Clear Sky Science · pt
Prevenir que dados de proteômica virem tumbas digitais por meio de responsabilidade coletiva e engajamento comunitário
Por que seus dados médicos não deveriam acabar em um cemitério digital
A medicina moderna depende cada vez mais de enormes conjuntos de dados que descrevem os milhares de proteínas atuando em nossas células. Esses arquivos frequentemente são compartilhados abertamente online, com a promessa de que outros cientistas possam verificar resultados ou fazer novas perguntas sem realizar experimentos adicionais. Mas se os dados são publicados em formatos confusos, sem detalhes essenciais ou dependentes de software proprietário, eles se tornam “tumbas de dados”: visíveis a todos, porém praticamente inúteis. Este artigo mostra como um curso universitário transformou estudantes em detetives de dados para revelar esse problema oculto — e sugere correções simples que poderiam tornar os dados compartilhados realmente reutilizáveis.
Aprender ciência refazendo estudos reais
Na Universidade de Helsinque, alunos de pós‑graduação em um curso de proteômica por espectrometria de massa foram desafiados a algo ambicioso: escolher conjuntos de dados proteicos reais e publicamente disponíveis em um grande repositório e tentar reproduzir as descobertas publicadas. Trabalhando em pequenos times, eles baixaram seis projetos da rede ProteomeXchange, que hospeda resultados de espectrometria de massa de muitos laboratórios ao redor do mundo. Usando um pipeline de análise compartilhado na linguagem R, os estudantes seguiram as mesmas etapas gerais dos pesquisadores originais: identificar proteínas, medir suas abundâncias, limpar os dados e testar quais proteínas mudam entre condições, como tecido doente versus saudável.
Grandes promessas, instruções faltantes
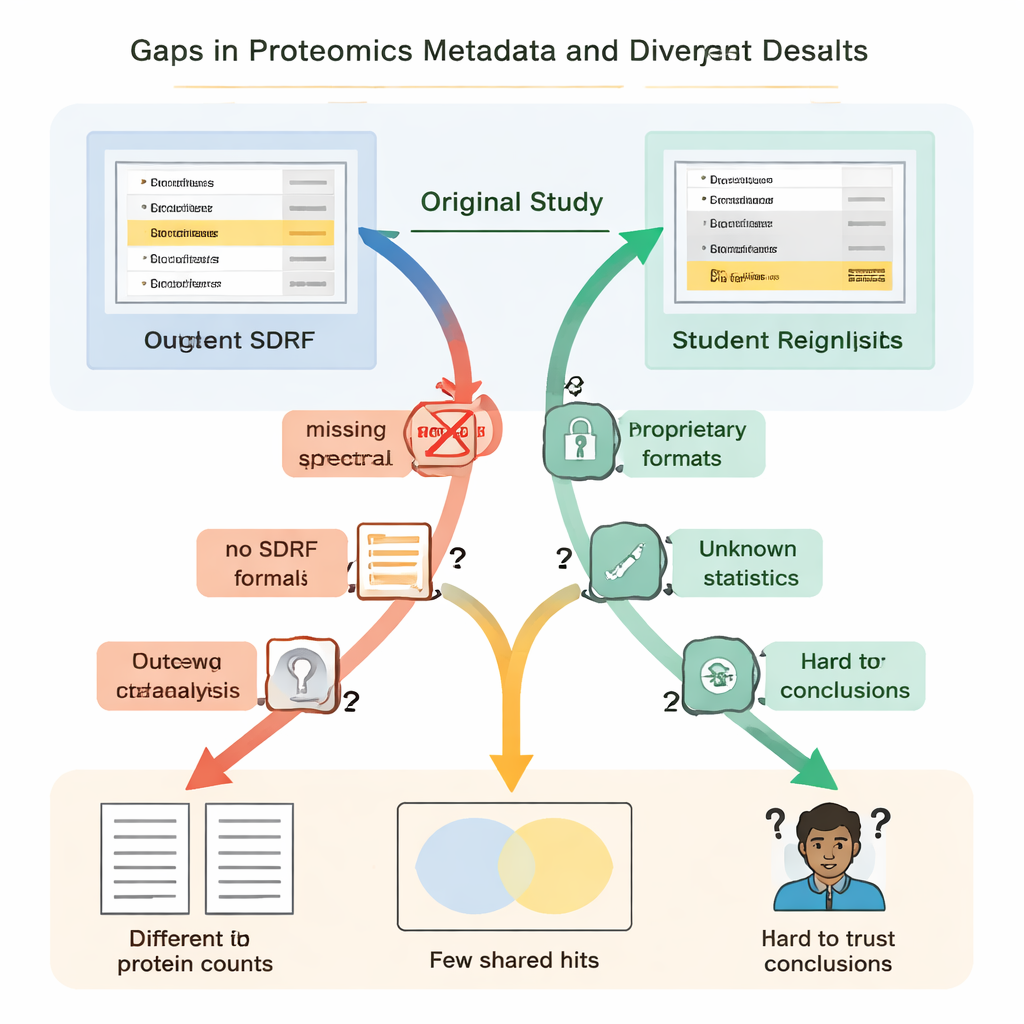
Os estudantes descobriram rapidamente que “aberto” nem sempre significava “reutilizável”. Em todos os casos, instruções essenciais estavam ausentes ou difíceis de encontrar. Links-chave entre amostras e arquivos de dados não eram descritos em um formato simples e legível por máquina, então as equipes tiveram de deduzir quais arquivos brutos correspondiam a quais agrupamentos biológicos lendo os artigos e decifrando nomes de arquivos. Detalhes sobre como falsos positivos eram controlados — como o uso de sequências proteicas “decoy” especiais — estavam ausentes, tornando impossível avaliar rigorosamente quão confiáveis eram as listas de proteínas relatadas. Em vários projetos, os resultados principais estavam trancados em formatos proprietários ou dependiam de software comercial ao qual os estudantes não tinham acesso, forçando‑os a refazer grandes partes da análise do zero.
Quando pequenas lacunas geram grandes diferenças
Essas peças faltantes não eram apenas incômodas; levaram a resultados científicos dramaticamente diferentes. Em um estudo sobre doença renal, os autores originais relataram pouco menos de cinco mil proteínas, enquanto a reanálise dos estudantes — usando uma ferramenta aberta e uma biblioteca espectral construída por eles — encontrou mais de treze mil. Uma proteína destacada no artigo original como especialmente importante não apareceu de forma convincente no arquivo de identificação subjacente e não foi detectada em nenhum momento no fluxo de trabalho dos estudantes. Em outro caso, o estudo original listou 108 proteínas como variando entre condições, mas os alunos, trabalhando a partir dos mesmos dados brutos porém sem informações completas sobre como as estatísticas originais foram feitas, puderam assinalar com confiança apenas 11. Em outros exemplos, a falta de réplicas biológicas nos arquivos enviados significou que testes estatísticos apropriados eram simplesmente impossíveis.
O que um conjunto de dados “reutilizável” deveria realmente conter
A partir desses seis estudos de caso, surgiu um padrão claro: as principais barreiras à reprodutibilidade não eram as máquinas de espectrometria de massa em si, mas a forma como os resultados eram empacotados e compartilhados. Os autores defendem que todo conjunto de dados de proteômica deveria vir acompanhado de um pacote mínimo para reanálise. Isso inclui os dados brutos mais formatos de resultado abertos e padronizados pela comunidade; uma tabela padronizada que vincule cada amostra às suas condições experimentais; resumos básicos de controle de qualidade; quaisquer bibliotecas espectrais ou arquivos de sequência proteica necessários para repetir a busca; e parâmetros completos de análise e código, idealmente armazenados com containers de software versionados. Repositórios, periódicos e revisores poderiam ajudar incentivando ou exigindo que os submetentes forneçam esse pacote desde o início, para que outros não tenham de reconstruir o fluxo de trabalho a partir de pistas dispersas.
Formar cientistas enquanto se corrige o sistema
O próprio curso serviu a um duplo propósito. Para os alunos, ofereceu uma forma prática de dominar métodos complexos de proteômica, estatística e programação, ao mesmo tempo em que revelou quão frágeis as conclusões publicadas podem ser quando a documentação é incompleta. Para a comunidade em geral, as dificuldades enfrentadas pelos estudantes funcionaram como um teste de estresse das práticas atuais de compartilhamento de dados, destacando exatamente onde metadados e registros de análise deixam a desejar. Os autores sugerem que cursos similares poderiam ser oferecidos em outros lugares, transformando salas de aula em motores de controle de qualidade que pressionem continuamente por dados mais claros e transparentes.
De tumbas de dados a recursos vivos
De maneira direta, o artigo conclui que muitos conjuntos de dados proteicos agora depositados em repositórios públicos correm o risco de se tornar cemitérios digitais — experimentos caros cujos resultados não podem ser verificados ou ampliados com confiança. Ainda assim, a solução é relativamente simples: tratar metadados, formatos abertos e código compartilhável como partes integrantes do experimento, não como considerações secundárias. Se pesquisadores, revisores e repositórios insistirem coletivamente em um pacote simples e bem documentado sempre que dados de proteômica forem compartilhados, esses conjuntos de dados podem permanecer “vivos”: prontos para ser reanalisados, combinados com novos estudos e usados para fortalecer a evidência por trás de descobertas biomédicas.
Citação: Vadadokhau, U., Soliman, M., Castillon, L. et al. Preventing Proteomics Data Tombs Through Collective Responsibility and Community Engagement. Sci Data 13, 287 (2026). https://doi.org/10.1038/s41597-026-06614-8
Palavras-chave: proteômica, reprodutibilidade de dados, ciência aberta, espectrometria de massa, compartilhamento de dados de pesquisa