Clear Sky Science · pt
Um Conjunto de Dados em Larga Escala de Células do Sangue Periférico para Análise Hematológica Automatizada
Por que Fotos de Células Sanguíneas Importam
Cada exame de sangue de rotina esconde um mundo microscópico de células que pode revelar infecções, anemia ou até cânceres hematológicos muito antes de os sintomas se tornarem evidentes. Tradicionalmente, os médicos inspecionam essas células a olho, sob o microscópio — uma prática cuidadosa, porém demorada. Este estudo apresenta uma coleção muito grande e cuidadosamente rotulada de imagens de células sanguíneas, projetada para ensinar computadores a reconhecer essas células automaticamente. O objetivo é tornar os exames de sangue futuros mais rápidos, mais consistentes e mais acessíveis, fornecendo à inteligência artificial a experiência visual necessária para ajudar os médicos a interpretar esfregaços sanguíneos com precisão.
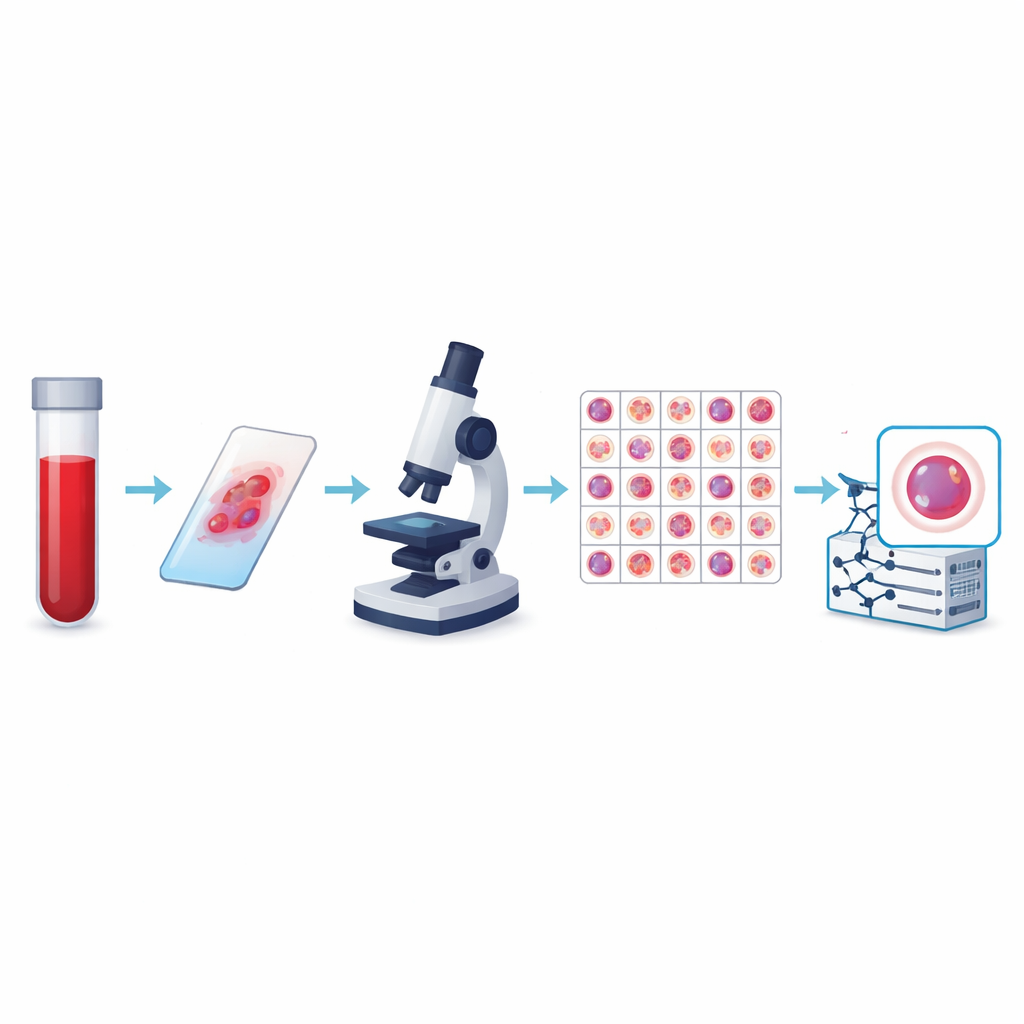
De Contagens Simples à Imagem Inteligente
Os glóbulos brancos são defensores-chave do nosso sistema imunológico, e sua proporção e aparência fornecem pistas cruciais sobre a saúde. Um aumento em certos tipos celulares pode indicar infecção ou alergia, enquanto a presença súbita de células imaturas chamadas “blasts” pode alertar para leucemia. Os laboratórios já utilizam máquinas automatizadas para contar células, mas mudanças sutis na forma frequentemente ainda exigem o olhar de um especialista. Revisores humanos podem divergir, e examinar lâminas uma a uma consome tempo. À medida que a medicina avança para a imagem digital e a inteligência artificial, cresce a necessidade de grandes coleções de imagens confiáveis que possam treinar computadores a identificar esses padrões celulares decisivos com a mesma confiabilidade de um hematologista experiente.
Construindo uma Biblioteca Enorme de Células Sanguíneas
Os autores criaram o que é atualmente a maior coleção pública de imagens de células do sangue periférico, chamada KU-Optofil PBC. Ela contém 31.489 imagens em alta resolução de células individuais distribuídas em 13 grupos, incluindo defensores comuns como linfócitos e neutrófilos segmentados, bem como tipos mais raros, porém clinicamente críticos, como blasts, mielócitos e linfócitos reativos. Todas as imagens provêm de esfregaços sanguíneos corados preparados sob condições padronizadas em um único hospital, usando o mesmo sistema de aquisição. Essa consistência significa que os computadores que aprendem com os dados veem uma visão estável e bem controlada de cada tipo celular, em vez de um mosaico de imagens incompatíveis.
Olhos Especializados e Curadoria Cuidadosa
Para tornar o conjunto de dados confiável, cada imagem foi rotulada de forma independente por dois técnicos de laboratório experientes, com um terceiro especialista resolvendo quaisquer discordâncias. Verificações estatísticas mostraram acordo muito forte entre os avaliadores para cada tipo celular maior, incluindo concordância perfeita para alguns. A equipe também aplicou regras rigorosas para decidir quais imagens manter, descartando células borradas, sobrepostas ou mal coradas. As imagens finais têm todas o mesmo tamanho e formato de cor, e estão organizadas em pastas de treino, validação e teste para que outros pesquisadores possam comparar algoritmos de forma justa. Arquivos adicionais vinculam cada imagem a um paciente anônimo, permitindo estudos que testem se um modelo realmente generaliza de uma pessoa para outra.
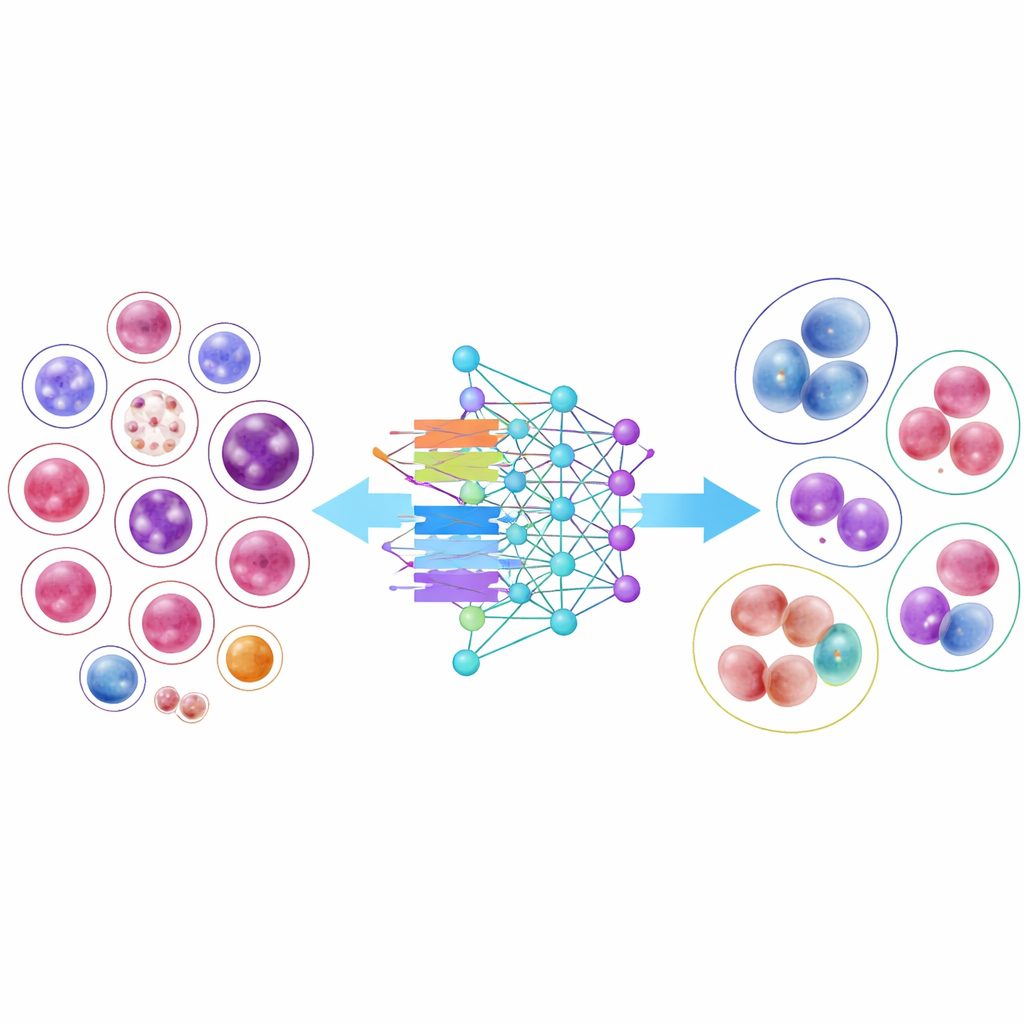
Colocando Modelos de IA à Prova
Para demonstrar a utilidade dessa biblioteca, os pesquisadores treinaram 14 modelos modernos de reconhecimento de imagem, desde redes convolucionais clássicas até arquiteturas mais recentes baseadas em transformers. Vários modelos compactos e eficientes tiveram desempenho surpreendentemente bom, e uma arquitetura, DenseNet-121, classificou corretamente as células em mais de 95% das vezes, em média. Contudo, os resultados também evidenciaram uma dificuldade importante do mundo real: tipos celulares comuns, com milhares de exemplos, foram reconhecidos quase perfeitamente, enquanto células muito raras, com apenas algumas dezenas de imagens, continuaram muito mais difíceis de classificar. Mesmo quando os pesquisadores ajustaram o treinamento para “dar mais atenção” a essas classes escassas, a acurácia geral caiu e os ganhos para os tipos raros foram modestos, ressaltando o desafio de aprender a partir de exemplos limitados.
O Que Isso Significa para Exames de Sangue Futuros
Para não especialistas, a mensagem principal é que este trabalho fornece a experiência visual bruta que sistemas computacionais precisam para se tornar parceiros confiáveis na leitura de esfregaços sanguíneos. Ao reunir uma biblioteca grande, diversa e cuidadosamente verificada de imagens de células sanguíneas e mostrar que muitos modelos de IA diferentes podem aprender com ela, os autores lançam as bases para ferramentas que podem acelerar o diagnóstico, reduzir erros humanos e levar análise no nível de especialistas a clínicas com menos especialistas. Ao mesmo tempo, os resultados mistos em relação a tipos celulares raros nos lembram que mesmo conjuntos de dados grandes têm pontos cegos, e que melhorar o atendimento a pacientes com doenças incomuns ou em estágio inicial exigirá expandir e refinar ainda mais essas coleções de imagens.
Citação: Yarıkan, A.E., Örer, C., Akyıldız, V. et al. A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis. Sci Data 13, 417 (2026). https://doi.org/10.1038/s41597-026-06761-y
Palavras-chave: imagem de células sanguíneas, IA médica, hematologia, aprendizado profundo, conjuntos de dados médicos