Clear Sky Science · pt
Conjunto de Dados Linguísticos Kymata Soto: um conjunto eletro-magnetoencefalográfico para processamento de fala natural
Ouvindo como o cérebro escuta conversas reais
A maior parte do que dizemos e ouvimos no dia a dia são conversas informais, não palavras isoladas ou frases lidas cuidadosamente. Ainda assim, grande parte da pesquisa cerebral sobre linguagem se baseou em tarefas artificiais. O Conjunto de Dados Linguísticos Kymata Soto muda isso ao oferecer uma coleção rica e aberta de gravações cerebrais de pessoas simplesmente ouvindo discussões animadas no rádio em inglês e russo, fornecendo aos cientistas uma nova janela poderosa sobre como nossos cérebros processam a fala natural.
Uma nova biblioteca de respostas cerebrais à fala real
Este projeto reúne dois métodos avançados de registro cerebral — eletroencefalografia (EEG) e magnetoencefalografia (MEG) — de 35 adultos: 20 falantes nativos de inglês e 15 falantes nativos de russo. Enquanto permaneciam em silêncio e ouviam cerca de seis minutos e meio de conversa no estilo radiofônico em sua língua, a atividade cerebral foi registrada a mil amostras por segundo. Cada pessoa ouviu o mesmo áudio várias vezes, permitindo aos pesquisadores fazer médias entre as repetições e destacar respostas cerebrais confiáveis em meio ao ruído de fundo. O resultado é um registro detalhado e sincronizado no tempo de como o cérebro reage, momento a momento, enquanto as pessoas seguem uma discussão em andamento.

Conversas sobre sorvete e café
Em vez de usar histórias clássicas ou frases artificiais, a equipe escolheu tópicos envolventes, porém cotidianos: a história do sorvete para os ouvintes de inglês e a história do café colombiano para os ouvintes de russo. Ambas as gravações vieram de discussões em estúdio da BBC envolvendo três falantes (dois homens e uma mulher). As conversas foram editadas para cerca de 400 segundos e apresentadas em níveis de audição confortáveis por meio de fones. Após cada repetição, os participantes responderam a uma ou duas perguntas simples de múltipla escolha sobre o conteúdo — o suficiente para garantir que permanecessem atentos e seguissem a história, não para testá‑los de forma agressiva.
Manter os olhos ocupados, mas a mente na audição
Enquanto os participantes ouviam, eles fixavam o olhar em um cruzamento central na tela. Ao redor, nuvens de pontos coloridos flutuavam e mudavam de forma aparentemente aleatória. Esses pontos em movimento cumpriam duas funções: ajudavam a manter o olhar das pessoas estável, o que melhora a qualidade dos dados, e criavam padrões visuais controlados de movimento e cor que outros pesquisadores podem analisar posteriormente. Importante: os pontos não foram sincronizados com o conteúdo da fala, de modo que não “ilustravam” a história nem adicionavam significado, mas ofereciam um fundo visual consistente que pode ser estudado junto com os sons.
De sinais cerebrais brutos a dados prontos para uso
Os pesquisadores documentaram cuidadosamente cada parte do experimento e organizaram o conjunto de dados usando um padrão internacional para dados cerebrais chamado BIDS. Para cada voluntário, há gravações brutas de EEG e MEG, marcadores de tempo para quando o áudio começou, eventos visuais segundo a segundo e segmentos de prática. A equipe também fornece os arquivos de áudio originais, transcrições completas e temporizações precisas de quando cada palavra e até cada som individual da fala começou. Incluem scripts para que outros possam reproduzir automaticamente os mesmos trechos de áudio usados. Para o grupo de inglês, são compartilhadas imagens de ressonância magnética (MRI) anonimadas para que as respostas cerebrais possam ser mapeadas na anatomia individual; para o grupo russo, o consentimento não permitiu o compartilhamento de imagens de MRI, de modo que os usuários são aconselhados a confiar em modelos cerebrais médios padrão.
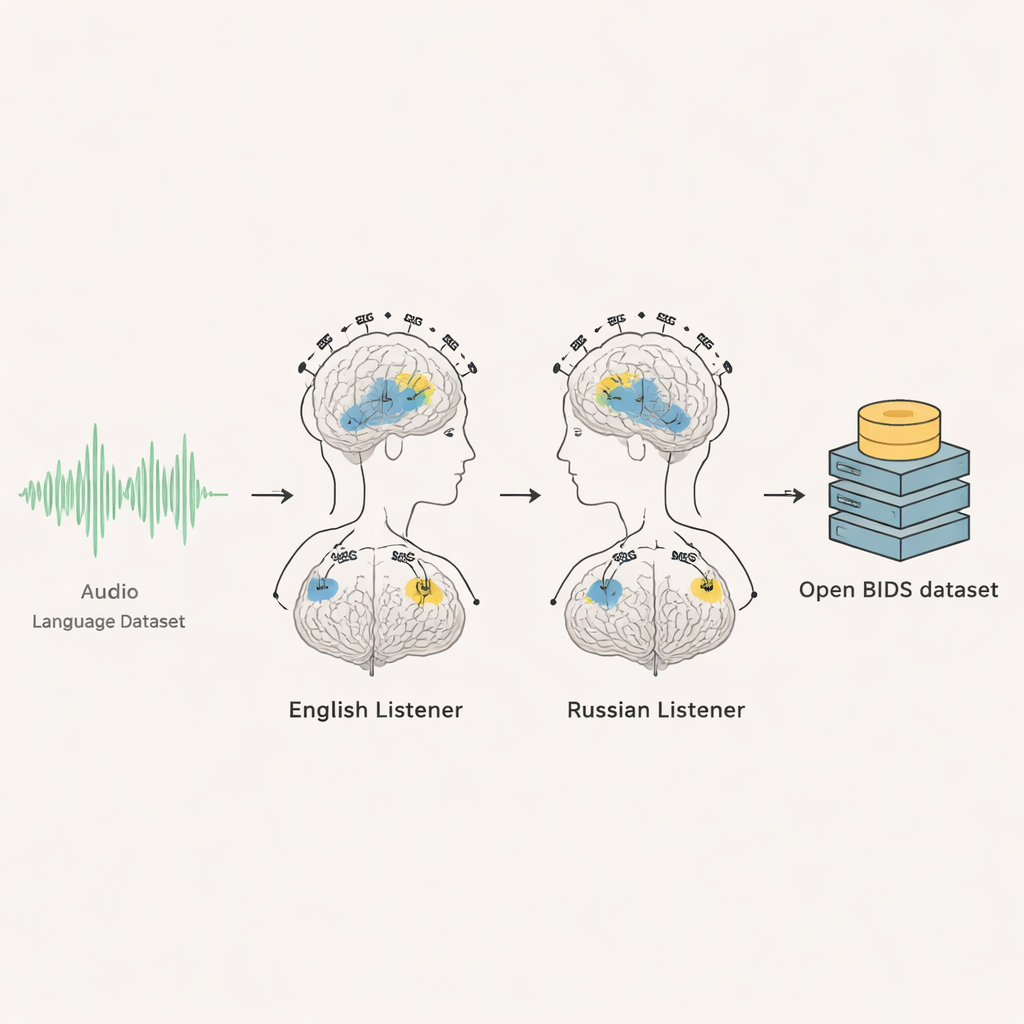
Verificando se os sinais fazem sentido
Para garantir que os dados sejam cientificamente confiáveis, os autores executaram análises de validação focadas em como o cérebro acompanha mudanças na intensidade sonora ao longo do tempo. Eles transformaram o áudio em várias descrições matemáticas de “variação temporal de intensidade” e então examinaram onde e quando as respostas cerebrais se alinharam com esses padrões de intensidade. Para ouvintes de inglês e de russo, o cérebro mostrou padrões de tempo semelhantes, consistentes com o que foi relatado em trabalhos anteriores. Esse acordo entre idiomas e com estudos passados é um forte indicativo de que as gravações são limpas, confiáveis e prontas para que outros as utilizem como base.
Por que isso importa para pesquisas futuras sobre cérebro e linguagem
Para não especialistas, a ideia principal é que este conjunto de dados é um novo recurso comum que permite a muitas equipes de pesquisa estudar como a fala real e espontânea é processada no cérebro. Por ser aberto, bem anotado e gravado em dois idiomas diferentes, pode suportar projetos que vão desde questões fundamentais sobre como compreendemos uma conversa, até comparações entre línguas e esforços ambiciosos para decodificar a fala diretamente da atividade cerebral. Em suma, o Conjunto de Dados Linguísticos Kymata Soto trata menos de responder a uma única pergunta e mais de fornecer à comunidade científica uma base compartilhada e de alta qualidade para explorar como nossos cérebros dão sentido às conversas que preenchem nossa vida cotidiana.
Citação: Yang, C., Parish, O., Klimovich-Gray, A. et al. Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing. Sci Data 13, 254 (2026). https://doi.org/10.1038/s41597-026-06579-8
Palavras-chave: cérebro e linguagem, percepção da fala, EEG MEG, conversa naturalista, dados abertos de neuroimagem