Clear Sky Science · pt
CNeuroMod-THINGS, um conjunto de dados fMRI densamente amostrado para neurociência visual
Por que olhar imagens pode revelar como nossas mentes funcionam
Todo dia, nossos olhos captam milhares de imagens — de xícaras de café e smartphones a cães, árvores e ruas cheias. Nos bastidores, nossos cérebros reconhecem rapidamente o que vemos e frequentemente lembram disso mais tarde. O projeto CNeuroMod-THINGS buscou capturar essa atividade oculta em detalhes extraordinários, criando um dos conjuntos de dados cerebrais mais profundamente medidos já coletados enquanto pessoas olham imagens do mundo real. Esse recurso destina-se a impulsionar a próxima geração de pesquisas sobre o cérebro e a inteligência artificial.
Construindo uma biblioteca rica de respostas cerebrais
Em vez de escanear centenas de voluntários uma ou duas vezes, a equipe escaneou repetidamente apenas quatro participantes altamente dedicados. Cada pessoa retornou entre 33 e 36 visitas, somando cerca de 200 horas de imageamento cerebral no projeto mais amplo CNeuroMod e dezenas de horas dedicadas apenas às imagens. Durante essas sessões, os voluntários viram até 4.320 fotografias distintas extraídas da coleção de imagens THINGS, que abrange 720 categorias de objetos cotidianos, como ferramentas, animais, veículos e móveis. Essa escolha cuidadosa de imagens garante que muitos cantos do nosso mundo visual estejam representados, e não apenas alguns objetos populares.

Um jogo de memória dentro do aparelho de ressonância
Para manter os participantes engajados e sondar a memória, os pesquisadores transformaram a visualização das imagens em um jogo contínuo de reconhecimento. Em cada ensaio, uma única imagem aparecia no centro da tela enquanto a pessoa estava deitada em um scanner de ressonância magnética. Usando um controlador personalizado no estilo videogame, os participantes informavam se acreditavam que a imagem era nova ou já havia sido vista antes, e qual era seu grau de confiança nesse julgamento. A maioria das imagens foi mostrada três vezes: uma na primeira exposição, outra poucos minutos depois na mesma visita e mais uma em uma visita posterior, muitas vezes cerca de uma semana depois. Esse desenho permitiu à equipe comparar memória de curto e longo prazo para exatamente as mesmas imagens enquanto acompanhavam as mudanças correspondentes na atividade cerebral.
Capturando sinais detalhados da visão e da memória
O conjunto de dados vai muito além de medidas simples de “ligado/desligado” da atividade cerebral. Os autores usaram métodos avançados de análise para estimar uma resposta separada para cada ensaio e cada imagem em cada pequeno pixel tridimensional do escaneamento cerebral. Também monitoraram para onde as pessoas estavam olhando usando câmeras de rastreamento ocular, registraram respiração e frequência cardíaca e mediram o movimento da cabeça. Verificações de qualidade mostram que os sinais são notavelmente estáveis: os participantes responderam em quase todos os ensaios, mantiveram o olhar próximo ao centro da tela e se movimentaram muito pouco. Em áreas visuais-chave — regiões conhecidas por responder fortemente a rostos, corpos ou cenas — a mesma imagem produziu padrões de atividade altamente consistentes cada vez que apareceu. Esses padrões foram fortes o bastante para que, quando as respostas foram plotadas em um mapa simplificado bidimensional, imagens com significados semelhantes (por exemplo, animais ou veículos) tendessem a se agrupar.
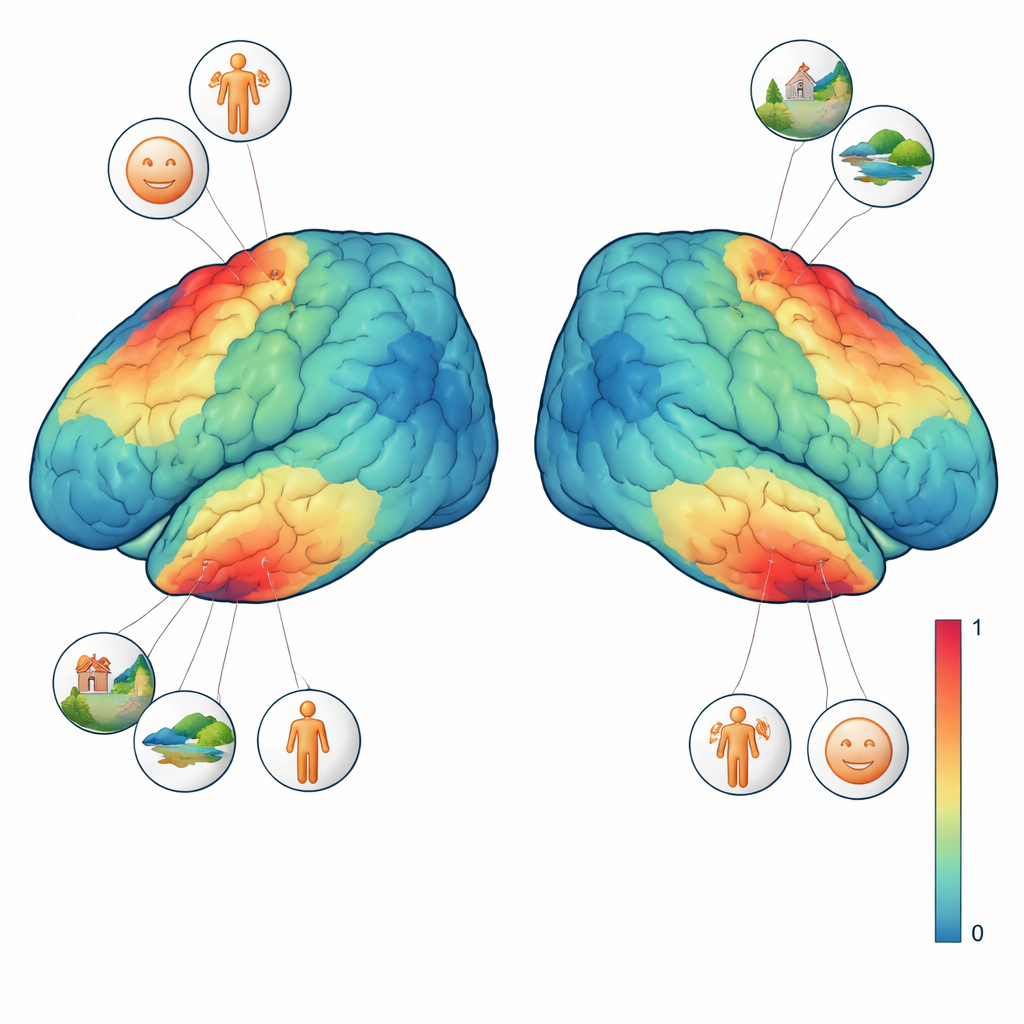
Mapeando o que diferentes regiões cerebrais valorizam
Para interpretar melhor esses sinais, três dos quatro participantes completaram testes visuais adicionais. Em um, formas varrentes moviam-se sobre um fundo texturizado para revelar qual parte do campo visual cada região cerebral “vê”. Em outro, blocos curtos de rostos, lugares, partes do corpo, personagens e objetos genéricos foram mostrados para localizar regiões que preferem um tipo de imagem em relação a outros. Combinando essas tarefas localizadoras com o experimento principal, a equipe pôde fazer perguntas precisas, por exemplo: um único voxel responde mais quando um rosto está presente ou quando a cena inteira é visível? Eles descobriram que as regiões seletivas para rostos responderam mais fortemente sempre que qualquer tipo de rosto aparecia, enquanto uma região seletiva para cenas preferia imagens com fundos ricos, como quartos, ruas ou paisagens, mesmo quando não havia pessoas visíveis. Essas preferências finamente detalhadas emergiram ao nível de imagens individuais e mesmo de voxels únicos.
Uma base para modelos de visão mais inteligentes
No seu cerne, o CNeuroMod-THINGS é um recurso público cuidadosamente curado em vez de um resultado isolado. Todos os dados cerebrais, rastreamento ocular, respostas comportamentais, anotações de imagens e códigos de análise são compartilhados livremente sob uma licença aberta. Como as mesmas quatro pessoas foram escaneadas em muitas outras tarefas — assistindo a filmes, jogando videogames, ouvindo histórias — os pesquisadores agora podem construir modelos detalhados e específicos por pessoa que conectem experimentos controlados a experiências mais naturais. Para não especialistas, a conclusão é que agora temos uma “tabela de consulta” de alta resolução que mostra como um cérebro humano real responde a milhares de imagens cotidianas. Isso ajudará cientistas a testar ideias sobre percepção visual e memória e orientará o desenho de sistemas de visão artificial que vejam o mundo um pouco mais como nós.
Citação: St-Laurent, M., Pinsard, B., Contier, O. et al. CNeuroMod-THINGS, a densely-sampled fMRI dataset for visual neuroscience. Sci Data 13, 141 (2026). https://doi.org/10.1038/s41597-026-06591-y
Palavras-chave: fMRI, percepção visual, reconhecimento de objetos, dados cerebrais, memória