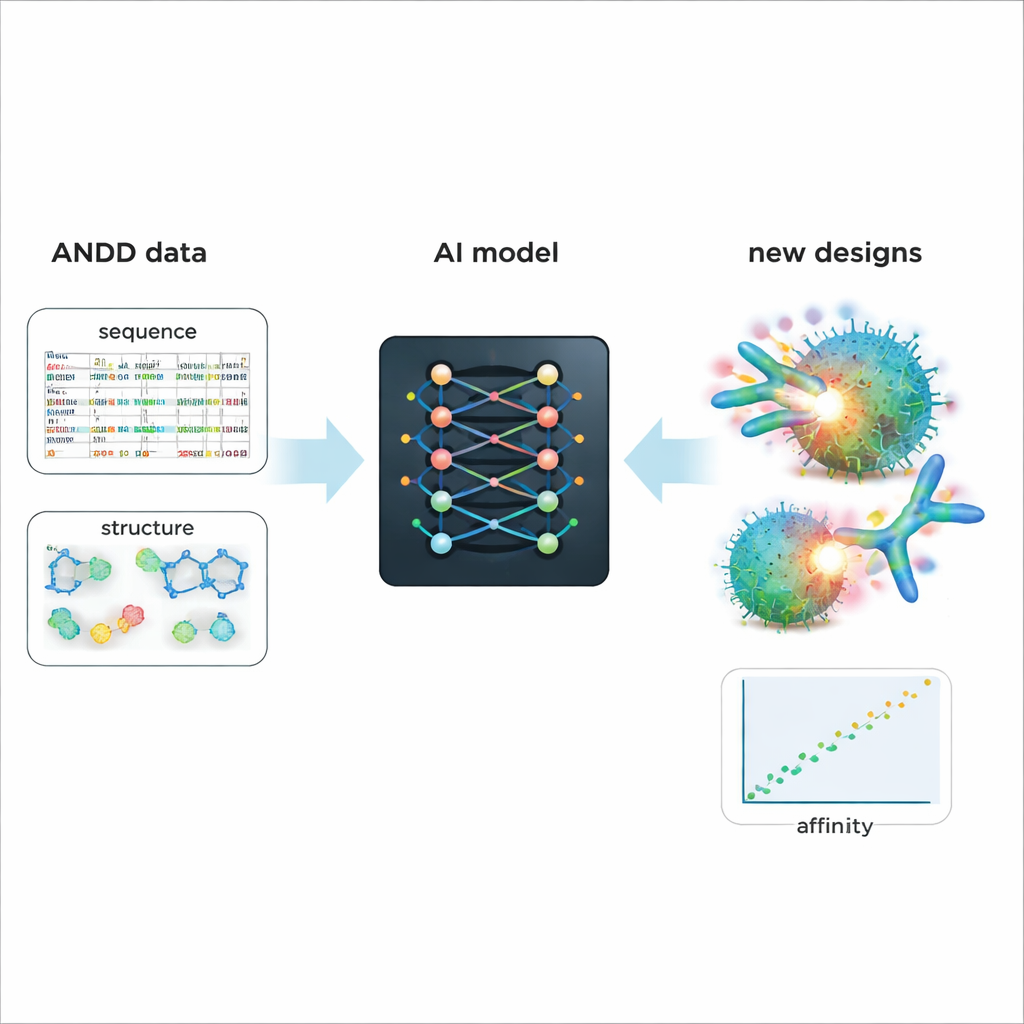
Potencializando um desenho mais inteligente de futuros medicamentos
Para demonstrar o valor prático do ANDD, os autores ajustaram finamente um modelo generativo de IA existente que projeta anticorpos e nanocorpos. O treinamento com as informações combinadas de sequência, estrutura, alvo e afinidade do ANDD levou a moléculas geradas com melhor afinidade prevista e formas mais realistas do que um modelo de referência treinado em dados antigos e mais simples. Além desse estudo de caso, o ANDD está disponível abertamente sob uma licença permissiva, acompanha documentação completa e um pipeline de construção reprodutível, e foi concebido para ser atualizado regularmente. Para não especialistas, a mensagem principal é que o ANDD transforma um emaranhado de dados sobre anticorpos em uma biblioteca coerente e confiável — dando às ferramentas de IA um ponto de partida muito melhor para projetar medicamentos biológicos mais precisos e eficazes.
Citação: Wu, Y., Liu, X., Hrovatin, K. et al. A Unified Dataset for Antibody and Nanobody Design Including Sequence, Structure, and Binding Affinity Data. Sci Data 13, 295 (2026). https://doi.org/10.1038/s41597-026-06878-0
Palavras-chave: projeto de anticorpos, nanocorpos, afinidade de ligação, terapêuticos biológicos, descoberta de medicamentos por IA