Clear Sky Science · pt
Manifesto de Dados Biomédicos: um mapeamento leve de documentação de dados para aumentar a transparência em IA/ML
Por que Notas de Dados Mais Inteligentes Importam para Sua Saúde
À medida que hospitais e pesquisadores se apressam em usar inteligência artificial para prever doenças e orientar tratamentos, a qualidade dos dados que alimentam essas ferramentas molda discretamente quem se beneficia — e quem pode ficar para trás. Este artigo apresenta uma forma prática de “rotular a caixa” para conjuntos de dados biomédicos, de modo que qualquer pessoa que construa sistemas de IA possa ver rapidamente de onde os dados vieram, quem eles representam e como devem — e não devem — ser usados. Ao simplificar esse tipo de documentação, os autores buscam tornar a IA médica mais justa, mais segura e mais confiável.
As Histórias Ocultas Dentro dos Dados Médicos
A maioria dos grandes conjuntos de dados biomédicos — coleções de resultados de exames, imagens ou desfechos de tratamentos — nunca foi criada com a IA em mente. Frequentemente faltam registros claros sobre como os dados foram coletados, quais pacientes foram incluídos ou o que foi alterado ao longo do tempo. Esses detalhes ausentes podem esconder vieses, como a sub-representação de certos grupos ou o registro inconsistente de informações cruciais. Quando esses dados são usados para treinar sistemas de aprendizado de máquina, as ferramentas resultantes podem funcionar bem para alguns pacientes e mal para outros, reforçando lacunas de atendimento já existentes. Os autores argumentam que uma documentação padronizada e melhor é essencial para descobrir e gerenciar esses riscos antes da implantação de algoritmos.
Combinando as Melhores Ideias em um Guia Simples
Já existem várias abordagens de “fichas” de dados na comunidade de IA, como Datasheets for Datasets, Data Cards e HealthSheets. Cada uma oferece perguntas estruturadas sobre o propósito de um conjunto de dados, seu conteúdo, métodos de coleta e limites. Contudo, foram em sua maioria concebidas por cientistas da computação para conjuntos de dados específicos de IA, e podem ser longas e difíceis para pesquisadores biomédicos ocupados preencherem. Para evitar reinventar a roda, a equipe primeiro mapeou e harmonizou campos de quatro modelos amplamente citados, construindo uma lista consolidada de 136 perguntas que capturavam os conceitos mais importantes eliminando sobreposições. Em seguida, refinaram essa lista para 100 campos agrupados em sete categorias intuitivas, que vão desde informações básicas e formas de uso dos dados até questões como ética, restrições legais e como os rótulos foram criados.
Ouvindo as Pessoas que Usam e Criam os Dados
Em seguida, os pesquisadores pediram a partes interessadas biomédicas do mundo real — incluindo clínicos, cientistas de laboratório, gestores de dados e especialistas computacionais — que avaliassem o quão essencial cada campo de documentação era para seu trabalho. Vinte e três participantes de uma rede de pesquisa oncológica multicêntrica completaram a pesquisa. A equipe agrupou os respondentes em duas “personas” amplas: aqueles mais próximos da coleta de dados no laboratório ou à beira do leito, e aqueles que principalmente gerenciam, curam ou analisam dados. Isso revelou diferenças claras nas prioridades. Por exemplo, ambos os grupos valorizaram muito saber quando um conjunto de dados foi atualizado pela última vez e quando poderia mudar novamente. Mas apenas os gestores de dados e os especialistas computacionais priorizaram fortemente detalhes sobre como os rótulos foram atribuídos ou como seriam futuras atualizações, enquanto clínicos e cientistas de bancada deram mais ênfase aos usos pretendidos e inadequados dos dados.
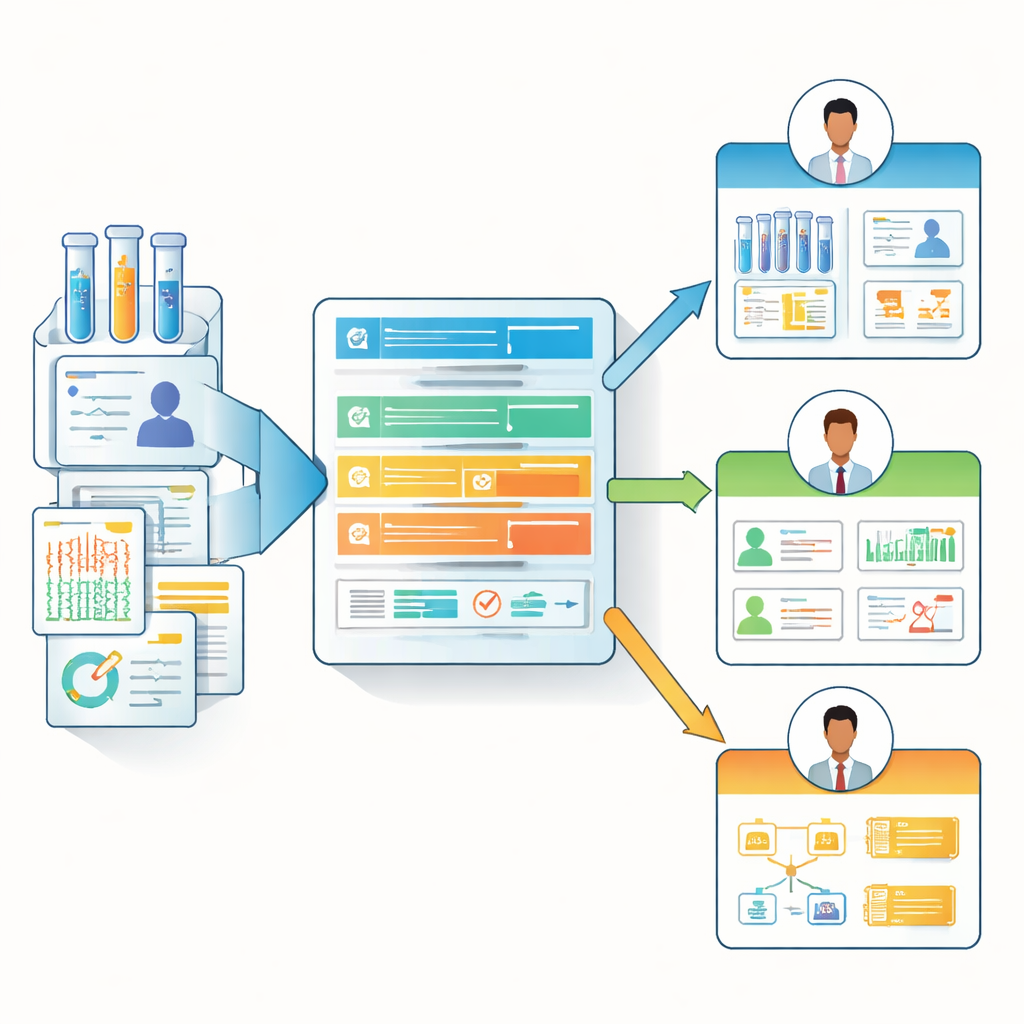
De Tamanho Único a Notas de Dados Sensíveis ao Papel
Com base nesses insights da pesquisa, os autores projetaram o “Manifesto de Dados Biomédicos”, um modelo de documentação leve e baseado na web que se adapta a diferentes papéis. Em vez de obrigar todo contribuidor a preencher uma lista de verificação imensa, o manifesto usa uma hierarquia de perguntas centrais e outras opcionais e mais detalhadas. Ele pode destacar os campos mais relevantes para cada persona — por exemplo, evidenciando a linhagem dos dados e detalhes de atualização para analistas, enquanto enfatiza contexto clínico e restrições para pesquisadores e clínicos de linha de frente. A equipe fornece um formulário pronto para uso (por exemplo, no Microsoft Forms), um modelo de exibição em HTML e um pacote R de código aberto chamado BioDataManifest. Esse software pode transformar automaticamente respostas da pesquisa em páginas de manifesto claras e até extrair informações de grandes repositórios públicos como o Genomic Data Commons e o dbGaP para criar manifestos parciais para conjuntos de dados existentes.
O que Isso Significa para a IA Médica do Futuro
Em última análise, o Manifesto de Dados Biomédicos é uma ferramenta prática para tornar o “miolo” dos conjuntos de dados biomédicos mais fácil de criar, compartilhar e entender. Ao separar a documentação sobre os dados da documentação sobre modelos de IA específicos, e ao ajustar o que é mostrado para diferentes papéis de usuário, a estrutura reduz o ônus sobre os pesquisadores enquanto fornece aos usuários a montante o contexto necessário para avaliar se um conjunto de dados é adequado a um determinado propósito. Em termos práticos, transforma conjuntos de dados médicos opacos em pacotes claramente rotulados, ajudando desenvolvedores de IA a identificar limitações e potenciais vieses antes que afetem pacientes. Se amplamente adotada, esse tipo de documentação reutilizável e sensível ao papel pode tornar a IA biomédica mais transparente, reprodutível e equitativa.
Citação: Bottomly, D., Suciu, C.G., Cordier, B. et al. Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML. Sci Data 13, 414 (2026). https://doi.org/10.1038/s41597-026-06670-0
Palavras-chave: documentação de dados biomédicos, IA responsável na medicina, transparência de conjuntos de dados, viés em aprendizado de máquina, governança de dados