Clear Sky Science · pt
Aprendizado sem retroalimentação em forma fechada com projeção para frente
Ensinando máquinas sem mensagens de retorno
A inteligência artificial moderna em grande parte aprende usando um método chamado retropropagação, em que os erros são enviados para trás através da rede para ajustar suas conexões internas. Mas esse processo difere de como cérebros reais funcionam e pode ser lento e consumidor de recursos. Este artigo apresenta uma nova forma de as redes neurais aprenderem, chamada Projeção para Frente, que elimina completamente a etapa de retrocesso ao mesmo tempo em que alcança desempenho robusto, especialmente em tarefas biomédicas desafiadoras com dados limitados.
Uma nova maneira de orientar o aprendizado
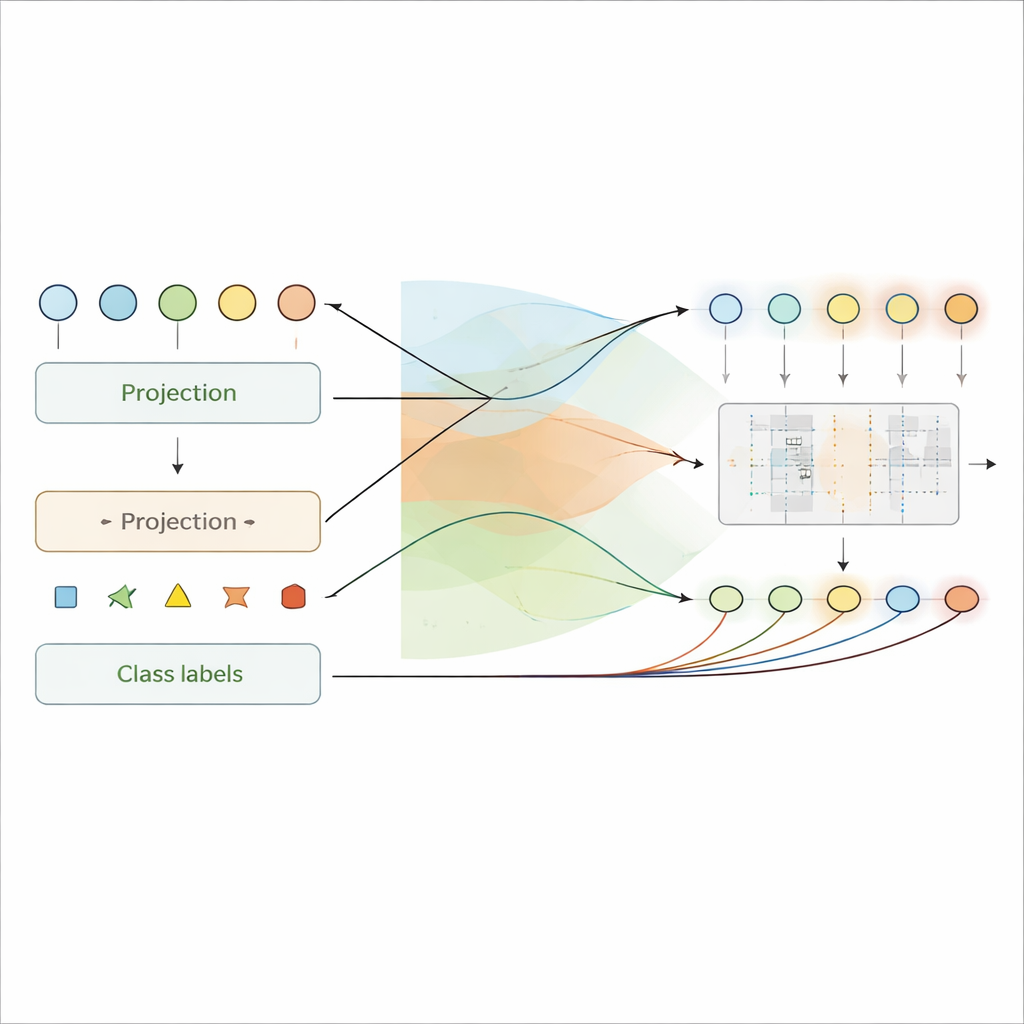
Redes neurais tradicionais aprendem comparando suas previsões com as respostas corretas e enviando sinais de erro para trás através de cada camada para ajustar as conexões. A Projeção para Frente segue uma rota diferente. Em vez de depender dessas mensagens de erro retroativas, ela usa apenas informações disponíveis enquanto os sinais avançam: a atividade da camada atual e o rótulo alvo. Em cada camada, o método combina a entrada daquela camada e o rótulo desejado usando projeções aleatórias fixas passadas por uma não linearidade simples. Isso produz um “alvo” de sinal interno para aquela camada — um padrão de atividade análogo a potenciais elétricos que a camada deve tentar reproduzir.
Uma vez criados esses alvos, os pesos de conexão de cada camada são resolvidos de uma só vez usando regressão em forma fechada, uma fórmula estatística padrão em vez de descida de gradiente iterativa. Isso significa que a rede pode ser treinada em uma única passagem sobre o conjunto de dados, sem revisitar repetidamente os mesmos exemplos ou armazenar grandes quantidades de ativações intermediárias. Como nenhuma informação precisa viajar para trás, o método respeita a comunicação unidirecional observada em neurônios biológicos e pode ser mais fácil de implementar em hardware especializado com conexões em uma única direção.
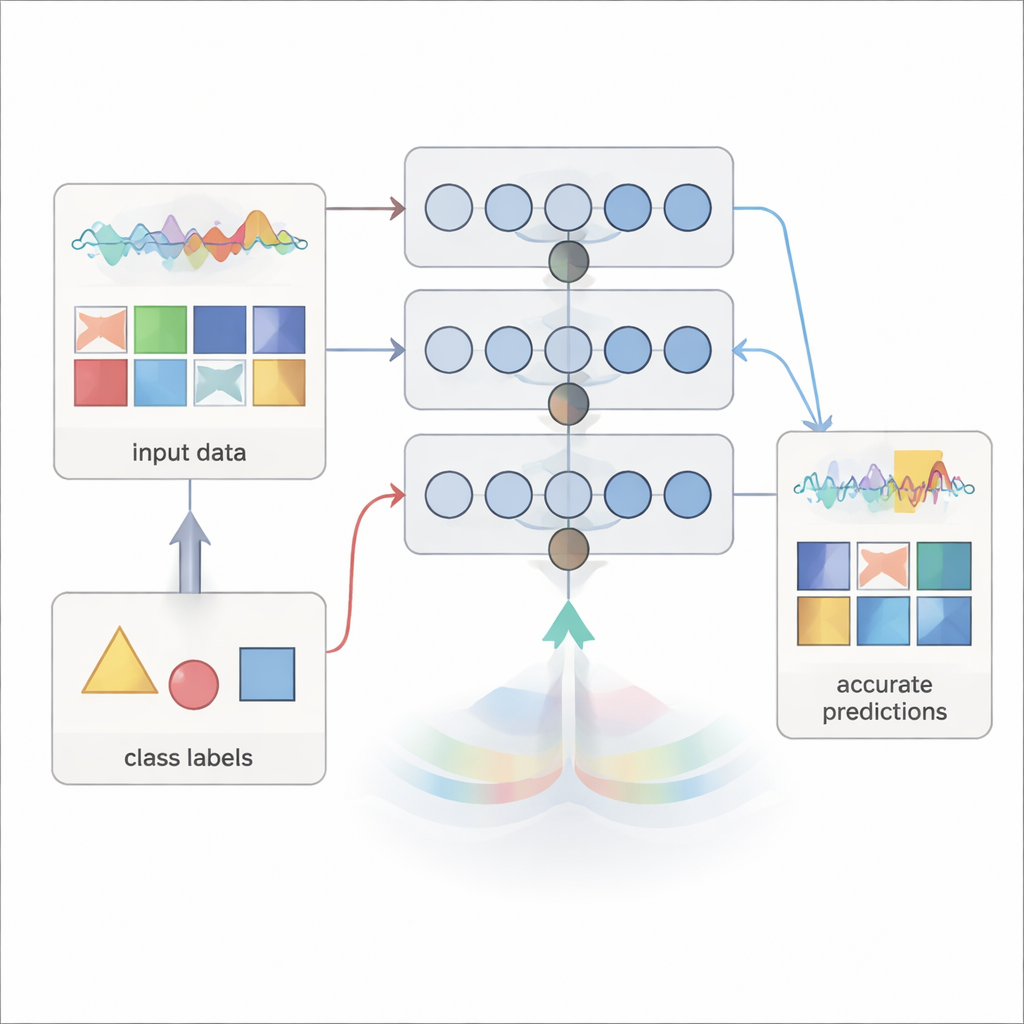
Vendo significado na atividade oculta
Uma vantagem marcante da Projeção para Frente é que os sinais internos nas camadas ocultas tornam-se diretamente interpretáveis. Como cada camada é explicitamente treinada para codificar tanto a entrada quanto o rótulo em seus potenciais tipo-membrana, esses valores internos podem ser lidos como previsões locais da classe. Os autores mostram como “decodificar” aproximadamente esses sinais de volta para o espaço de rótulos, transformando padrões de atividade em explicações por camada sobre o que a rede acredita em cada estágio. Nos experimentos, essas explicações tornam-se mais precisas em camadas mais profundas, refletindo um aprendizado progressivo — camadas iniciais captam padrões amplos, enquanto as posteriores focam em detalhes críticos para a decisão.
Essa interpretabilidade é particularmente valiosa na medicina, onde entender por que um modelo tomou uma decisão pode importar tanto quanto a própria decisão. Usando dados de eletrocardiograma, os autores mostram que a Projeção para Frente destaca sinais clinicamente conhecidos de infarto — como alterações em segmentos específicos da forma de onda — nos momentos corretos no tempo. Em exames oculares usados para detectar crescimento anômalo de vasos sanguíneos, o método naturalmente foca em bolsões de fluido, depósitos brilhantes e regiões semelhantes a cicatrizes que os especialistas procuram, mesmo quando treinado com apenas 100 exemplos por classe.
Treinamento rápido, resultados fortes
A equipe comparou a Projeção para Frente com várias alternativas que também tentam evitar a retropropagação completa, bem como com a retropropagação padrão. Em tarefas de imagem e de sequência, como dígitos do Fashion-MNIST, reconhecimento de promotores de DNA, detecção de infarto em eletrocardiogramas e reconhecimento de objetos, o novo método igualou ou superou o desempenho de outras regras de aprendizado local. Em configurações padrão, a retropropagação ainda manteve vantagem geral, mas a acurácia da Projeção para Frente ficou surpreendentemente próxima enquanto usava apenas uma única passagem de treinamento.
Os benefícios tornaram-se mais evidentes em cenários de “few-shot”, onde apenas um punhado de exemplos rotulados está disponível, como é comum na prática clínica. Nesses casos, a Projeção para Frente frequentemente generalizou melhor do que tanto a retropropagação quanto métodos locais concorrentes em radiografias torácicas, exames de retina e pequenos subconjuntos de imagens. A retropropagação tendia a ajustar demais os conjuntos de dados minúsculos ou a não aprender características ricas o suficiente, enquanto a Projeção para Frente produziu representações internas mais estáveis e reutilizáveis. Do ponto de vista computacional, treinar uma camada grande exigiu ordens de grandeza menos operações de multiplicar-e-acumular do que executar muitas épocas de retropropagação, traduzindo-se em ganhos substanciais de velocidade e menor custo energético.
O que isso significa para o futuro da IA e da computação inspirada no cérebro
Em termos cotidianos, este trabalho mostra que redes neurais não precisam depender de loops pesados e biologicamente implausíveis de retroalimentação para aprender representações internas úteis e compreensíveis. Ao misturar de forma engenhosa entradas e rótulos em uma única passagem para frente e resolver os pesos em forma fechada, a Projeção para Frente oferece uma forma de treinar modelos rapidamente, interpretar seu funcionamento interno e lidar com conjuntos de dados biomédicos pequenos e ruidosos. Embora a retropropagação permaneça o padrão-ouro para muitas tarefas em grande escala, essa abordagem sem retroalimentação aponta para estratégias de aprendizado mais parecidas com o cérebro e amigáveis ao hardware que podem sustentar a próxima geração de sistemas de IA eficientes e explicáveis.
Citação: O’Shea, R., Rajendran, B. Closed-form feedback-free learning with forward projection. Nat Commun 17, 2414 (2026). https://doi.org/10.1038/s41467-026-69161-1
Palavras-chave: aprendizado sem retroalimentação, redes neurais, treinamento few-shot, IA biomédica, aprendizado profundo explicável