Clear Sky Science · pt
Aprendendo dinâmica molecular coarse-grained eficiente em dados a partir de forças e ruído
Por que encolher moléculas importa
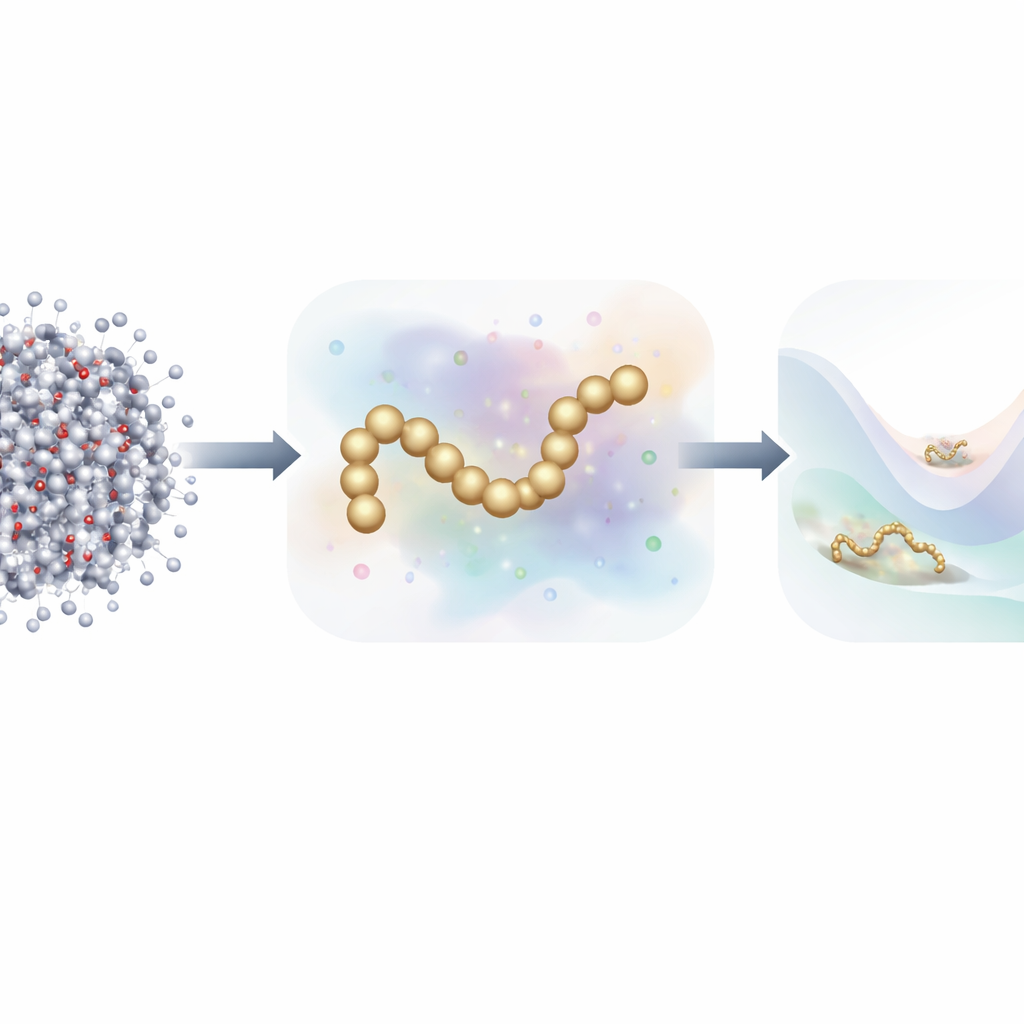
Simular o movimento incessante de cada átomo em uma proteína e na água ao seu redor é uma de nossas melhores ferramentas para entender como a vida funciona na escala molecular. Mas essas simulações com todos os átomos são tão exigentes computacionalmente que acompanhar uma proteína enquanto ela dobra, desdobra ou interage com parceiros por tempos biologicamente relevantes pode levar meses em um supercomputador. Este artigo apresenta uma nova maneira de construir modelos rápidos e simplificados de proteínas que ainda se comportam como seus equivalentes atômicos completos, exigindo muito menos dados de treinamento e poder de computação do que antes.
De todos os átomos para uma imagem mais simples
Dinâmica molecular tradicional acompanha cada átomo e calcula as forças entre eles a cada pequeno passo de tempo. Para acelerar as coisas, cientistas frequentemente usam modelos coarse-grained, que agrupam muitos átomos em um número menor de “contas” (beads). Esses modelos reduzidos rodam muito mais rápido, mas historicamente tiveram dificuldade em igualar a precisão das simulações atomísticas completas, especialmente para proteínas com comportamento de dobramento complexo. Trabalhos recentes recorreram ao aprendizado de máquina para descobrir automaticamente campos de força coarse-grained melhores, mas treinar esses modelos tem tipicamente exigido milhões de instantâneos detalhados, cada um rotulado com as forças em cada átomo — um fardo enorme de dados e computação.
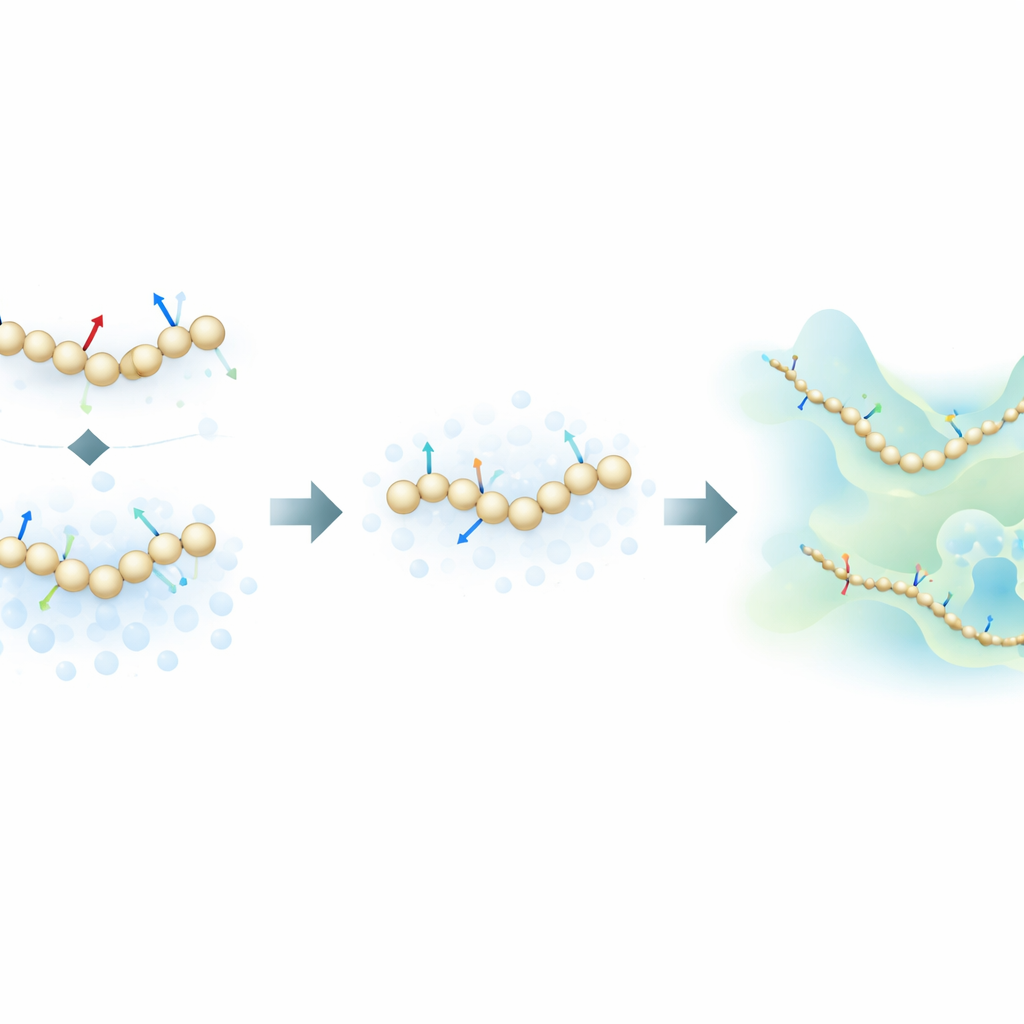
Misturando forças físicas com ruído informativo
Os autores propõem uma nova estratégia de treinamento que se inspira em modelos generativos de difusão — a mesma classe de algoritmos por trás de muitos geradores de imagem modernos por IA. Em vez de aprender apenas a partir das forças físicas calculadas em simulações atomísticas, o método deles também aprende a partir de como as estruturas moleculares se distribuem no espaço, adicionando deliberadamente ruído controlado às configurações coarse-grained. Nesse quadro, o ruído não é apenas um incômodo a ser removido; torna-se uma fonte adicional de informação. Ao unificar matematicamente a abordagem tradicional de “força por correspondência” (force matching) com técnicas de denoising de modelos de difusão, o método pode inferir a paisagem de energia subjacente de uma proteína usando muito menos exemplos rotulados.
Ensinando modelos simples a imitar proteínas complexas
Para testar a ideia, os pesquisadores treinaram modelos coarse-grained baseados em redes neurais para várias proteínas de complexidade crescente: as pequenas miniproteínas Chignolin e Trp-Cage, a um pouco maior NTL9, e a proteína de 76 resíduos Ubiquitina. Compararam três modos de treinamento: usando apenas forças atomísticas, usando apenas informação baseada em ruído, e combinando ambos. Para as proteínas menores, mostraram que a nova abordagem combinada pode reproduzir as características chave da paisagem de dobramento — como a estabilidade relativa dos estados dobrado e desdobrado e a presença de intermediários — usando até cem vezes menos dados de treinamento do que métodos padrão de force matching. Surpreendentemente, em regimes com escassez de dados, até modelos treinados apenas com informação baseada em ruído frequentemente igualaram ou superaram a precisão do treinamento apenas por forças.
Alcançando sistemas proteicos maiores e mais difíceis
Ubiquitina é um teste mais exigente: capturar seu dobramento e desdobramento em temperaturas realistas historicamente exigiu hardware especializado e execuções atomísticas extremamente longas. Aqui, os autores treinam modelos coarse-grained usando um conjunto de dados modesto composto por simulações de equilíbrio curtas em torno do estado dobrado mais simulações não-equilíbrio “puxadas” que esticam a proteína de forma forçada. Apesar desse conjunto de treinamento enviesado e da falta de uma referência atomística perfeita nas mesmas condições, o modelo treinado com forças e ruído recupera uma imagem realista em que estados dobrado e desdobrado coexistem, com o estado dobrado favorecido em estabilidade. Em contraste, um modelo treinado apenas com forças falha em estabilizar o estado dobrado, enquanto um modelo só com ruído prefere estruturas desdobradas. Notavelmente, nenhum dos modelos coarse-grained simplesmente memoriza as formas extremas esticadas dos dados de treinamento, indicando que a paisagem de energia aprendida é fisicamente significativa e não apenas uma impressão das trajetórias de entrada.
O que isso significa para simulações futuras
Ao transformar o ruído em um sinal de treinamento e fundi-lo com forças físicas, este trabalho mostra que modelos coarse-grained precisos de proteínas podem ser construídos a partir de conjuntos de dados muito menores e menos ideais do que se pensava. Na prática, isso significa que pesquisadores talvez não precisem mais de simulações atomísticas de milissegundos em supercomputadores especializados antes de explorar o comportamento de uma biomolécula com dinâmica coarse-grained aprendida por máquina. Em vez disso, simulações mais modestas em hardware amplamente disponível podem ser suficientes para treinar modelos reduzidos poderosos que capturam caminhos de dobramento chave e equilíbrios termodinâmicos. Embora ainda existam perguntas sobre como escolher e interpretar melhor o ruído adicionado e como o método se comportará em montagens biomoleculares ainda maiores e mais complexas, essa abordagem reduz substancialmente a barreira para usar simulações coarse-grained orientadas por dados como uma ferramenta rotineira na ciência molecular.
Citação: Durumeric, A.E.P., Chen, Y., Pasos-Trejo, A.S. et al. Learning data-efficient coarse-grained molecular dynamics from forces and noise. Nat Commun 17, 2493 (2026). https://doi.org/10.1038/s41467-026-70818-0
Palavras-chave: dinâmica molecular coarse-grained, campos de força por aprendizado de máquina, simulações de dobramento de proteínas, modelos de difusão em química, simulação eficiente em dados