Clear Sky Science · pt
SEA CDM: Modelo Comum de Dados Study-Experiment-Assay e Bancos de Dados para Integração e Análise de Dados entre Domínios
Por que organizar dados de laboratório importa para todos nós
A medicina moderna é alimentada por montanhas de dados experimentais — desde ensaios de vacinas e estudos de infecção até genômica do câncer. Ainda assim, esses dados frequentemente ficam trancados em formatos incompatíveis, dificultando que cientistas combinem resultados e identifiquem padrões importantes, como quem responde melhor a uma vacina ou por que algumas pessoas têm mais efeitos colaterais. Este artigo descreve uma nova forma de organizar e conectar experimentos biomédicos diversos para que pesquisadores possam formular perguntas mais abrangentes e obter respostas mais rápidas e confiáveis que, em última instância, influenciem como prevenimos e tratamos doenças.
Uma linguagem comum para experimentos
Diferentes grupos de pesquisa e bancos de dados tendem a descrever seus estudos à sua maneira, mesmo quando realizam trabalhos muito semelhantes. Um banco pode se concentrar em ensaios de vacinas, outro na atividade gênica em células únicas e um terceiro em desfechos clínicos, cada um usando rótulos e estruturas diferentes. O Study–Experiment–Assay Common Data Model, ou SEA CDM, oferece uma “gramática” compartilhada e simples para todos esses esforços. Ele divide qualquer projeto biomédico em três etapas conectadas: o estudo geral que formula uma pergunta, os experimentos realizados em pessoas ou animais, e os ensaios — como exames de sangue ou medidas de expressão gênica — que geram resultados. Ao redor dessas etapas, o modelo também padroniza elementos chave como quem ou o que foi estudado, quais amostras foram coletadas, quais tratamentos foram aplicados e quais análises foram realizadas. 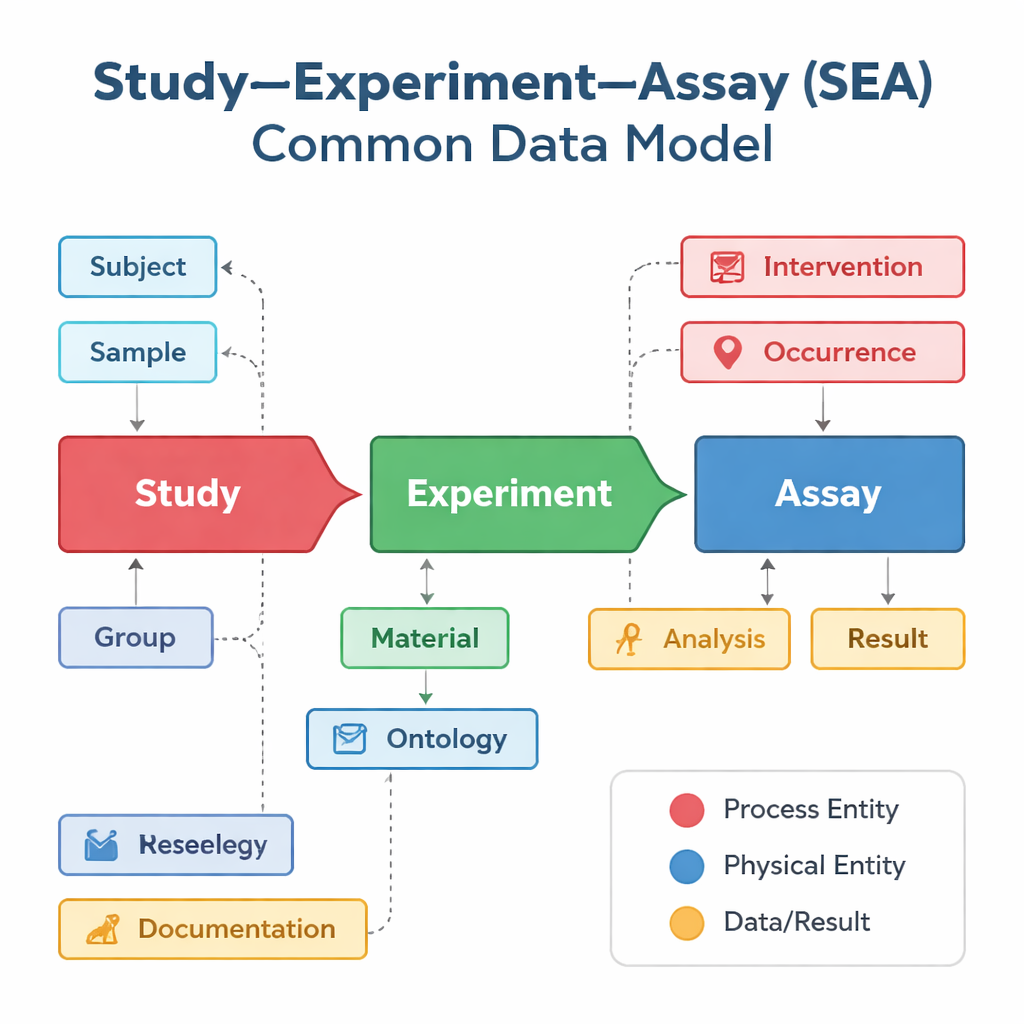
Ontologias: transformando rótulos em conhecimento
Alinhar apenas os nomes das colunas não basta; o mesmo conceito pode ser chamado de formas diferentes em lugares distintos. O SEA CDM apoia-se em vocabulários curados conhecidos como ontologias para garantir que “vacina contra gripe”, “vacina inativada trivalente contra influenza” e um nome comercial como “Fluzone” sejam reconhecidos como ideias relacionadas. Essas ontologias são estruturadas como árvores familiares de termos médicos e biológicos. Como o SEA CDM associa um identificador oficial de uma ontologia a cada variável — como uma doença, tipo celular ou vacina — os computadores podem seguir automaticamente essas árvores, localizar todos os registros relevantes e até inferir relações. Por exemplo, uma consulta simples pode extrair todos os estudos que usaram qualquer vacina trivalente contra influenza dentre centenas de produtos nomeados, permitindo buscas semânticas poderosas que vão muito além da simples correspondência por palavras-chave. 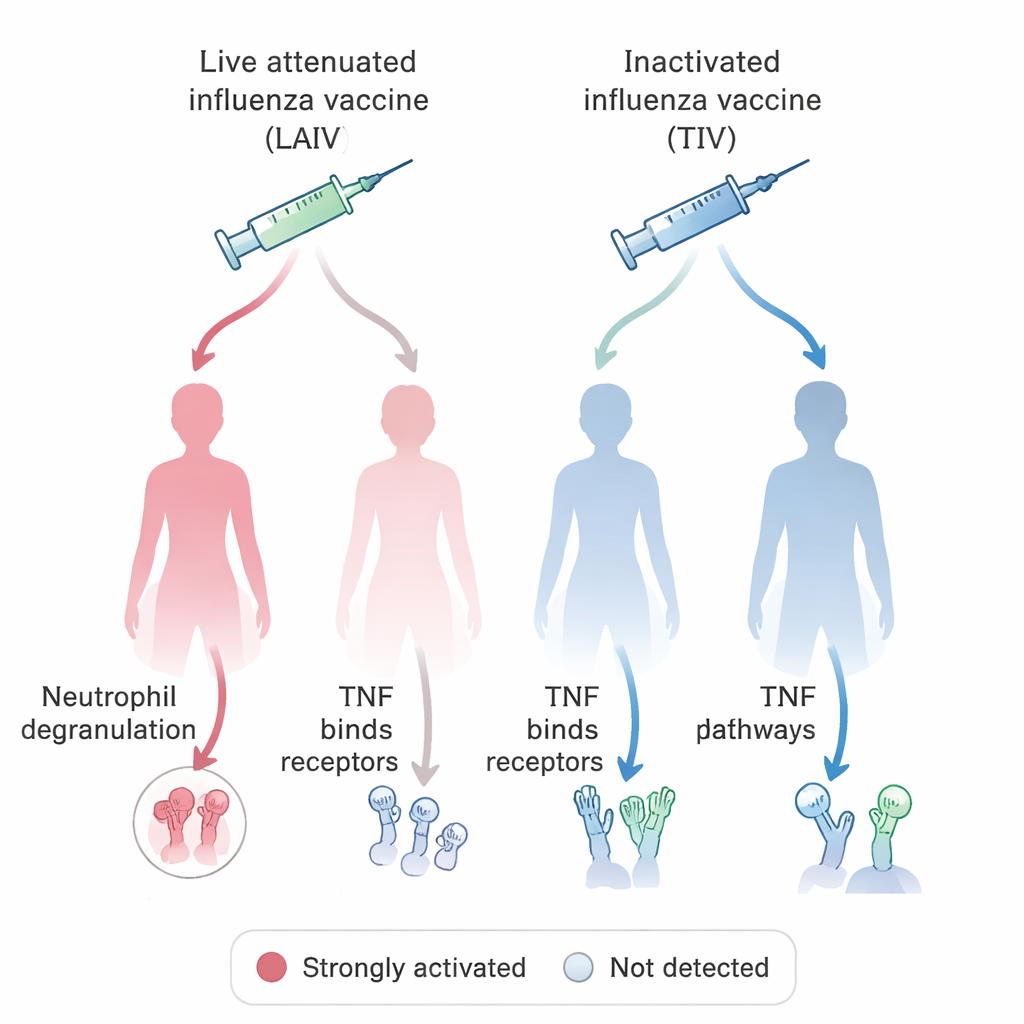
De arquivos dispersos a bancos de dados conectados
Para testar o modelo no mundo real, os autores construíram uma família de bancos de dados e ferramentas sob o nome guarda-chuva OSEAN. Eles converteram três grandes recursos públicos para a estrutura SEA CDM: ImmPort, que hospeda metadados de estudos de resposta imune; VIGET, que liga estudos de vacinas a dados de atividade gênica; e CELLxGENE, que foca em medidas de célula única. Usando pipelines personalizados, eles traduziram dezenas de tabelas e formatos de arquivo originais em um conjunto consistente de tabelas do SEA CDM ou nós de grafo. Isso permitiu armazenar mais de mil estudos relacionados à imunidade, mais de dois milhões de amostras e numerosas descrições de vacinas, doenças e métodos laboratoriais em um único arcabouço coerente que pode ser pesquisado com o mesmo software.
O que dados unificados podem revelar sobre vacinas e diferenças entre sexos
Com esse sistema unificado em funcionamento, a equipe fez uma pergunta biológica de relevância médica direta: como diferentes vacinas contra influenza estimulam o sistema imunológico em mulheres e homens? Ao consultar o banco de dados OSEAN baseado em VIGET e aplicar regras simples sobre o que conta como um gene “estimulado”, eles identificaram centenas de genes cuja atividade aumentou após vacinação com vacinas contra influenza atenuadas ao vivo (contendo vírus enfraquecido) ou vacinas inativadas, “mortas”. Em seguida, compararam as vias nas quais esses genes participam, separando os dados por sexo. Um padrão marcante envolveu neutrófilos, um tipo de glóbulo branco que ataca microrganismos liberando grânulos tóxicos, e sinalização via TNF, uma molécula inflamatória chave. Na maioria dos grupos, a vacinação contra influenza esteve associada a sinais de degranulação de neutrófilos, mas essa assinatura estava ausente em mulheres que receberam a vacina atenuada ao vivo. Em contraste, a sinalização relacionada ao TNF foi especialmente proeminente nessas mulheres, mas não nos grupos masculinos paralelos. Essas descobertas ecoam estudos em animais que sugerem que o comportamento dos neutrófilos e as respostas vacinais podem diferir sistematicamente entre machos e fêmeas.
Construindo um ecossistema para descobertas futuras
Os autores argumentam que o verdadeiro poder do SEA CDM reside em tornar os dados biomédicos mais FAIR — encontráveis, acessíveis, interoperáveis e reutilizáveis. Ao dar aos experimentos uma estrutura compartilhada e ancorar cada rótulo importante a um termo de ontologia bem definido, o sistema facilita muito combinar dados de diferentes fontes, rastrear como as amostras foram tratadas e reproduzir análises. O estudo de caso sobre influenza mostra que até consultas relativamente simples, executadas sobre um banco de dados harmonizado, podem revelar padrões sutis e específicos por sexo na resposta vacinal que podem influenciar a dosagem ou a escolha da vacina. À medida que mais recursos adotarem esse modelo comum e as ferramentas acompanhantes, os pesquisadores estarão melhor equipados para conectar pistas entre doenças, tecnologias e populações, transformando conjuntos de dados fragmentados em um verdadeiro ecossistema integrativo de biodados.
Citação: Huffman, A., Yeh, FY., Hur, J. et al. SEA CDM: Study-Experiment-Assay Common Data Model and Databases for Cross-Domain Data Integration and Analysis. Sci Data 13, 238 (2026). https://doi.org/10.1038/s41597-026-06558-z
Palavras-chave: integração de dados, ontologia biomédica, resposta a vacina, diferenças entre sexos, grafo de conhecimento