Clear Sky Science · pt
Extração de relações baseada em transformers e normalização de conceitos usando um corpus anotado de ensaios clínicos
Ajudando Médicos a Encontrarem os Pacientes Certos Mais Rápido
Cada ensaio clínico depende de encontrar pacientes que cumpram uma longa lista de condições médicas, tratamentos e períodos de tempo. Hoje, médicos frequentemente precisam ler prontuários eletrônicos e descrições de ensaios manualmente, o que é lento e sujeito a erros. Este artigo apresenta uma grande coleção de textos de ensaios clínicos em espanhol, cuidadosamente verificada, e mostra como a inteligência artificial moderna pode transformar essa linguagem não estruturada em dados organizados, abrindo caminho para pesquisas médicas mais rápidas, justas e precisas.
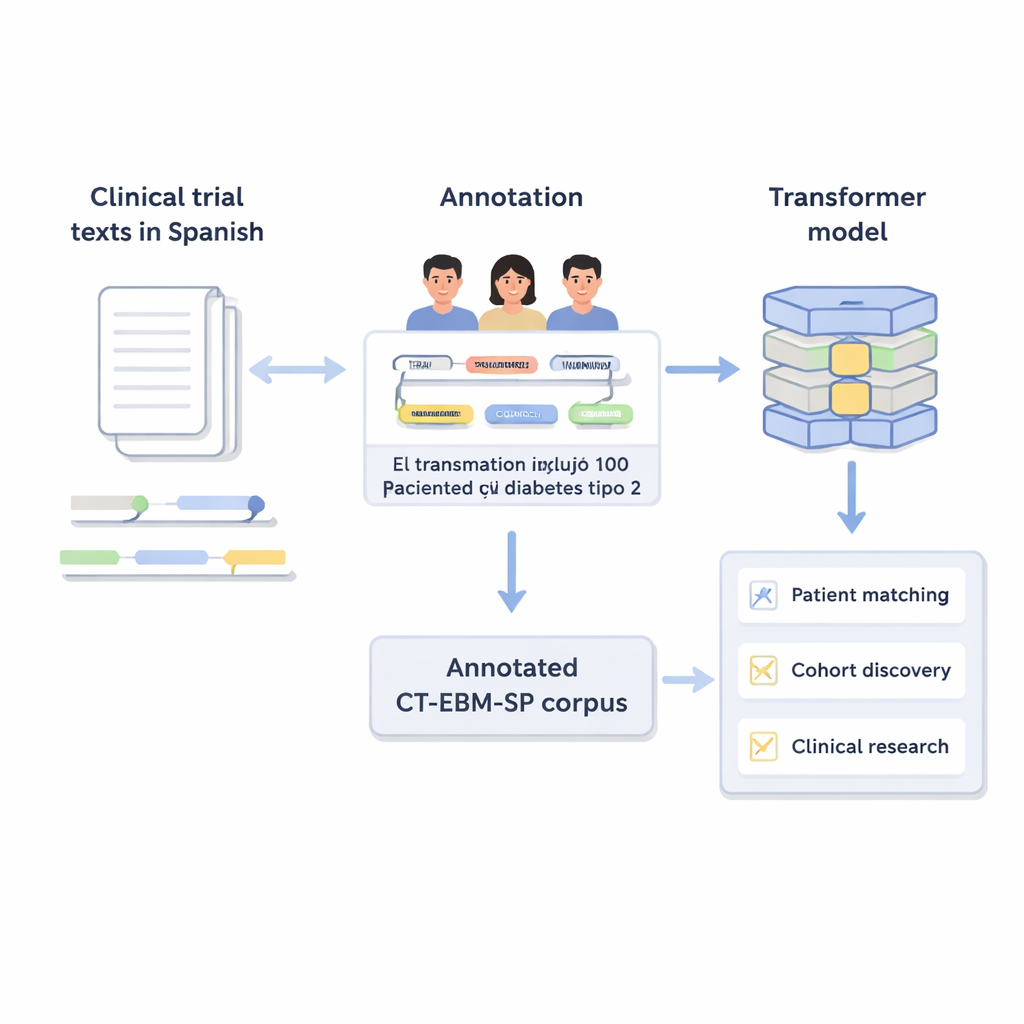
Transformando Texto Livre em Informação Organizada
Ensaios clínicos descrevem quem pode ou não participar usando linguagem médica cotidiana: limites de idade, doenças prévias, resultados de exames e tratamentos realizados. Computadores têm dificuldade com esse tipo de texto livre. Os autores criaram a versão 3 do corpus CT‑EBM‑SP, um conjunto de dados com 1.200 textos de ensaios clínicos em espanhol contendo quase 300.000 palavras. Especialistas humanos revisaram esses textos e marcaram 23 tipos de entidades médicas, como doenças, medicamentos, resultados de testes e expressões temporais, além de indicadores de negação (por exemplo, “sin antecedentes de”) e incerteza. Eles também rotularam 11 atributos que capturam detalhes como se um evento está no passado ou no futuro e se ocorreu no paciente ou em um familiar.
Fazendo Termos Médicos Falar a Mesma Língua
Um desafio importante na medicina é que o mesmo conceito pode ser escrito de muitas formas. Para resolver isso, a equipe vinculou a maioria das entidades marcadas a códigos padronizados do Unified Medical Language System (UMLS), um grande dicionário médico multilíngue. Essa etapa, chamada normalização de conceitos, faz com que diferentes grafias ou frases apontem para o mesmo identificador único. Por exemplo, várias variantes de “25‑hidroxivitamina D” são todas mapeadas para um único conceito UMLS. Ao todo, o corpus inclui mais de 87.000 entidades e mais de 68.000 relações, e cerca de 82% das entidades foram normalizadas com sucesso. Dois especialistas verificaram independentemente esses vínculos, alcançando concordância muito alta, o que indica que as anotações são confiáveis.
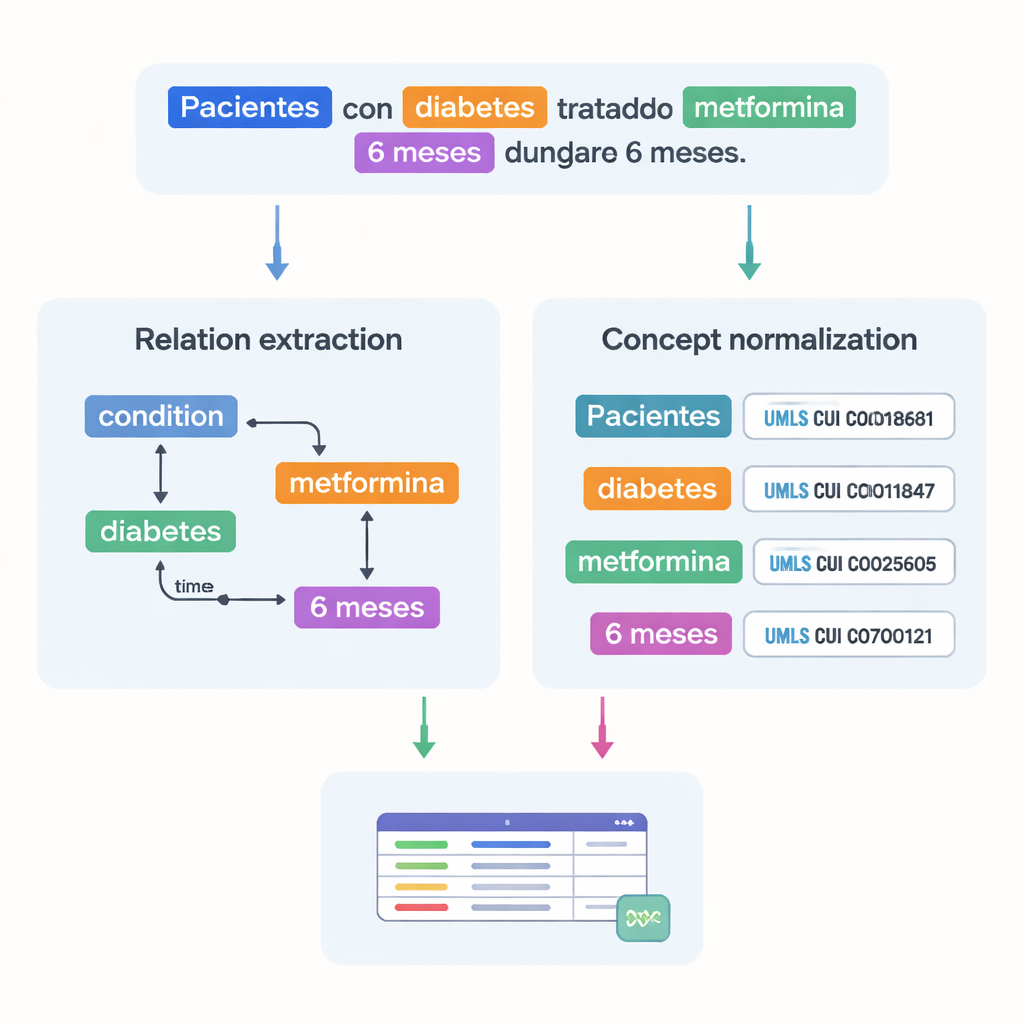
Capturando Como Fatos Médicos se Relacionam
Além de listar termos médicos, o conjunto de dados registra como eles se conectam. Os autores definiram 18 tipos de relações para capturar padrões relevantes em ensaios, como qual dose pertence a qual medicamento, quanto tempo um tratamento dura ou qual condição um paciente apresenta. Relações temporais mostram se um evento ocorre antes ou depois de outro, e outros vínculos marcam onde uma doença ocorre no corpo ou se uma frase expressa negação ou especulação. Juntas, essas relações permitem que computadores construam grafos da situação de um paciente — quem é o paciente, qual condição ele tem, qual tratamento recebe e em que cronologia — em vez de apenas reconhecer palavras isoladas.
Treinando e Testando Modelos de IA Modernos
Para demonstrar a utilidade prática do corpus, os autores ajustaram vários modelos de IA baseados em transformers, incluindo versões multilíngues do BERT e do RoBERTa. Treinaram esses modelos em duas tarefas: extração de relações, que aprende a recuperar os vínculos entre entidades, e normalização de conceitos médicos, que mapeia texto para códigos UMLS. Na extração de relações, o melhor modelo alcançou uma pontuação F1 próxima de 0,88, o que significa que identificou corretamente a maioria das relações com relativamente poucos erros. Para normalização de conceitos, um modelo multilíngue chamado SapBERT, usado sem treinamento adicional, acertou o conceito correto na primeira tentativa em quase 90% das vezes. Esses resultados mostram que conjuntos de dados bem anotados e de tamanho médio podem alimentar modelos precisos e eficientes mesmo sem sistemas de linguagem de propósito geral massivos.
Por Que Esse Recurso Importa para o Cuidado Futuro
O corpus CT‑EBM‑SP e os modelos associados fornecem uma base para ferramentas que podem analisar automaticamente textos de ensaios clínicos em espanhol, compará‑los com prontuários de pacientes e apoiar a descoberta de coortes em hospitais. Como os dados estão alinhados com padrões médicos internacionais e foram cuidadosamente verificados por especialistas, eles também podem ajudar a desenvolver recursos semelhantes para outras línguas com menos ferramentas digitais. Em termos práticos, este trabalho visa facilitar e tornar mais seguro que os pacientes certos sejam oferecidos aos ensaios certos, acelerando descobertas médicas enquanto reduz a carga sobre os profissionais de saúde.
Citação: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Palavras-chave: ensaios clínicos, mineração de texto médico, saúde na Espanha, modelos transformer, medicina baseada em evidências