Clear Sky Science · pt
Alinhamento semântico do modelo de metadados do German Human Genome-Phenome Archive no campo da genômica na Europa
Por que compartilhar dados genômicos precisa de mais do que apenas arquivos
A medicina moderna depende cada vez mais da leitura do nosso DNA para diagnosticar doenças e adaptar tratamentos. Mas o verdadeiro potencial da genômica surge quando dados de muitos hospitais e países podem ser combinados. Isso só funciona se cada conjunto de dados for descrito de maneira clara e compatível e se leis de privacidade como o GDPR europeu forem rigorosamente respeitadas. Este artigo explica como o German Human Genome-Phenome Archive (GHGA) está construindo um “sistema de descrição” detalhado para estudos genômicos, de modo que dados valiosos possam ser encontrados, compreendidos e compartilhados com segurança por toda a Europa.
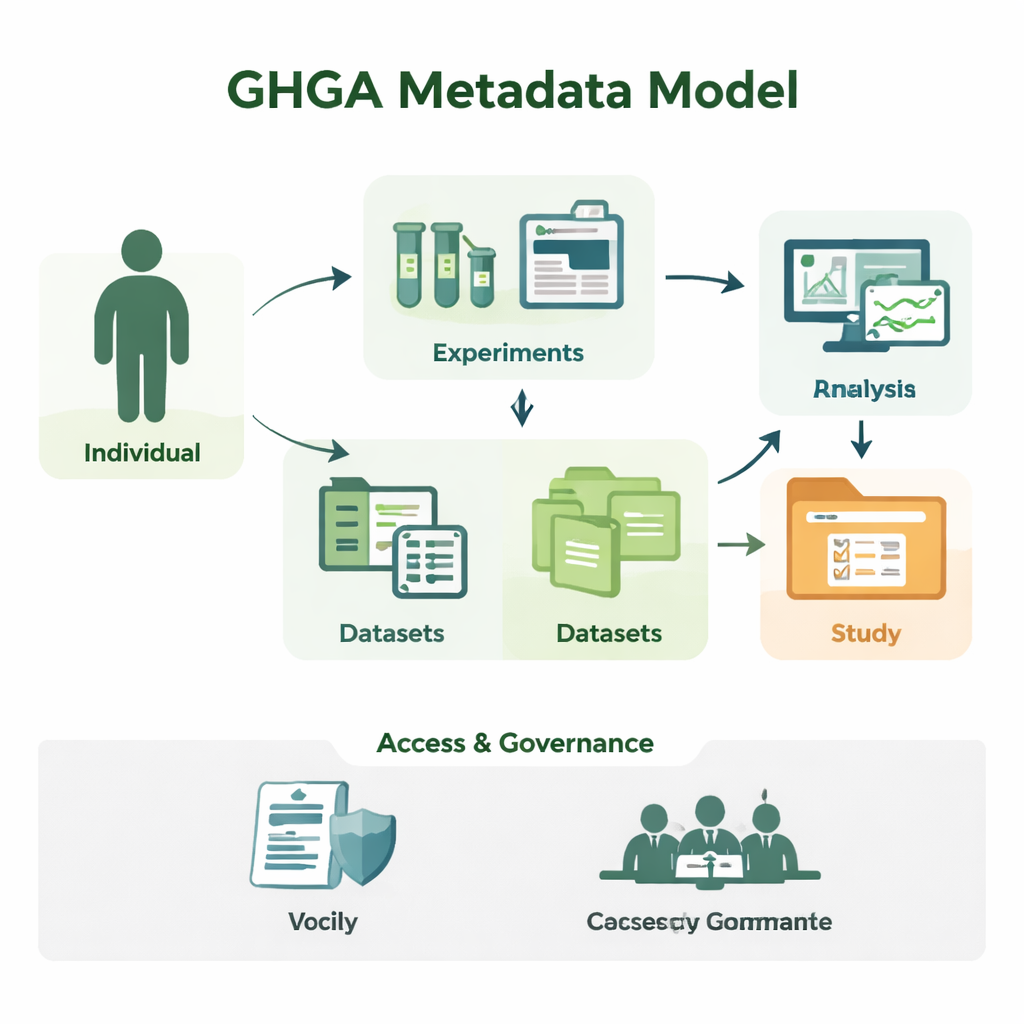
Das sequências brutas para estudos que façam sentido
A pesquisa genômica produz enormes quantidades de dados de sequência, mas isoladamente um arquivo de letras de DNA é sem sentido. Pesquisadores precisam saber de quem veio a amostra, qual tecido foi usado, como o experimento foi realizado e em que condições os dados podem ser reutilizados. O GHGA captura essas informações contextuais como metadados. Seu modelo organiza os metadados em 16 blocos de construção, como a pessoa participante do estudo (o “Indivíduo”), a amostra coletada, o experimento e a análise realizados, os arquivos de dados gerados, e os conjuntos de dados e estudos que os agrupam. Ao separar detalhes científicos de aspectos administrativos, como condições de acesso, o modelo reflete como um laboratório real e um portal de dados funcionam, mas de uma forma que computadores conseguem processar de maneira confiável.
Manter os dados úteis sem identificar as pessoas
Como o GHGA lida com dados sensíveis de saúde humana, a equipe teve de projetar o modelo para ser cientificamente rico sem facilitar a identificação de qualquer pessoa por trás dos dados. As regras do GDPR europeu dizem que informações que possam razoavelmente ser vinculadas a um indivíduo contam como dados pessoais, mesmo se nomes forem removidos. O artigo descreve uma análise cuidadosa de privacidade que mostrou como a combinação de detalhes como idade, CEP e diagnósticos raros pode revelar identidades. Em resposta, o portal público do GHGA evita dados de localização muito granulares, agrupa idades em faixas amplas em vez de anos exatos e agrega códigos de diagnóstico detalhados em categorias mais grossas. Assim, os pesquisadores ainda conseguem avaliar se um conjunto de dados pode ser relevante para seu trabalho, enquanto o esforço necessário para identificar uma pessoa torna-se irrealista.
Verificando compatibilidade com o ecossistema genômico europeu
Para ser realmente útil, os metadados do GHGA precisam se encaixar em uma rede europeia mais ampla de arquivos e ferramentas genômicas. Os autores, portanto, compararam seu modelo, item por item, com quatro outros frameworks amplamente usados: duas versões do European Genome-phenome Archive (EGA), o padrão ISA-tab e o modelo FAIR Genomes da saúde holandesa. Eles realizaram um “crosswalk” detalhado que perguntou, para cada campo do GHGA, se havia um equivalente nos outros modelos e vice-versa. Concluíram que a maioria das propriedades-chave do GHGA tem contrapartes claras em outros locais, especialmente para descrever estudos, amostras, experimentos, análises e formatos de arquivo. Isso significa que conjuntos de dados do GHGA podem ser compreendidos e integrados junto com dados armazenados em outros sistemas europeus.
Encontrando terreno comum – e o que ainda falta
A partir dessa comparação, a equipe extraiu 25 campos de metadados “consenso” que aparecem em pelo menos três dos cinco modelos. Esses campos cobrem o essencial, como o sexo e o estado de saúde dos participantes, o tecido utilizado, o tipo de sequenciamento e o instrumento, o método de análise, formatos de arquivo, e descrições básicas do estudo e dados de contato. Esses campos compartilhados alinham-se com diretrizes mínimas de relato existentes e podem servir como uma lista de verificação básica para quem projeta novos portais de dados genômicos. Ao mesmo tempo, a análise revelou informações que alguns modelos coletam e que o GHGA atualmente omite ou aceita apenas em formato flexível de texto livre, como as datas exatas de amostragem e sequenciamento, diagnósticos excluídos e nomes de contato detalhados. Muitas dessas omissões são trade-offs deliberados em favor da privacidade e anonimato.
O que isso significa para a pesquisa em saúde futura
No geral, o estudo mostra que o modelo de metadados do GHGA é detalhado, flexível e fortemente alinhado com as práticas internacionais, enquanto permanece dentro das rígidas regras de privacidade europeias. Já cobre todos os campos que outros arquivos tratam como obrigatórios e pode ser estendido para novas tecnologias, como omicas de célula única e espaciais. Ao oferecer uma maneira clara de descrever quem e o que envolve um estudo genômico, como os dados foram produzidos e em quais condições podem ser reutilizados, o GHGA ajuda a transformar silos de dados isolados em um recurso de pesquisa conectado. Para pacientes, isso aumenta as chances de que seus dados, uma vez doados, possam contribuir com segurança para descobertas e tratamentos melhores além-fronteiras por muitos anos.
Citação: Mauer, K., Iyappan, A., Parker, S. et al. Semantic alignment of the German Human Genome-Phenome Archive metadata model in Europe’s genomics field. Sci Data 13, 242 (2026). https://doi.org/10.1038/s41597-026-06575-y
Palavras-chave: compartilhamento de dados genômicos, padrões de metadados, privacidade e GDPR, GHGA, medicina personalizada