Clear Sky Science · pt
Um Conjunto de Dados de Reconhecimento de Entidades Nomeadas em Chinês para o Patrimônio Cultural Imaterial
Por que proteger tradições vivas precisa de leitura inteligente
Ao redor do mundo, tradições vivas como música folclórica, artesanato e festivais locais correm o risco de desaparecer do cotidiano. Na China, há grandes volumes de textos que descrevem essas práticas, mas a maior parte está em páginas longas na web que pessoas — ou computadores — têm dificuldade para buscar ou analisar. Este estudo apresenta um conjunto de dados em chinês cuidadosamente construído e um modelo avançado de inteligência artificial capaz de identificar automaticamente informações-chave nesses textos, como nomes de ofícios, mestres artesãos, materiais e locais. Juntos, oferecem novas ferramentas para ajudar a preservar e estudar o patrimônio cultural imaterial em escala digital.
Transformando texto confuso em conhecimento organizado
A ideia central do trabalho é uma tecnologia chamada reconhecimento de entidades nomeadas, que ensina computadores a destacar itens importantes no texto: pessoas, localizações, tempos, organizações e assim por diante. Para o patrimônio cultural imaterial, isso também significa reconhecer tipos especiais de entidades, como nomes de projetos de patrimônio, técnicas artesanais específicas e os materiais que utilizam. O problema é que, até agora, não existia um conjunto de dados público voltado para esse domínio em chinês, e sistemas de uso geral tinham dificuldade com descrições vívidas, linguagem poética e expressões regionais encontradas em documentos de patrimônio.
Construindo uma coleção focalizada de textos sobre patrimônio
Para preencher essa lacuna, os autores reuniram um novo conjunto de dados, denominado ICH-NER, a partir da Rede Oficial de Patrimônio Cultural Imaterial da China. Eles concentraram-se em entradas relacionadas ao artesanato — como têxteis tradicionais, cerâmica, metalurgia e escultura — porque essas descrições são ricas em detalhes sobre processos e materiais. Após remover avisos e duplicatas, desenharam oito categorias principais de entidades: nomes de itens de patrimônio, localizações, pessoas, organizações, períodos de tempo, grupos étnicos, materiais e técnicas artesanais. Cada caractere chinês nos textos foi marcado com um código simples indicando se pertence a uma entidade e, em caso afirmativo, de que tipo. No total, o conjunto de dados contém 7.779 amostras e mais de 21.000 entidades rotuladas, tornando-o um referencial sólido para pesquisas futuras.
Regras cuidadosas para rotulagem consistente
Como não existia um sistema de classificação padrão para esse tipo de texto sobre patrimônio, os pesquisadores primeiro elaboraram diretrizes detalhadas com base em listas nacionais de patrimônio e descrições oficiais. Realizaram uma fase piloto para tratar casos delicados, como locais que também fazem parte de nomes de projetos, ou frases aninhadas em que uma entidade está dentro de outra. Um único anotador treinado então rotulou todo o conjunto de dados usando software de código aberto, revisitando repetidamente trabalhos anteriores para corrigir inconsistências. Os dados finais foram divididos em conjuntos de treinamento e desenvolvimento, com atenção especial para manter proporções semelhantes de cada tipo de entidade e uma boa mistura de termos regionais e estilos de escrita em ambas as partes.
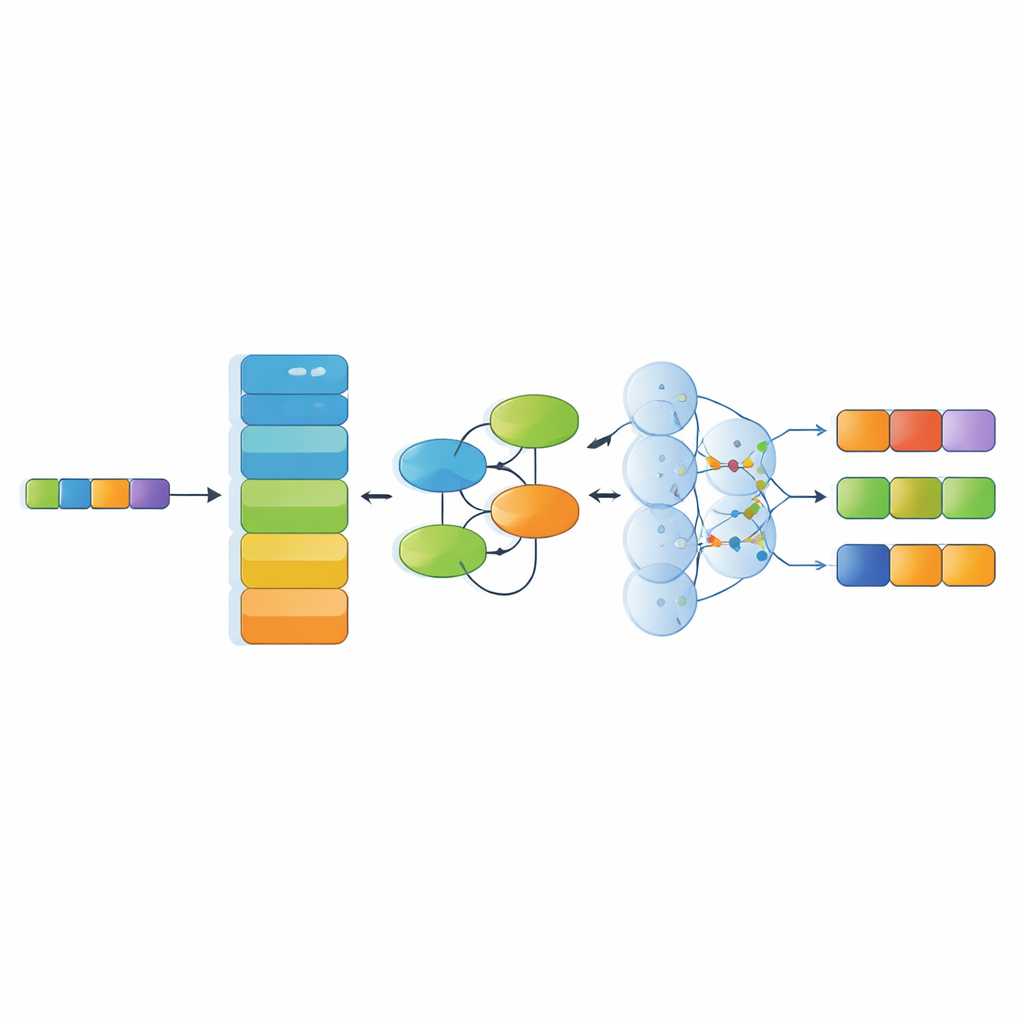
Projetando um modelo de IA ajustado à linguagem do patrimônio
Paralelamente ao conjunto de dados, o estudo propõe um modelo de reconhecimento especializado que combina vários componentes modernos de IA. Primeiro, um codificador de linguagem poderoso (RoBERTa) converte os caracteres chineses em representações numéricas sensíveis ao contexto que refletem como as palavras são usadas no entorno. Em seguida, um módulo de Rede Kolmogorov–Arnold aprende padrões sutis e não lineares — como certos materiais que tendem a acompanhar técnicas ou regiões específicas. Uma camada de atenção multi-cabeça então examina relações ao longo de toda a sentença sob múltiplos ângulos, e, por fim, uma camada de decodificação escolhe a sequência de rótulos de entidade mais provável. Essa arquitetura foi concebida para lidar com sentenças longas e complexas, repletas de metáforas e referências culturais em camadas.
Quão bem o sistema compreende textos sobre patrimônio
Os autores compararam seu modelo com várias linhas de base fortes comumente usadas em pesquisa linguística, incluindo sistemas baseados em redes recorrentes, estruturas em rede (lattice) para texto chinês e um método recente que trata entidades como segmentos refinados passo a passo. No conjunto de dados ICH-NER, métodos que dependem de modelos de linguagem pré-treinados modernos superaram claramente abordagens mais antigas. O sistema combinado RoBERTa–KAN–atenção–decodificador alcançou o melhor equilíbrio geral entre precisão e recall, especialmente para categorias desafiadoras como materiais, organizações e técnicas artesanais, onde os dados são relativamente escassos e as descrições frequentemente são intrincadas ou ambíguas.
O que isso significa para a cultura viva na era digital
Em termos práticos, o novo conjunto de dados e o modelo facilitam que computadores identifiquem quem, o quê, onde e quando a partir de descrições ricas de ofícios tradicionais. Essa informação estruturada pode alimentar grafos de conhecimento, mapas interativos ou ferramentas de busca que ajudam pesquisadores, curadores e o público a explorar como as técnicas se difundem, como certas famílias ou regiões moldam um ofício e como as práticas evoluem ao longo do tempo. Embora o trabalho seja técnico, seu impacto é humano: oferece uma forma de transformar descrições dispersas e presas a textos de tradições vivas em conhecimento organizado que pode melhor apoiar a preservação e o entendimento do patrimônio cultural imaterial.
Citação: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Palavras-chave: patrimônio cultural imaterial, reconhecimento de entidades nomeadas, processamento da língua chinesa, conjuntos de dados culturais, preservação digital