Clear Sky Science · pt
Sintetizando a literatura científica com modelos de linguagem aumentados por recuperação
Por que acompanhar a ciência é tão difícil
Cada ano, milhões de novos artigos científicos surgem online. Nenhum pesquisador humano consegue lê-los todos; ainda assim, tratamentos médicos importantes, descobertas sobre o clima e avanços tecnológicos podem estar escondidos nesse fluxo de informação. Este artigo investiga se sistemas avançados de IA podem ajudar cientistas a vasculhar esse oceano de estudos e transformá-los em resumos claros e confiáveis — sem inventar fatos.
Um novo tipo de assistente de pesquisa
Os autores apresentam o OpenScholar, um sistema de inteligência artificial desenvolvido especificamente para ler e sintetizar a literatura científica. Ao contrário de chatbots gerais, o OpenScholar está fortemente conectado a um enorme banco de dados aberto com cerca de 45 milhões de artigos, chamado OpenScholar DataStore. Quando um cientista faz uma pergunta — por exemplo, como resfriar nanopartículas levitadas ou quais métodos funcionam melhor para imageamento cerebral — o sistema primeiro procura trechos relevantes nesse banco, depois elabora uma resposta com citações inline, muito parecida com um artigo de revisão escrito por humanos. Ele repete esse processo várias vezes, criticando e refinando seus próprios rascunhos para melhorar clareza, completude e qualidade das citações.
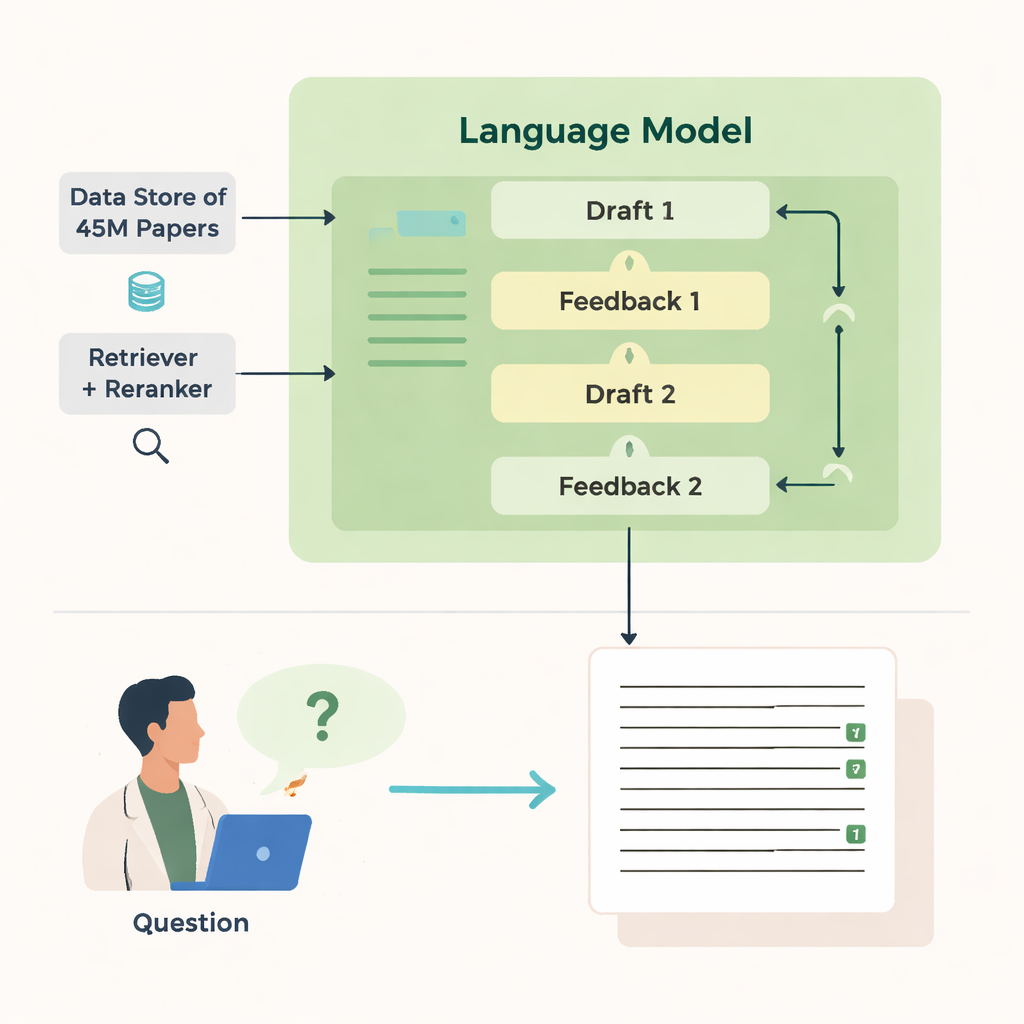
Como ele busca e escreve
O poder do OpenScholar vem de várias partes coordenadas. Um módulo “recuperador” varre embeddings de texto pré-computados de milhões de artigos para encontrar trechos promissores, enquanto um “reordenador” (reranker) reorganiza esses trechos para enfatizar os mais relevantes. O modelo de linguagem então usa essas evidências para produzir uma resposta longa com referências numeradas. Após o primeiro rascunho, o modelo gera feedback para si mesmo — apontando perspectivas ausentes, estrutura fraca ou evidência insuficiente — e, quando necessário, aciona buscas mais direcionadas. Em seguida reescreve a resposta, incorporando novos artigos e ajustando as citações. Uma checagem final garante que afirmações que precisam de suporte tenham pelo menos uma fonte recuperada.
Testando afirmações e citações
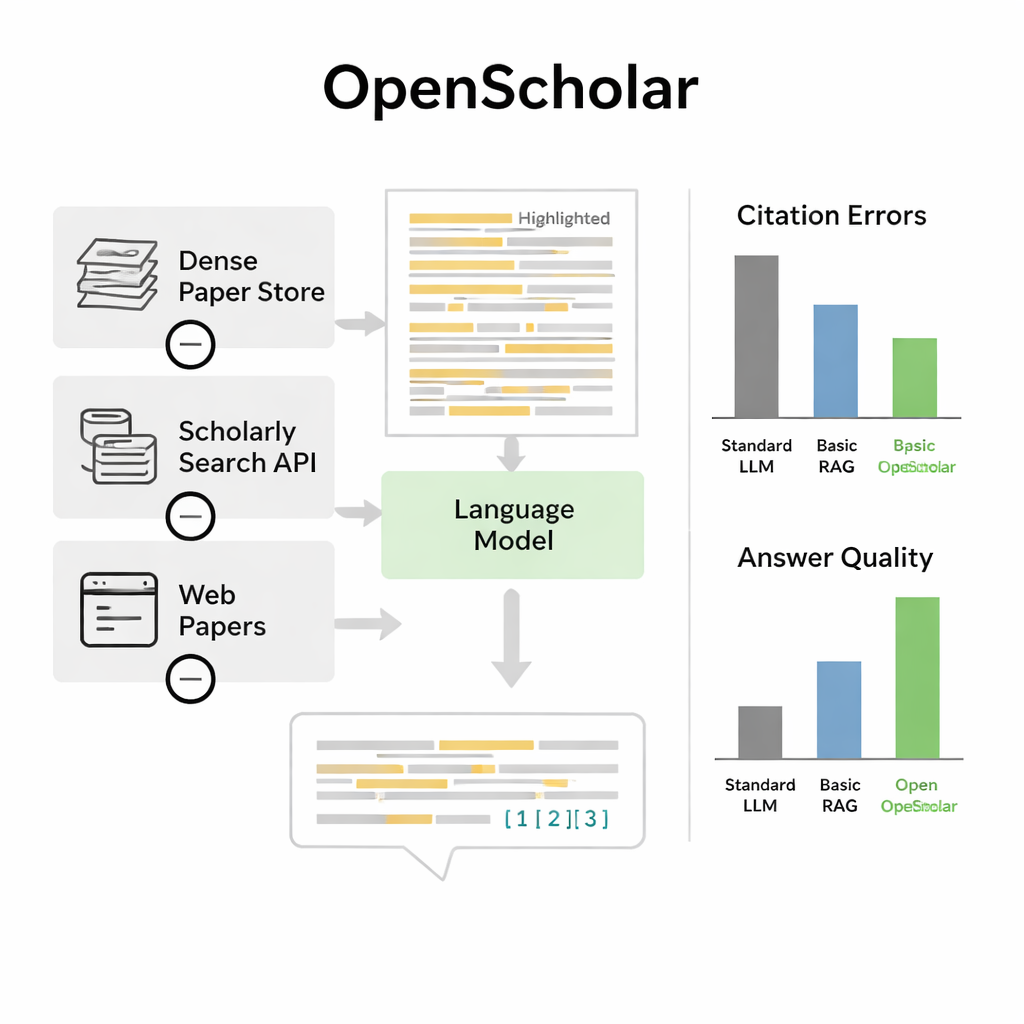
Para verificar se o OpenScholar realmente ajuda, os autores criaram o ScholarQABench, um grande benchmark projetado para imitar perguntas reais de revisão da literatura. Ele inclui quase 3.000 perguntas escritas por especialistas e centenas de respostas longas nas áreas de ciência da computação, física, neurociência e biomedicina. Importante: essas perguntas geralmente exigem a leitura de vários artigos, não apenas de um resumo. A equipe avaliou os sistemas em múltiplos eixos: correção factual, cobertura dos pontos-chave, clareza da escrita e quão precisamente as citações refletiam os artigos subjacentes. Eles combinaram verificações automáticas com avaliações detalhadas de especialistas com nível de doutorado que compararam respostas geradas por IA com respostas escritas por humanos.
Superando chatbots fortes e igualando especialistas
Nesse benchmark, o OpenScholar superou tanto modelos de linguagem padrão quanto ferramentas anteriores que apenas anexavam recuperação a um chatbot geral. Uma versão compacta de oito bilhões de parâmetros, treinada inteiramente com dados abertos, teve desempenho superior numa tarefa exigente de síntese envolvendo múltiplos artigos em comparação com o GPT-4o e um sistema concorrente chamado PaperQA2, apesar destes dependerem de modelos proprietários maiores. Uma constatação notável foi a frequência com que chatbots comuns “alucinaram” referências: em 78–90% dos casos, suas listas de citação incluíam artigos que não existiam ou que não apoiavam as alegações. Em contraste, a precisão das citações do OpenScholar rivalizou com a de especialistas humanos. Quando especialistas compararam respostas diretamente, preferiram o OpenScholar-8B às respostas escritas por especialistas cerca de metade das vezes, e um pipeline OpenScholar baseado no GPT-4o em aproximadamente 70% das vezes, principalmente porque a IA cobriu mais estudos relevantes e os organizou claramente.
Limites e melhorias futuras
Apesar desses avanços, os autores enfatizam que o OpenScholar não substitui cientistas. O sistema ainda pode deixar de fora os artigos mais representativos, enfatizar excessivamente trabalhos menos importantes ou introduzir afirmações factualmente incorretas, especialmente em modelos mais compactos. O próprio benchmark também tem limites: foca principalmente em ciência da computação, biomedicina e física, e as perguntas cuidadosamente anotadas ainda são relativamente poucas porque o tempo de especialistas é caro. As avaliações também têm dificuldade de capturar plenamente qualidades mais sutis, como se as citações destacam trabalhos realmente seminais ou se uma resposta realmente orientaria um novo experimento.
O que isso significa para a ciência do dia a dia
Para não especialistas, a principal conclusão é que ferramentas de IA bem projetadas já podem ajudar cientistas a navegar pela literatura científica de forma mais eficaz, desde que estejam ligadas a dados reais e sujeitas a padrões rigorosos de evidência e transparência. O OpenScholar demonstra que, quando um sistema de IA é construído desde o início para recuperar, checar e citar artigos reais — e quando seu desempenho é testado contra especialistas humanos — ele pode produzir resumos da literatura que não apenas são legíveis, mas também verificáveis. Na prática, tais ferramentas poderiam liberar pesquisadores para se concentrarem mais em desenhar experimentos e interpretar resultados, mantendo, ao mesmo tempo, os humanos no controle de julgar o que é verdadeiro e importante.
Citação: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
Palavras-chave: revisão da literatura científica, modelos de linguagem aumentados por recuperação, OpenScholar, precisão de citações, ferramentas de pesquisa em IA