Clear Sky Science · pt
Antecipação e descoberta de metabolitos de mamíferos guiada por modelos de linguagem
Química oculta dentro de nossos corpos
Cada gota de sangue ou urina contém milhares de moléculas minúsculas que refletem o que comemos, como vivemos e se estamos ficando doentes. Ainda assim, para a maioria dessas moléculas os cientistas não conhecem seus nomes nem suas funções. Este artigo apresenta o DeepMet, um sistema de inteligência artificial que lê a “linguagem” dessas moléculas e prevê quais delas estão ausentes de nossos mapas atuais da química humana e animal. Ao orientar experimentos para os candidatos mais promissores, o DeepMet ajuda pesquisadores a desvendar essa matéria escura química e a entender melhor como nossos corpos funcionam.
Por que tantas moléculas permanecem desconhecidas
Instrumentos modernos podem medir e caracterizar parcialmente milhares de moléculas em uma amostra de tecido de uma só vez. Mas transformar essas impressões digitais em estruturas exatas é difícil. Bancos de dados existentes listam muitos metabolitos conhecidos, porém a maioria dos sinais observados em amostras reais não corresponde a nada nesses catálogos. Essa lacuna indica que os mapas atuais do metabolismo são incompletos e que muitas moléculas naturais em mamíferos nunca foram descritas. Os autores procuraram construir uma ferramenta que pudesse aprender com metabolitos conhecidos e então imaginar os mais plausíveis ausentes, de modo semelhante a como modelos de linguagem prevêem palavras prováveis em uma frase.
Ensinando a uma máquina a gramática do metabolismo
A equipe treinou uma rede neural chamada DeepMet em cerca de 2.000 metabolitos humanos bem estabelecidos, codificando cada um como uma sequência curta que descreve sua estrutura. Após um treinamento inicial com moléculas do tipo fármaco para aprender regras químicas gerais, o DeepMet foi refinado com esse conjunto de metabolitos. Ao ser solicitado a gerar novas estruturas, o modelo produziu moléculas que ocupavam as mesmas regiões do espaço químico que metabolitos reais e até reproduziu muitos tipos conhecidos de reações enzimáticas, apesar de nunca ter sido informado explicitamente sobre essas regras. Em outras palavras, o DeepMet pareceu internalizar a gramática não escrita que liga blocos básicos como açúcares e aminoácidos em pequenas moléculas biologicamente realistas.
Predizendo quais novas moléculas provavelmente existem
Os pesquisadores então amostraram um bilhão de moléculas candidatas a partir do DeepMet e contaram com que frequência cada estrutura única apareceu. Estruturas repetidas com frequência tendiam a se assemelhar mais a metabolitos conhecidos, compartilhar núcleos químicos comuns com eles e corresponder a transformações enzimáticas plausíveis. Para testar se esses candidatos de alta frequência correspondiam a moléculas reais, a equipe comparou as previsões do DeepMet com metabolitos que foram adicionados ao Human Metabolome Database após o fechamento dos dados de treinamento do modelo. O DeepMet já havia gerado a maioria dessas descobertas posteriores e colocou muitas delas entre seus candidatos mais prováveis. Dos milhares de estruturas bem ranqueadas e ausentes em bases de dados, os autores compraram ou sintetizaram 80 e checaram amostras humanas reais por espectrometria de massas. Confirmaram a presença de vários metabolitos previamente não reconhecidos, alguns dos quais haviam sido negligenciados mesmo aparecendo na literatura existente.
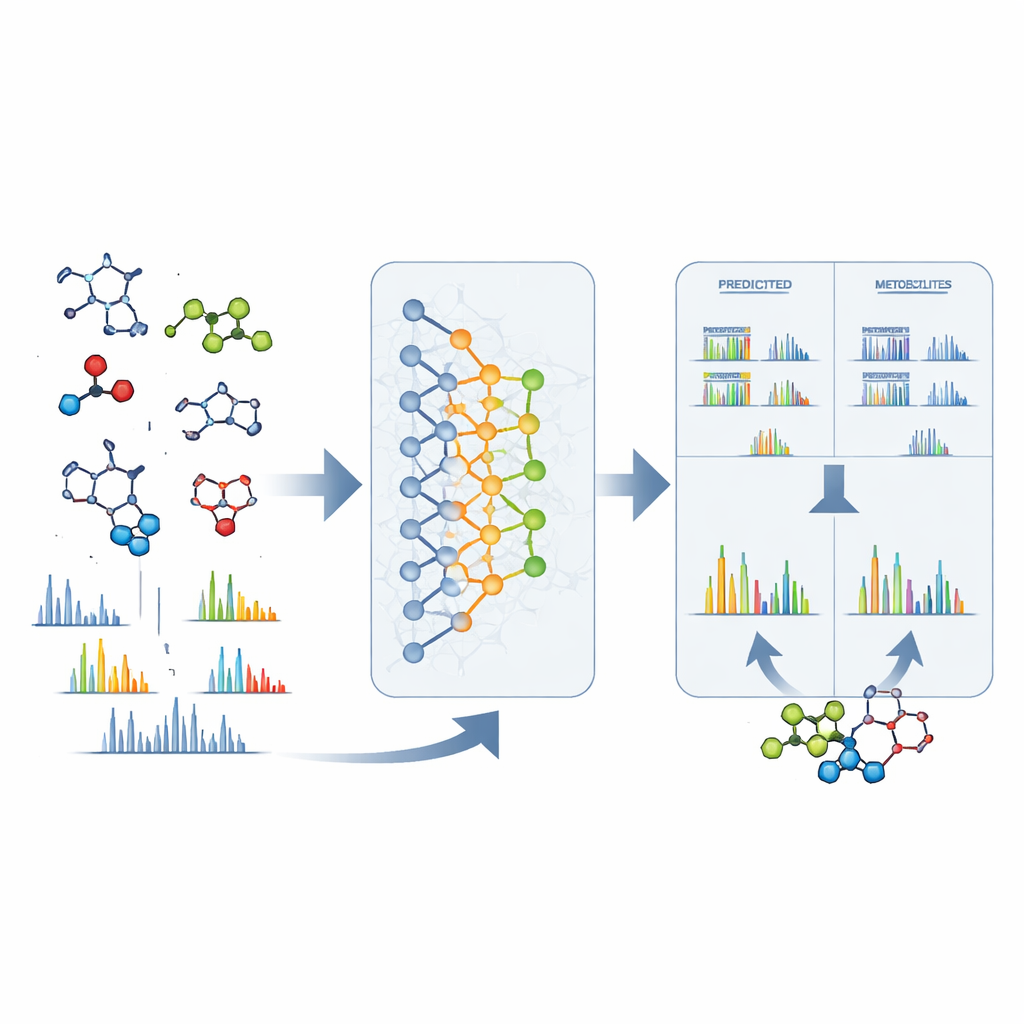
De sinais brutos a estruturas concretas
O DeepMet também é útil quando um pico desconhecido é observado em um espectrômetro de massas. Dada apenas a massa exata de uma molécula misteriosa, o modelo pode listar muitas estruturas que teriam o mesmo peso e ranqueá‑las segundo o quão semelhantes a metabolitos elas parecem. Em quase um terço dos casos de teste, a estrutura correta saiu no topo; em muitos outros, apareceu entre apenas um punhado de candidatos bem ranqueados e geralmente era muito similar na forma à favorita do modelo. Para reduzir ainda mais as possibilidades, os autores combinaram o DeepMet com um software separado que prevê como cada candidato se fragmentaria no espectrômetro de massas. Confrontar esses padrões previstos com espectros experimentais reais aproximadamente dobrou a precisão de identificação. Buscar em grandes conjuntos de dados públicos com essa abordagem combinada rendeu estruturas tentativas para muitos sinais antes anônimos e apontou para metabolitos que diferem entre doenças, dietas e estados do microbioma.
Iluminando a matéria escura química da vida
Ao misturar intuição química aprendida a partir de dados com correspondência de padrões potente contra espectros de massas, o DeepMet fornece um roteiro para descobrir novos metabolitos de forma direcionada e prática. Ainda não pode revelar toda molécula desconhecida — algumas estruturas estão longe demais daquelas que viu, e certos isômeros permanecem indistinguíveis sem métodos especializados. Mas o estudo mostra que ferramentas no estilo de modelos de linguagem não só podem inventar moléculas realistas, como também antecipar compostos reais que biólogos confirmarão mais tarde em animais e humanos. Para o público em geral, a conclusão é que a IA agora pode ajudar químicos a descobrir sistematicamente a química oculta em nossos corpos, potencialmente revelando novos biomarcadores, rastreando ligações entre dieta, micróbios e hospedeiro, e gradualmente transformando a matéria escura metabólica de hoje na biologia bem mapeada de amanhã.
Citação: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
Palavras-chave: metabolômica, modelos de linguagem química, DeepMet, espectrometria de massas, matéria escura metabólica