Clear Sky Science · pt
Mecanismos computacionais por neurônio único do codificação visual de objetos no lobo temporal humano
Como o cérebro sabe o que estamos olhando
Cada vez que você lança um olhar numa rua cheia, seu cérebro diz instantaneamente quais formas são pessoas, quais são carros e quais são placas, mesmo que estejam parcialmente ocultas ou com iluminação estranha. Este artigo faz uma pergunta aparentemente simples: como o cérebro humano transforma a torrente de detalhes visuais brutos que alcançam nossos olhos em ideias estáveis como “cachorro” ou “xícara”, que podemos reconhecer, lembrar e nomear?
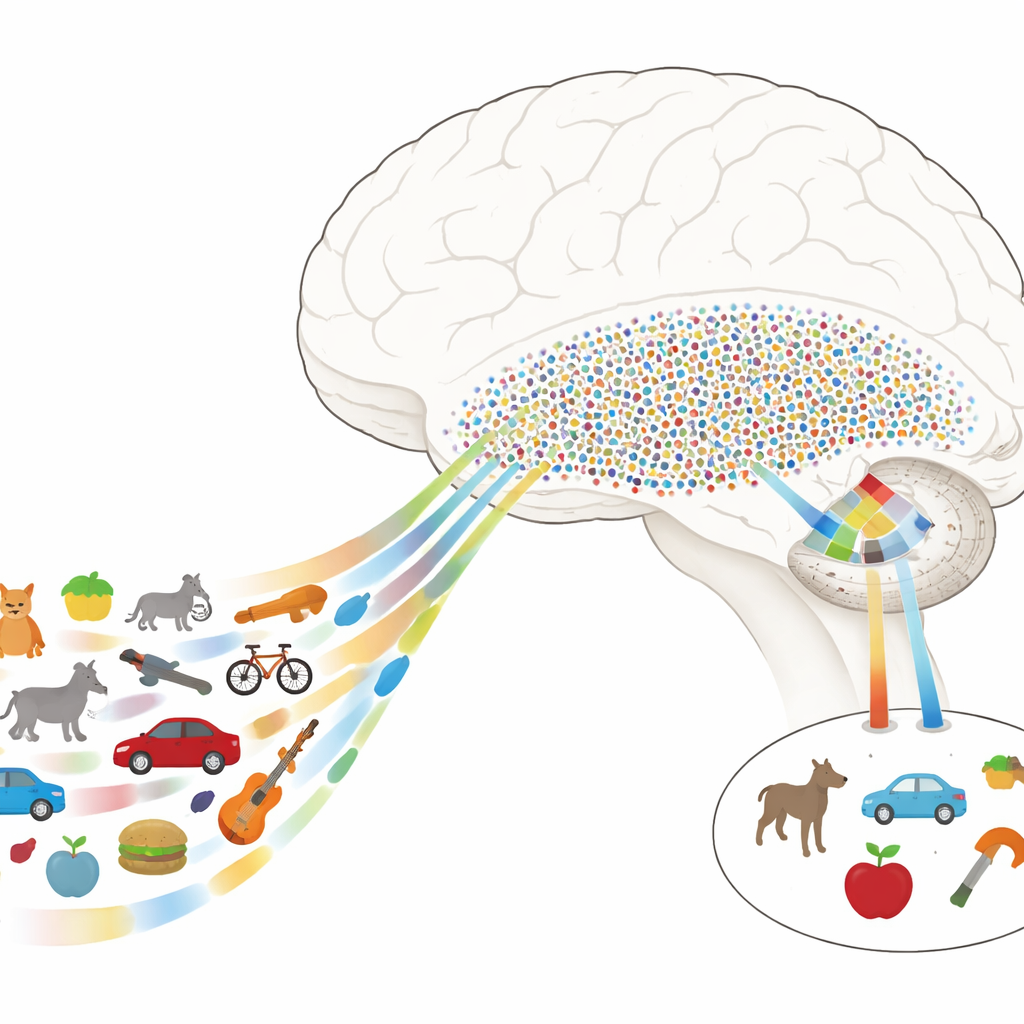
De imagens detalhadas a coisas com significado
Os cientistas sabem que o reconhecimento de objetos depende fortemente de uma cadeia de regiões na face inferior do cérebro chamada via visual ventral. Estágios iniciais lidam com características simples, como bordas e texturas, enquanto estágios posteriores se interessam mais por objetos inteiros e seus significados. Em humanos, um trecho-chave dessa via é o córtex temporal ventral (CTV), e logo a jusante está o lobo temporal medial (LTM), crucial para a memória. O mistério tem sido como o cérebro avança das descrições detalhadas e pictóricas do CTV para os códigos esparsos e conceituais do LTM, que permitem que poucos neurônios representem muitas vistas diferentes do mesmo objeto.
Um mapa neural do espaço dos objetos
Os autores registraram a atividade elétrica diretamente dos cérebros de pacientes com epilepsia que já tinham eletrodos implantados por razões médicas. Enquanto os pacientes realizavam uma tarefa simples, eles viam centenas de imagens naturais extraídas de muitas categorias — animais, ferramentas, alimentos, veículos, plantas e mais. No CTV, os pesquisadores descobriram que as respostas podiam ser descritas como combinações de algumas direções de características-chave, ou “eixos”, como o quanto algo parece natural versus manufaturado, ou o quanto é animado versus inanimado. Ao combinar matematicamente esses eixos, construíram um “espaço de características neural” no qual cada imagem ocupa uma posição, e objetos semelhantes se agrupam mesmo quando diferem em detalhes de baixo nível.
De grades densas de características a centros conceituais esparsos
Nesse espaço de características neural, o CTV age como uma grade densa: muitos sítios participam da representação de cada objeto, codificando diferenças visuais de alta resolução. Em contraste, neurônios registrados um a um no LTM se comportaram de maneira muito diferente. Em vez de rastrear características individuais, muitas dessas células respondiam fortemente apenas a objetos que caíssem em determinadas regiões do espaço de características do CTV. Cada neurônio assim tinha efetivamente um “campo receptivo” não no espaço físico, mas nesse mapa abstrato de propriedades do objeto. Objetos que caíam dentro da região preferida de um neurônio frequentemente compartilhavam traços perceptuais (por exemplo, formas arredondadas ou cores esverdeadas) e significados de nível mais alto (como ser um ser vivo ou uma ferramenta), levando esse neurônio a disparar de forma esparsa porém seletiva.
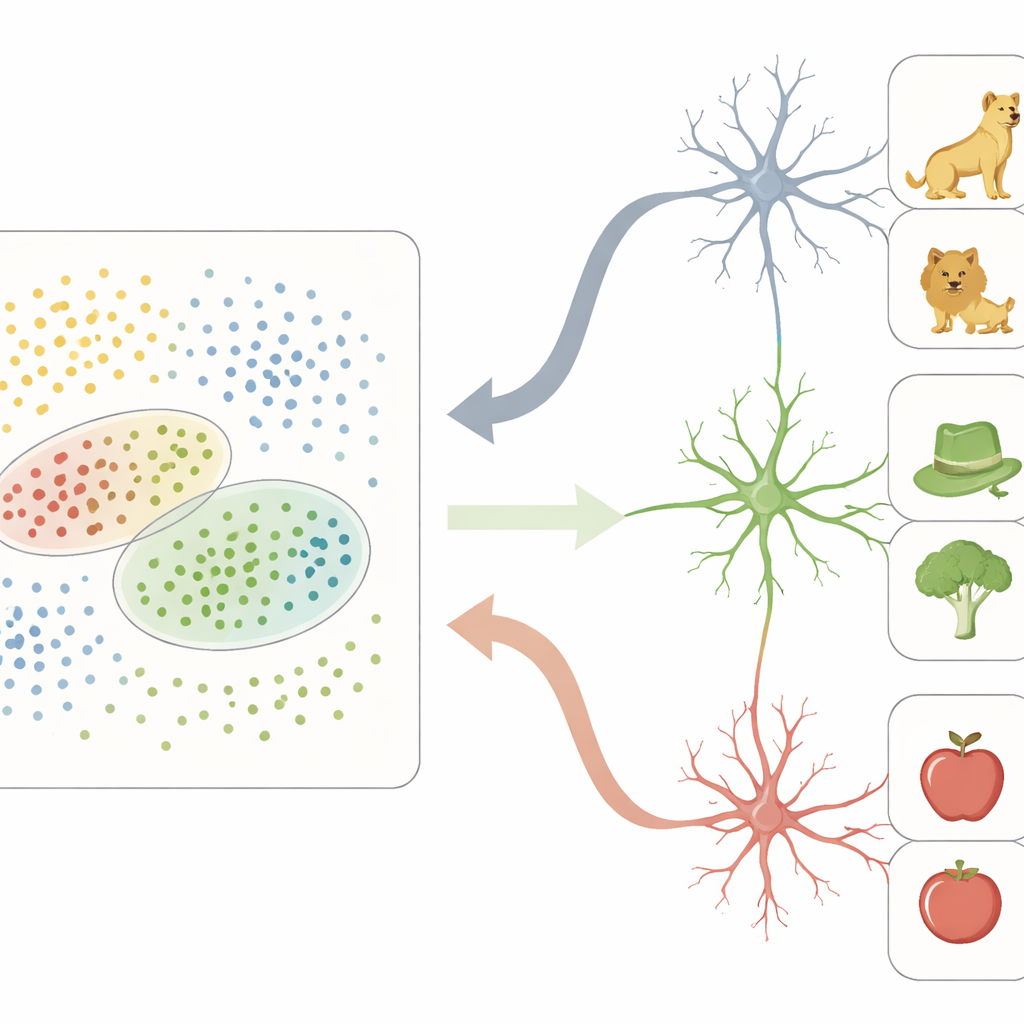
Conectando visão e memória
Para mostrar que isso não é apenas um truque matemático, a equipe examinou como essas áreas cerebrais interagem em tempo real. Eles descobriram que sítios do CTV que carregavam sinais fortes nos eixos de característica estavam especialmente sincronizados com sítios sensíveis a categorias no LTM, particularmente em certas ondas rítmicas cerebrais. A informação tendia a fluir do CTV para o LTM em frequências mais baixas associadas ao processamento feedforward, enquanto o feedback do LTM para o CTV ocorria em frequências um pouco mais altas. Crucialmente, quando um neurônio do LTM era sintonizado a uma região específica do espaço de características, seus disparos se alinhavam com ritmos rápidos no CTV, e esse acoplamento era mais forte para as próprias imagens que aquele neurônio codificava. Um segundo conjunto de experimentos usando uma coleção diferente de imagens confirmou que tanto o mapa de características do CTV quanto a sintonia por região no LTM eram estáveis entre diferentes conjuntos de estímulos.
Por que isso importa para ver e lembrar no dia a dia
Em conjunto, esses resultados sustentam uma narrativa computacional concreta: o CTV espalha objetos visuais ao longo de eixos de características significativas, formando uma paisagem rica e contínua, e o LTM coloca pequenos “ponteiros” seletivos sobre regiões dessa paisagem. Essa transformação converte um código pictórico detalhado e distribuído em um código conceitual esparso, mais fácil de armazenar, recuperar e combinar com outras memórias. Para um público não especializado, a conclusão é que reconhecer um cachorro numa noite chuvosa não é uma consulta simples, mas o resultado de um processo em camadas e cooperativo em que uma parte do cérebro constrói um mapa estruturado de aparências e outra parte aprende a marcar e ler regiões desse mapa como ideias distintas e duradouras.
Citação: Cao, R., Zhang, J., Zheng, J. et al. Computational single-neuron mechanisms of visual object coding in the human temporal lobe. Nat Commun 17, 2234 (2026). https://doi.org/10.1038/s41467-026-68954-8
Palavras-chave: reconhecimento de objetos, córtex temporal ventral, lobo temporal medial, codificação neural, memória visual