Clear Sky Science · pt
Um conjunto de dados de citações científicas em Office Actions do Escritório de Patentes dos EUA
Por que as citações de patentes importam para a inovação do dia a dia
Quando você ouve falar de um novo aparelho, medicamento ou tecnologia de energia limpa, geralmente existe um rastro de ideias por trás dele. Grande parte desse rastro está registrada em patentes e nos documentos que elas citam. Este artigo apresenta um grande conjunto de dados novo que revela, com detalhe incomum, em quais trabalhos científicos os examinadores de patentes se apoiam ao decidir se uma invenção merece proteção. Ao abrir essa janela oculta para o processo de exame, os autores fornecem a pesquisadores, formuladores de políticas e até cidadãos curiosos uma nova forma de estudar como o conhecimento científico impulsiona a inovação no mundo real.
Uma camada escondida no processo de patente
A maioria dos estudos sobre patentes considera apenas as citações impressas na capa das patentes concedidas. Essas listas parecem diretas, mas são o resultado final de um complexo vai‑e‑vem entre os requerentes e os examinadores do governo. No decorrer desse processo, os examinadores emitem cartas formais chamadas Office Actions, nas quais explicam por que uma patente deve ser aceita ou rejeitada e referenciam trabalhos anteriores que consideram importantes. Muitos desses itens citados, especialmente artigos científicos, nunca aparecem na patente final. Até agora, eles foram difíceis de acessar em massa, o que significa que a pesquisa em grande parte ignorou esse registro rico sobre como as decisões são realmente tomadas.
Construindo um novo mapa a partir dos Office Actions
Os autores exploram um tesouro de dados de Office Actions divulgados pelo Escritório de Patentes e Marcas dos EUA e hospedados no Google Cloud. A partir de milhões de referências, eles isolam cerca de 850.000 que não apontam para outras patentes, mas sim para fontes externas como artigos de periódicos, livros, sites e manuais de produtos. Eles elaboram um esquema com 14 categorias do dia a dia — que vão desde livros e anais de conferência até páginas web e documentação de produtos — e então treinam um modelo de aprendizado de máquina para classificar cada citação em um desses tipos. Esse modelo, refinado usando exemplos rotulados com a ajuda de um sistema avançado de linguagem, classifica quase 847.000 cadeias de citação únicas.
De referências confusas a registros de pesquisa limpos
Identificar quais citações são científicas é apenas o primeiro passo. Referências do mundo real são confusas: títulos podem estar incompletos, anos digitados incorretamente e números de página embaralhados. Para transformar esse emaranhado em dados utilizáveis, a equipe alimenta as cadeias brutas em uma ferramenta especializada que as analisa em partes como autor, ano, periódico e intervalo de páginas, aplicando regras de limpeza cuidadosas. Em seguida, eles correspondem esses registros limpos ao OpenAlex, um grande banco de dados aberto de publicações científicas, usando duas estratégias. Quando um título está disponível, eles pesquisam pelo título e mantêm apenas correspondências de alta confiança; quando não está, confiam em combinações de nomes de autores, periódico, ano e páginas. Se o OpenAlex não encontra uma correspondência, recorrem ao Crossref, outra fonte importante de identificadores de publicações, e retornam ao OpenAlex usando quaisquer identificadores digitais descobertos.
Quão confiável é o novo conjunto de dados?
Como esse recurso se destina a sustentar estudos futuros, os autores dedicam esforço substancial a testar sua precisão. Seu classificador atribui corretamente as referências ao tipo certo em cerca de 92% dos casos no geral, e tem desempenho especialmente bom nas classes mais comuns, como artigos de periódicos e patentes. Na etapa de correspondência, verificações manuais mostram que buscas por título ficam mais precisas à medida que a pontuação de correspondência aumenta, alcançando percentis na casa dos 90 e poucos no melhor grupo, enquanto buscas baseadas em metadados detalhados são corretas 99% das vezes em uma amostra. Cruzamentos de registros recuperados via Crossref também mostram concordância quase perfeita. Os autores são transparentes sobre pontos mais fracos — como categorias raras, por exemplo teses ou relatórios técnicos — e incentivam os usuários a refiná‑los quando necessário.
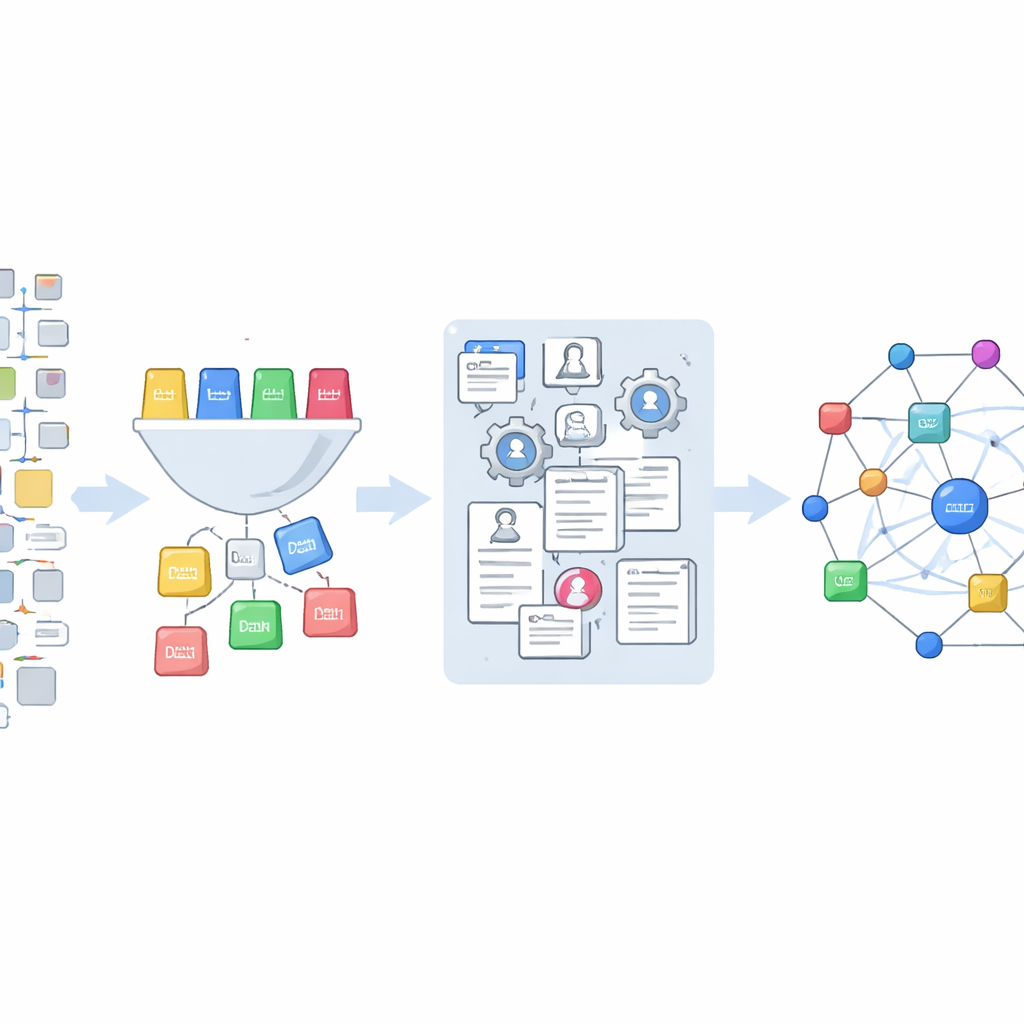
Novas maneiras de estudar como a ciência impulsiona a tecnologia
O conjunto de dados final vincula aproximadamente 265.000 referências científicas extraídas de Office Actions a pedidos de patente individuais nos EUA e a registros ricos de publicações no OpenAlex. Isso permite que pesquisadores façam novos tipos de perguntas: quão intensamente diferentes grupos de examinadores ou áreas tecnológicas dependem de artigos científicos? Quais estudos são considerados importantes durante o exame, mas desaparecem da patente final? Patentes abandonadas recorrem a um recorte diferente do registro científico em comparação com as bem‑sucedidas? Como todo o código e os dados são liberados abertamente, outros podem adaptar as ferramentas, ampliar a cobertura e refinar as classificações. Em termos simples, este trabalho transforma um conjunto obscuro e disperso de documentos legais em um mapa claro e reutilizável de como ciência e tecnologia se encontram dentro do sistema de patentes.
Citação: Higham, K., Kotula, H., Scharfmann, E. et al. A dataset of scientific citations in U.S. patent Office Actions. Sci Data 13, 325 (2026). https://doi.org/10.1038/s41597-026-06720-7
Palavras-chave: citações de patentes, office actions, literatura científica, dados de inovação, OpenAlex