Clear Sky Science · pt
Um conjunto de dados de fMRI 7T com imagens sintéticas para modelagem fora da distribuição da visão
Por que isso importa para entender visão e IA
Nossos olhos captam uma variedade enorme de imagens todos os dias, de florestas e rostos a placas de rua e ruído de tela. Ainda assim, a maioria dos estudos sobre cérebro e inteligência artificial se apoia em uma fatia estreita desse mundo visual: fotografias de cenas naturais. Este artigo apresenta um novo tipo de conjunto de dados cerebrais que deliberadamente sai dessa zona de conforto, usando imagens sintéticas cuidadosamente projetadas para testar até onde vão tanto nossas teorias da visão humana quanto os modelos de IA inspirados nela.
Construindo uma nova bancada de testes visual
Os autores estendem o influente Natural Scenes Dataset (NSD), que registrou atividade cerebral em ultra‑alta resolução com ressonância magnética de 7 Tesla enquanto pessoas viam dezenas de milhares de fotografias. Esse conjunto de dados original já alimentou alguns dos modelos mais precisos de como o córtex visual responde a imagens. Mas, como todas essas imagens são fotos relativamente comuns, fica difícil saber se um modelo que funciona bem no NSD realmente captura princípios gerais da visão ou simplesmente se especializou naquele tipo específico de imagens. Para enfrentar isso, a equipe escaneou novamente os mesmos oito voluntários, desta vez mostrando 284 imagens “sintéticas” que deliberadamente se afastam do mundo usual das fotos.
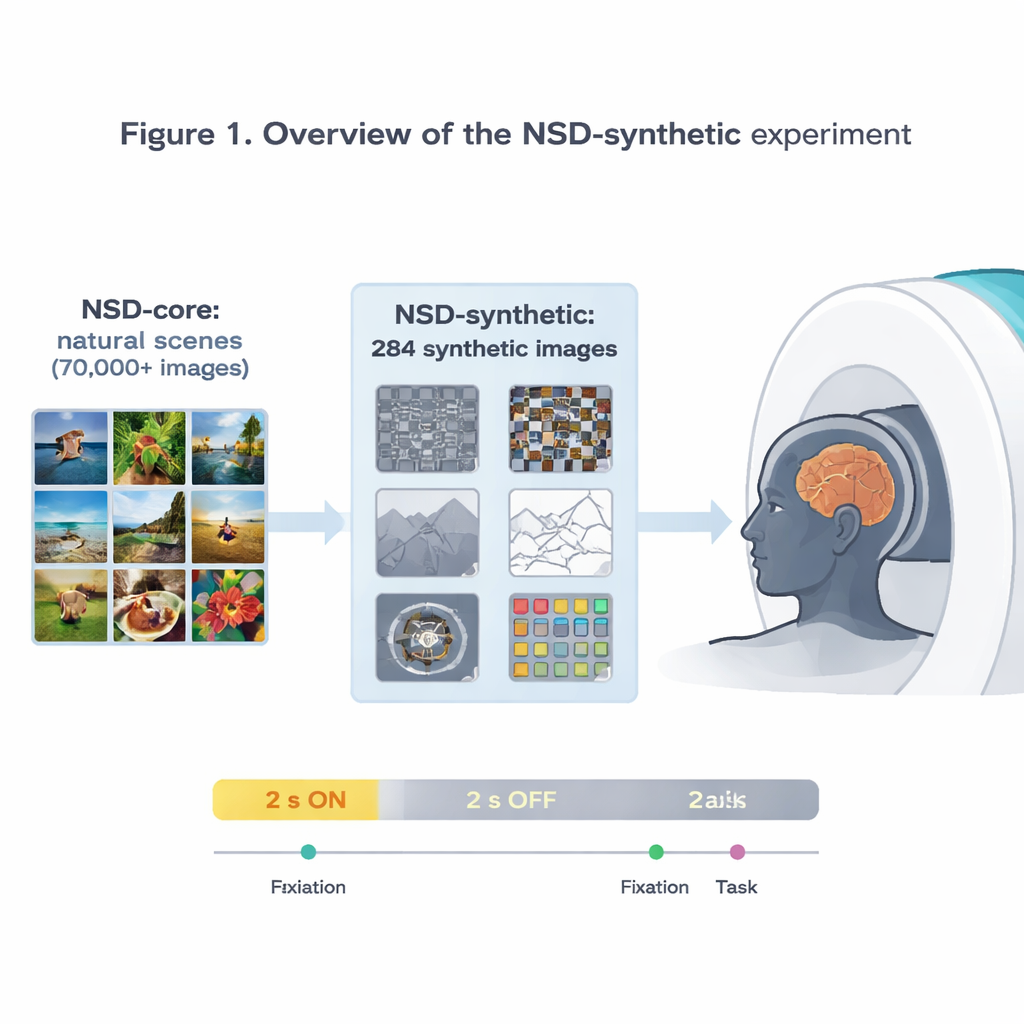
Imagens estranhas, respostas cerebrais confiáveis
As imagens sintéticas abrangem oito famílias: diferentes tipos de ruído visual, cenas naturais simples e suas versões alteradas (como invertidas ou em desenho de contorno), cenas com contraste reduzido ou fase embaralhada, palavras isoladas colocadas em várias posições, grades espirais que sondam sensibilidade a padrões finos e manchas de ruído colorido e brilhante. Enquanto as pessoas ou focavam em um pequeno ponto piscante ou realizavam uma tarefa simples de comparação de imagens, os pesquisadores mediram a atividade cerebral a cada 1,6 segundos. Eles mostram que esses estímulos com aparência estranha ainda produzem sinais fortes e confiáveis, especialmente em áreas visuais iniciais que respondem a características básicas como bordas, contraste e cor. Os padrões de atividade pelo córtex correspondem a preferências bem conhecidas de regiões especializadas, como uma área seletiva a palavras que responde mais a palavras centralizadas e uma área seletiva a cenas que responde mais a imagens de ambientes.
Provando que os dados são realmente “fora da distribuição”
Para que esse novo conjunto de dados desafie modelos, suas respostas cerebrais precisam ser genuinamente diferentes daquelas evocadas por fotografias naturais. Os autores comprimem padrões de atividade tanto do NSD original quanto da sessão sintética em um mapa bidimensional que reflete quão semelhantes são as respostas entre as imagens. Nesse espaço, respostas a imagens sintéticas se agrupam separadamente das respostas a fotos naturais, mesmo quando se leva em conta diferenças entre sessões de varredura. Além disso, as imagens sintéticas se organizam naturalmente por tipo visual — ruído com ruído, grades com grades, e assim por diante — mostrando que o cérebro organiza esses estímulos conforme sua estrutura subjacente, não apenas sua aparência superficial.
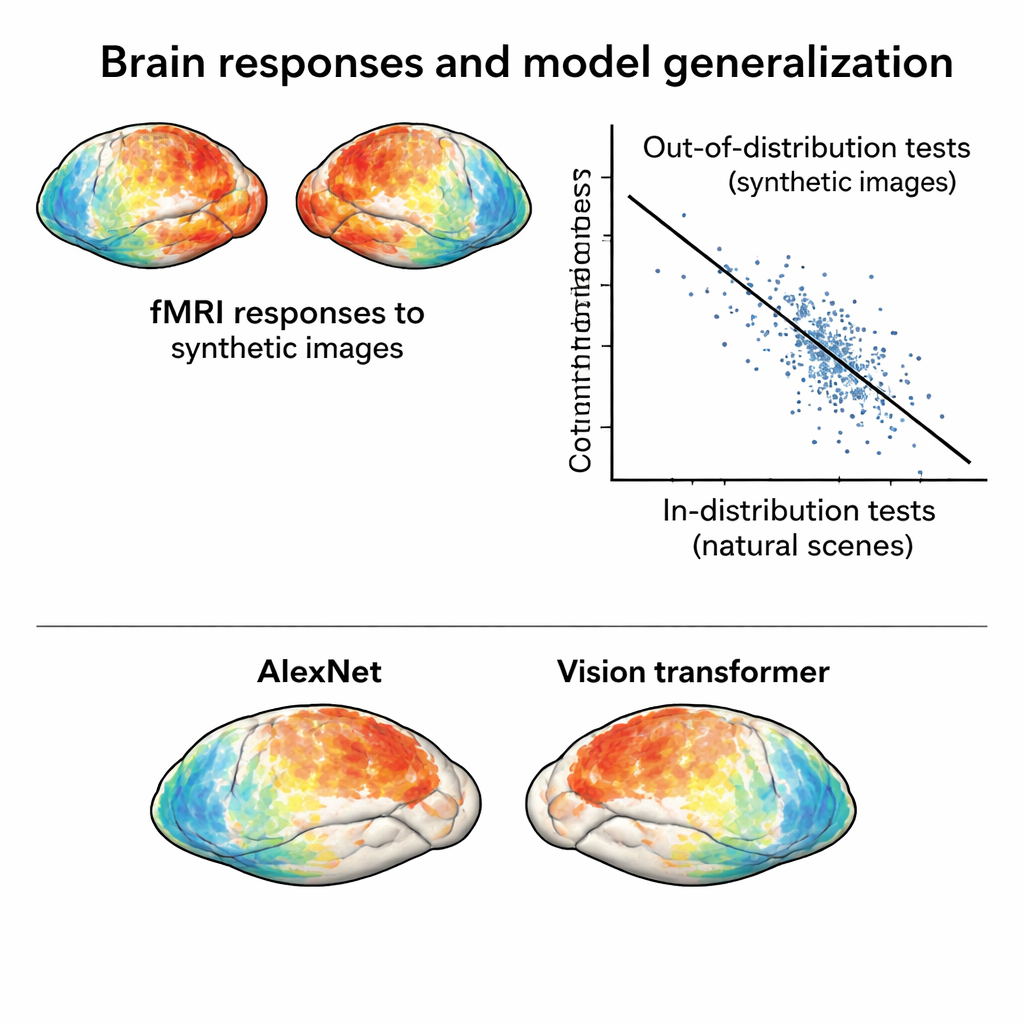
Submetendo modelos cerebrais e de IA a um teste mais difícil
Com este novo conjunto de dados “fora da distribuição” em mãos, a equipe treina modelos de codificação padrão: ferramentas matemáticas que predizem respostas cerebrais a partir de características de imagem extraídas por redes neurais profundas. Modelos treinados apenas com as fotos naturais têm bom desempenho quando testados em fotos semelhantes, mas sua precisão cai consideravelmente ao prever respostas às imagens sintéticas. Essa queda não se deve a dados ruidosos — as respostas sintéticas são, na verdade, muito limpas — mas a falhas reais dos modelos. Fundamentalmente, comparar diferentes arquiteturas de redes neurais sob essas condições mais severas revela contrastes que mal aparecem em testes dentro da distribuição. Por exemplo, um transformer visual moderno e uma rede auto‑supervisionada superam redes convolucionais clássicas quando confrontados com imagens sintéticas, sugerindo que a forma de treinamento de um modelo molda fortemente sua robustez.
Quão distantes das imagens familiares os modelos podem ir?
Os autores vão além e tratam a “distância” em relação aos dados de treinamento como um contínuo, não como um rótulo sim‑ou‑não. Eles medem quão distante a resposta cerebral de cada imagem está do conjunto de respostas a cenas naturais. Quanto mais afastada uma imagem sintética estiver nesse espaço, pior tende a ser o desempenho dos modelos e menos acurada é a identificação de qual imagem a pessoa viu com base apenas na atividade cerebral. Eles também mostram que, mesmo no mundo das fotografias ordinárias, conjuntos de teste escolhidos com critério podem se comportar como “ligeiramente fora da distribuição”: os modelos vão melhor em imagens tiradas do mesmo aglomerado que seu conjunto de treinamento, pior em cenas naturais distantes e pior ainda nas imagens sintéticas. Esse quadro em gradiente transforma o novo conjunto de dados em uma ferramenta para sondar exatamente que tipos de estrutura visual os modelos atuais deixam escapar.
O que isso significa para pesquisas futuras sobre cérebro e IA
Para não especialistas, a mensagem principal é que desempenho elevado em imagens familiares não garante que um modelo de IA inspirado no cérebro tenha realmente capturado como vemos. Ao publicar o NSD‑synthetic junto com o NSD original, os autores oferecem uma “pista de crash test” pública para modelos de visão: uma maneira de ver onde eles falham quando as imagens se tornam mais abstratas, mais coloridas ou menos naturais. Como o conjunto de dados é aberto e bem integrado a um recurso existente e amplamente usado, é provável que se torne uma referência padrão para testar e aprimorar teorias da visão humana e as redes artificiais que buscam imitar‑la.
Citação: Gifford, A.T., Cichy, R.M., Naselaris, T. et al. A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision. Nat Commun 17, 1589 (2026). https://doi.org/10.1038/s41467-026-69345-9
Palavras-chave: córtex visual, conjunto de dados de fMRI, imagens sintéticas, fora da distribuição, redes neurais profundas