Clear Sky Science · pt
Confiabilidade de LLMs como assistentes médicos para o público em geral: um estudo randomizado pré-registrado
Por que seu telefone pode não ser o melhor primeiro médico
Muitas pessoas recorrem cada vez mais a chatbots de IA quando se sentem mal, buscando respostas rápidas sobre se devem se preocupar, o que seus sintomas podem significar e se precisam ir ao hospital. Este estudo faz uma pergunta simples, mas urgente: se pessoas comuns usam modelos de linguagem poderosos como auxiliares médicos em casa, elas realmente tomam decisões melhores sobre sua saúde — ou a tecnologia pode gerar uma falsa sensação de segurança?
Testando máquinas inteligentes em casos realistas
Para descobrir, pesquisadores no Reino Unido criaram dez histórias médicas realistas, como uma dor de cabeça súbita e intensa ou dificuldade para respirar, baseadas em condições comuns que muitos de nós podemos enfrentar. Uma equipe de médicos experientes concordou com o “próximo passo” ideal para cada história — variando entre ficar em casa cuidando de si mesmo até chamar uma ambulância — e listou as condições-chave que uma pessoa atenta deveria considerar. Em seguida, 1.298 adultos de todo o Reino Unido foram randomicamente designados a uma das quatro opções: usar um dos três chatbots de IA líderes, ou usar o que normalmente fariam em casa, como busca na web ou experiência pessoal.
Como pessoas e máquinas se saíram — separadamente e juntas
Quando os modelos de linguagem foram testados isoladamente, fornecendo-se as descrições completas dos casos e pedindo diretamente um diagnóstico e a ação recomendada, eles foram impressionantes. Nos três sistemas, eles sugeriram corretamente ao menos uma condição médica relevante em cerca de 95% dos casos e escolheram o nível de urgência correto em mais da metade das vezes — muito melhor que um palpite aleatório. No papel, esses sistemas pareciam fortes candidatos a orientar pacientes preocupados.
Quando o conselho da IA encontra pessoas reais
Mas, quando usuários do dia a dia entraram na equação, o quadro mudou. Participantes usando IA não foram mais precisos do que o grupo controle ao escolher o que fazer a seguir, e foram na verdade piores em nomear condições subjacentes relevantes. Pessoas no grupo sem IA foram cerca de 1,8 vezes mais propensas a identificar uma condição correta do que aquelas usando chatbots. A maioria dos participantes em todos os grupos subestimou quão séria a situação era. Em outras palavras, o acesso a um modelo de linguagem avançado não ajudou as pessoas a entender melhor seus sintomas e não as direcionou de forma clara para escolhas mais seguras.
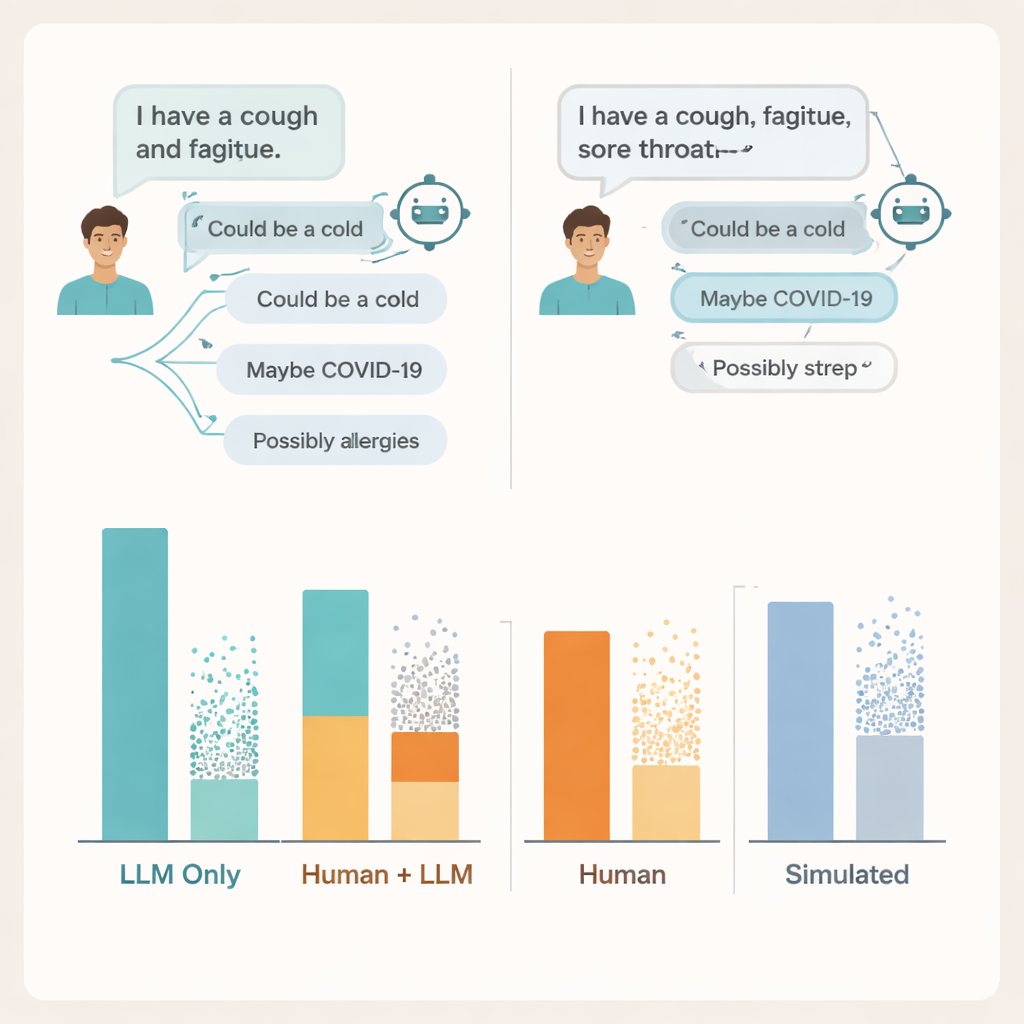
Onde a conversa se quebra
Para entender por que, os pesquisadores analisaram as transcrições reais dos diálogos. Encontraram problemas em ambos os lados da conversa. Muitos usuários não compartilharam detalhes suficientes sobre seus sintomas para que a IA desse um conselho sólido — da mesma forma que pacientes às vezes omitem informações-chave ao falar com um médico. Os modelos frequentemente mencionavam pelo menos uma condição relevante, mas também acrescentavam várias possibilidades incorretas ou distrações, e os usuários tiveram dificuldade em distinguir quais sugestões importavam. Em alguns casos, descrições de sintomas quase idênticas levaram a conselhos bastante diferentes do mesmo modelo, tornando difícil para as pessoas formarem uma percepção clara de quando confiar no que viam na tela.
Por que testes padrão deixam passar os riscos reais
A equipe também comparou esses resultados com duas maneiras populares de avaliar IAs médicas: questões de múltipla escolha de exame e chats totalmente simulados de “paciente” entre dois modelos. Em ambos, os sistemas novamente pareceram fortes, alcançando ou superando pontuações de aprovação típicas em perguntas no estilo exame e se saindo melhor com pacientes simulados do que com pacientes reais. Ainda assim, altas notas em exames e conversas simuladas polidas não se alinharam com o desempenho das pessoas reais ao usar as mesmas ferramentas. Benchmarks que testam conhecimento isoladamente, argumentam os autores, deixam de capturar a natureza desordenada e frágil das interações humanas com a IA no mundo real.
O que isso significa para pacientes e sistemas de saúde
Por enquanto, conclui o estudo, os atuais modelos de linguagem de uso geral não estão prontos para atuar como conselheiros de primeira linha não supervisionados para o público. Eles claramente contêm grande quantidade de conhecimento médico, mas esse conhecimento não se traduz automaticamente em escolhas mais seguras quando pessoas ansiosas digitam perguntas parciais e confusas em casa. Tornar a IA genuinamente útil em contextos de alto risco, como a saúde, exigirá mais do que melhores notas em exames — exigirá um design cuidadoso, testes com usuários diversos e checagens mais rigorosas sobre como a informação é coletada, explicada e merecedora de confiança na dinâmica de conversa.
Citação: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Palavras-chave: chatbots médicos, autodiagnóstico, IA em saúde, tomada de decisão do paciente, modelos de linguagem de grande porte