Clear Sky Science · pt
Um Conjunto de Dados de Histopatologia em Alta Ampliação para Diagnóstico e Prognóstico do Carcinoma Epidermóide Oral
Por que esta pesquisa é importante
O câncer oral pode passar despercebido, começando como uma pequena ferida na boca e evoluindo para uma doença potencialmente fatal. Os médicos dependem de imagens microscópicas de tecido para avaliar a severidade de um tumor e a probabilidade de recorrência ou disseminação, mas a leitura dessas lâminas é um trabalho lento e exigente. Este estudo apresenta uma nova coleção rica de imagens projetada para ajudar sistemas de inteligência artificial (IA) a interpretar essas lâminas ao lado de patologistas, com o objetivo de, a longo prazo, fornecer aos pacientes respostas mais rápidas e precisas sobre sua doença e opções de tratamento.
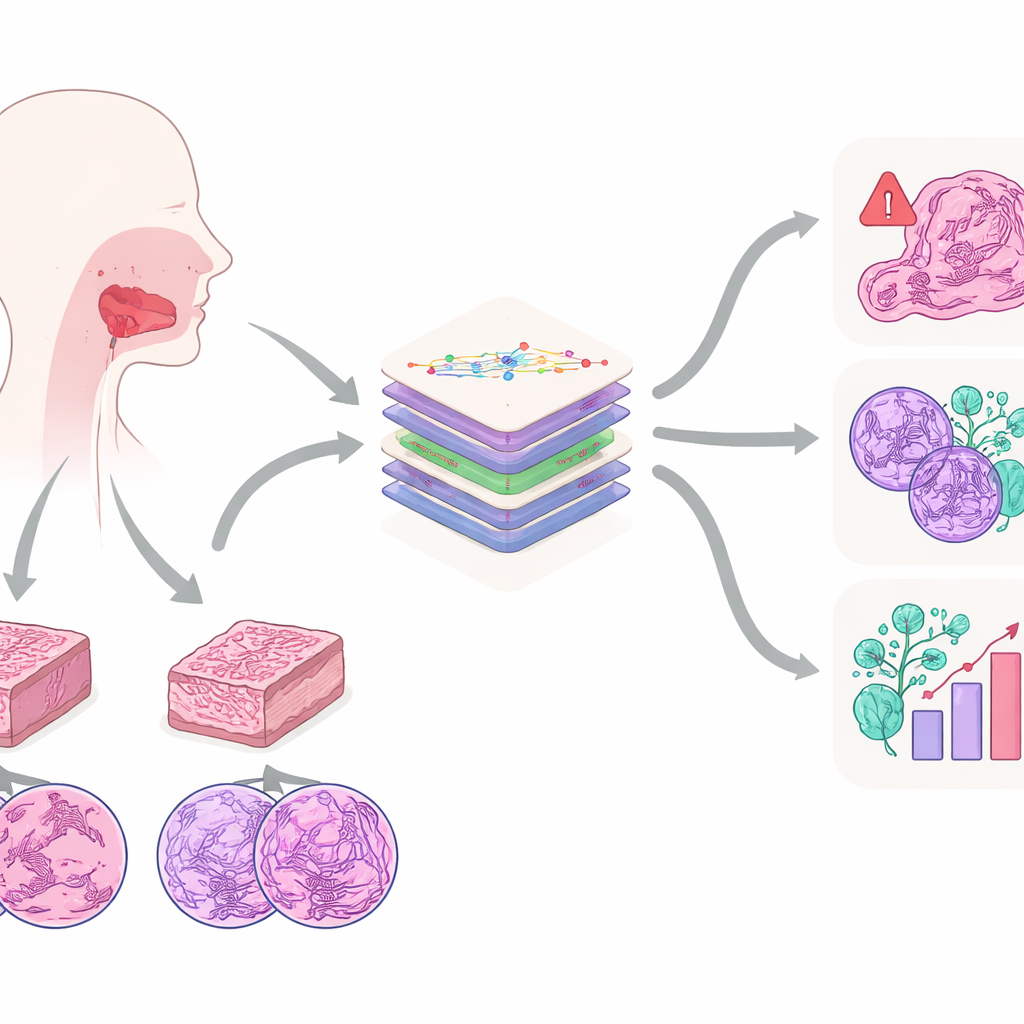
Um olhar mais atento sobre um câncer de boca comum
O trabalho concentra‑se no carcinoma epidermóide oral, um dos cânceres de boca mais frequentes e agressivos. Ele costuma surgir em pessoas com histórico de uso de tabaco ou álcool e pode se espalhar para tecidos adjacentes e para os linfonodos do pescoço. Hoje, o padrão‑ouro para o diagnóstico continua sendo o olhar do patologista sobre lâminas coradas ao microscópio. A partir dessas lâminas, os especialistas avaliam o grau de anormalidade das células, a profundidade de invasão do tumor, se houve infiltração de nervos ou vasos sanguíneos e muitas outras características que influenciam a sobrevida. Os autores argumentam que esses padrões microscópicos contêm muito mais informação do que qualquer humano consegue acompanhar facilmente, tornando‑os um alvo ideal para a IA moderna.
Construindo uma imagem mais rica a partir das imagens de tecido
Para desbloquear essa informação, a equipe criou o conjunto de dados Multi‑OSCC: imagens microscópicas de 1.325 pacientes tratados por câncer oral em um único hospital entre 2015 e 2022. Para cada paciente, patologistas prepararam dois blocos de tecido — um do centro do tumor e outro da sua borda invasiva — e então capturaram imagens em alta resolução em três níveis de ampliação, semelhante a observar uma cidade do avião, do telhado e da esquina da rua. Isso produziu seis imagens cuidadosamente selecionadas por paciente, cada uma contendo estruturas-chave como ninhos de células cancerígenas, camadas de queratina e núcleos celulares altamente anormais. Paralelamente às imagens, os pesquisadores coletaram prontuários detalhados e acompanhamento de longo prazo para verificar quais tumores recidivaram ou se disseminaram.
Seis perguntas que realmente importam aos médicos
O que diferencia o Multi‑OSCC é que ele espelha questões clínicas reais em vez de se concentrar em um único rótulo. Cada paciente no conjunto de dados é anotado para seis desfechos importantes. Um deles é se o tumor recidivou dentro de dois anos após a cirurgia, uma janela crítica em que ocorrem a maioria das recaídas. Outro é se células cancerígenas já haviam alcançado os linfonodos cervicais, informação que orienta decisões sobre cirurgia extensa no pescoço. Quatro rótulos adicionais registram o grau de diferenciação das células tumorais, a profundidade de invasão do tumor e se houve entrada em vasos sanguíneos ou crescimento ao longo de nervos — pistas sutis, mas poderosas, sobre o quão perigoso é o câncer. Esse desenho permite que modelos de IA aprendam não apenas “câncer versus normal”, mas um retrato mais completo de risco e gravidade.
Ensinando IA a ler lâminas complexas
Os pesquisadores então avaliaram como diferentes estratégias de IA lidam com esse conjunto de dados exigente. Compararam várias arquiteturas modernas de reconhecimento de imagens, incluindo redes convolucionais clássicas e modelos mais recentes baseados em transformers, e descobriram que transformers pré‑treinados especificamente em imagens de patologia tiveram o melhor desempenho geral. Testaram maneiras de combinar informações das seis imagens por paciente e descobriram que uma estratégia simples — extrair características de cada imagem e depois concatená‑las — superou esquemas de fusão mais elaborados. Também examinaram como a padronização de cores das colorações afetava o desempenho, revelando que manter a cor original foi vital para prever recorrência, enquanto uma normalização suave de cor ajudou nas outras tarefas diagnósticas.
Limites, surpresas e o que vem a seguir
Uma surpresa foi que treinar um único modelo de IA para responder às seis questões simultaneamente ainda não superou modelos treinados separadamente para cada tarefa. Outra foi que fragmentos microscópicos detalhados, embora ricos em detalhes celulares, ainda carecem da visão arquitetural ampla que imagens de lâmina inteira fornecem. Mesmo assim, modelos treinados nas imagens do Multi‑OSCC claramente superaram modelos que usaram apenas dados clínicos, como idade, hábitos e histórico médico, especialmente na previsão de recorrência tumoral. Os autores posicionam o Multi‑OSCC como um ponto de partida: um conjunto de dados público e bem documentado que outros podem usar para desenvolver e comparar métodos. Para os pacientes, a promessa de longo prazo é que ferramentas futuras construídas sobre esse recurso possam ajudar médicos a identificar com mais confiabilidade quais cânceres orais têm maior probabilidade de retornar ou se espalhar, levando a tratamentos mais personalizados e, em última instância, melhores chances de sobrevivência.
Citação: Guan, J., Guo, J., Chen, Q. et al. A High Magnifications Histopathology Image Dataset for Oral Squamous Cell Carcinoma Diagnosis and Prognosis. Sci Data 13, 371 (2026). https://doi.org/10.1038/s41597-026-06736-z
Palavras-chave: câncer oral, imagens histopatológicas, inteligência artificial, aprendizado profundo, conjuntos de dados de imagens médicas