Clear Sky Science · pt
Predição de comprimentos de onda de emissão assistida por mineração de texto e aprendizado de máquina com validação experimental
Transformando Texto Científico em Luz
Cada ano, cientistas publicam dezenas de milhares de artigos sobre materiais que brilham — substâncias usadas em telas de telefones, scanners médicos e detectores de radiação. Enterradas nessas páginas estão medições de exatamente quais cores diferentes materiais emitem, mas a informação está dispersa, escrita de forma inconsistente e difícil para computadores utilizarem. Este estudo mostra como ler automaticamente essa literatura, transformá‑la em um grande conjunto de dados confiável e então usar aprendizado de máquina para prever a cor da luz que novos materiais emitirã o — ajudando pesquisadores a projetar fósforos melhores muito mais rápido.
Por que Materiais Luminescentes Importam
Fósforos são materiais que absorvem energia e a reemitem como luz visível. Eles estão no centro de tecnologias como telas de altíssima definição, LEDs brancos, imagem médica e detecção de radiação. Engenheiros querem fósforos que brilhem com cores muito específicas, permaneçam brilhantes em altas temperaturas e desperdicem o mínimo de energia possível. Nas últimas duas décadas, a pesquisa sobre esses materiais explodiu, preenchendo o registro científico com relatórios detalhados de receitas químicas e comprimentos de onda de emissão. Ainda assim, esses dados estão em sua maior parte presos em texto não estruturado — frases em parágrafos, legendas e seções experimentais escritas para humanos, não para computadores. 
Ensinando Computadores a Ler Artigos de Materiais
Os autores construíram um pipeline de mineração de texto especializado, adaptado à literatura sobre fósforos. Em vez de usar ferramentas de linguagem genéricas, eles elaboraram regras que entendem como os químicos de fato escrevem fórmulas, especialmente para materiais “dopados”, nos quais uma pequena quantidade de um elemento é adicionada a um hospedeiro. O sistema consegue reconhecer corretamente nomes complexos, como uma rede hospedeira seguida por vários íons dopantes e suas concentrações, e pode vincular esses nomes a números próximos que representam comprimentos de onda de emissão. Também resolve linguagem complicada, como sentenças que dizem “emite em 630 nm” sem repetir o nome do material, ou parágrafos onde vários materiais e vários comprimentos de onda são mencionados juntos. Ao classificar cada frase segundo quantos materiais e propriedades ela contém e então escolher um algoritmo de correspondência para essa situação, o pipeline reduz muito as confusões sobre a qual número pertence a qual material.
Construindo um Mapa Limpo da Composição para a Cor
Aplicando esse pipeline a 16.659 artigos de periódicos, a equipe extraiu cerca de 6.400 pares “material–emissão” confiáveis: a fórmula do fósforo, seu comprimento de pico de emissão, a unidade e o identificador digital do artigo. Testes cuidadosos mostraram alta precisão tanto no reconhecimento de fórmulas completas de fósforos quanto na vinculação delas aos valores de emissão corretos. Com esse conjunto de dados estruturado em mãos, os pesquisadores focaram em uma família especialmente importante: materiais dopados com íons de európio (Eu²⁺), que podem emitir em uma ampla faixa do espectro visível dependendo do cristal hospedeiro. Eles calcularam descritores fisicamente significativos para cada hospedeiro — tais como detalhes da estrutura cristalina, comprimentos de ligação e gap eletrônico — e então usaram métodos de seleção de características para reduzir esses descritores às poucas variáveis que mais importam para predizer a cor.
Deixando o Aprendizado de Máquina Prever o Brilho
Em seguida, os autores treinaram e compararam vários modelos de aprendizado de máquina para prever o comprimento de onda de emissão a partir desses descritores. Um algoritmo chamado XGBoost teve o melhor desempenho, alcançando um coeficiente de determinação (R²) de cerca de 0,91 em dados de teste não vistos — forte evidência de que o modelo captura as relações-chave entre estrutura e cor. Para verificar se a abordagem funciona no mundo real, eles usaram o modelo para propor novos fósforos promissores de sulfeto e nitreto dopados com Eu²⁺, sintetizaram quatro candidatos no laboratório e mediram sua emissão. Os comprimentos de onda observados diferiram das previsões por apenas cerca de 10 nanômetros, o que significa que as “suposições” do modelo estiveram muito próximas da realidade experimental. 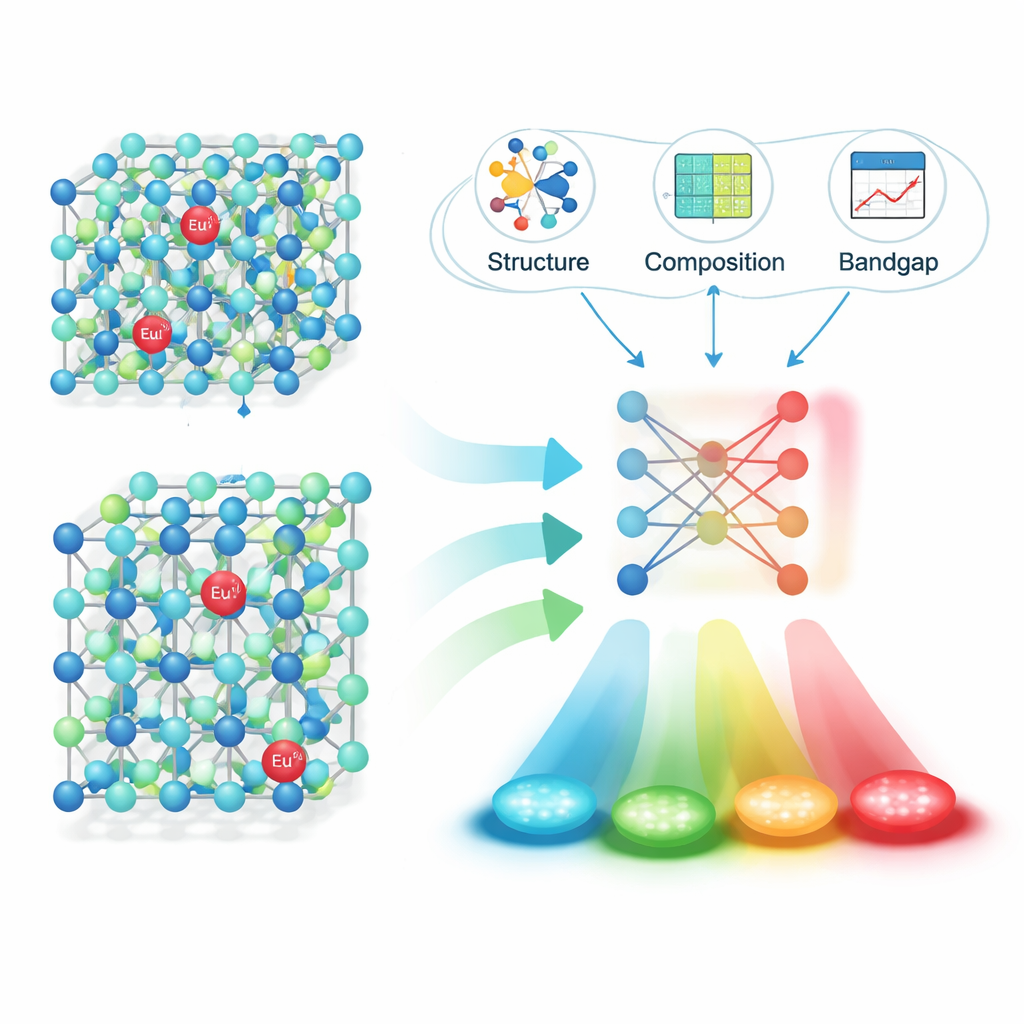
De Artigos a Projetos Práticos
Para não especialistas, a mensagem central é que este trabalho transforma artigos dispersos e escritos por humanos em um mapa coerente e pesquisável que conecta “do que um material é feito” a “que cor ele emite”. Ao automatizar as etapas de leitura, organização e aprendizado — e então confirmar previsões por meio de experimentos reais — o estudo descreve um ciclo fechado: texto → dados → modelo → novo material. Essa estrutura pode ser estendida a outras propriedades, como intensidade e estabilidade, e até a outras classes de materiais funcionais. Ao fazê‑lo, aponta para um futuro onde, em vez de trabalho de laboratório por tentativa e erro, os cientistas podem rapidamente focar nas receitas mais promissoras, acelerando o desenvolvimento de melhores tecnologias de iluminação, displays e sensores.
Citação: Huang, L., Zhang, X., Li, S. et al. Text mining-assisted machine learning prediction and experimental validation of emission wavelengths. npj Comput Mater 12, 98 (2026). https://doi.org/10.1038/s41524-026-01967-5
Palavras-chave: materiais luminescentes, mineração de texto, aprendizado de máquina, fósforos, predição de comprimento de onda de emissão