Clear Sky Science · pt
Diamante de DNA formula um modelo de constelação de letras compostas decomponível para armazenamento de dados em DNA
Por que dados do futuro podem viver no DNA
Nossos telefones, empresas e instrumentos científicos estão gerando dados muito mais rápido do que discos rígidos e fitas magnéticas conseguem acompanhar. O DNA — a mesma molécula que carrega informação genética em organismos vivos — também pode ser usado para armazenar arquivos digitais de forma incrivelmente compacta e duradoura. Este artigo apresenta uma nova maneira de empacotar ainda mais informação em fios de DNA sintético, mantendo a leitura prática e confiável, o que pode tornar o armazenamento em DNA mais barato e escalável.
Das quatro letras do DNA a misturas mais ricas
O armazenamento tradicional em DNA usa as quatro bases naturais — A, T, G e C — para representar bits digitais, de modo parecido com zeros e uns em um disco. Nesse esquema, cada posição em uma fita de DNA pode carregar no máximo dois bits de informação, porque está limitada a uma de quatro opções. Os autores ampliam uma ideia emergente: em vez de colocar uma única base em cada posição, eles criam misturas controladas de bases, chamadas letras compostas. Por exemplo, uma posição pode ser feita de uma mistura 50:50 de A e T, ou uma mistura 25:25:25:25 de todas as quatro bases. Quando muitas cópias de cada fita são sintetizadas, o sequenciamento dessas misturas revela as proporções das bases e, por sua vez, um símbolo digital que pode representar mais do que dois bits.
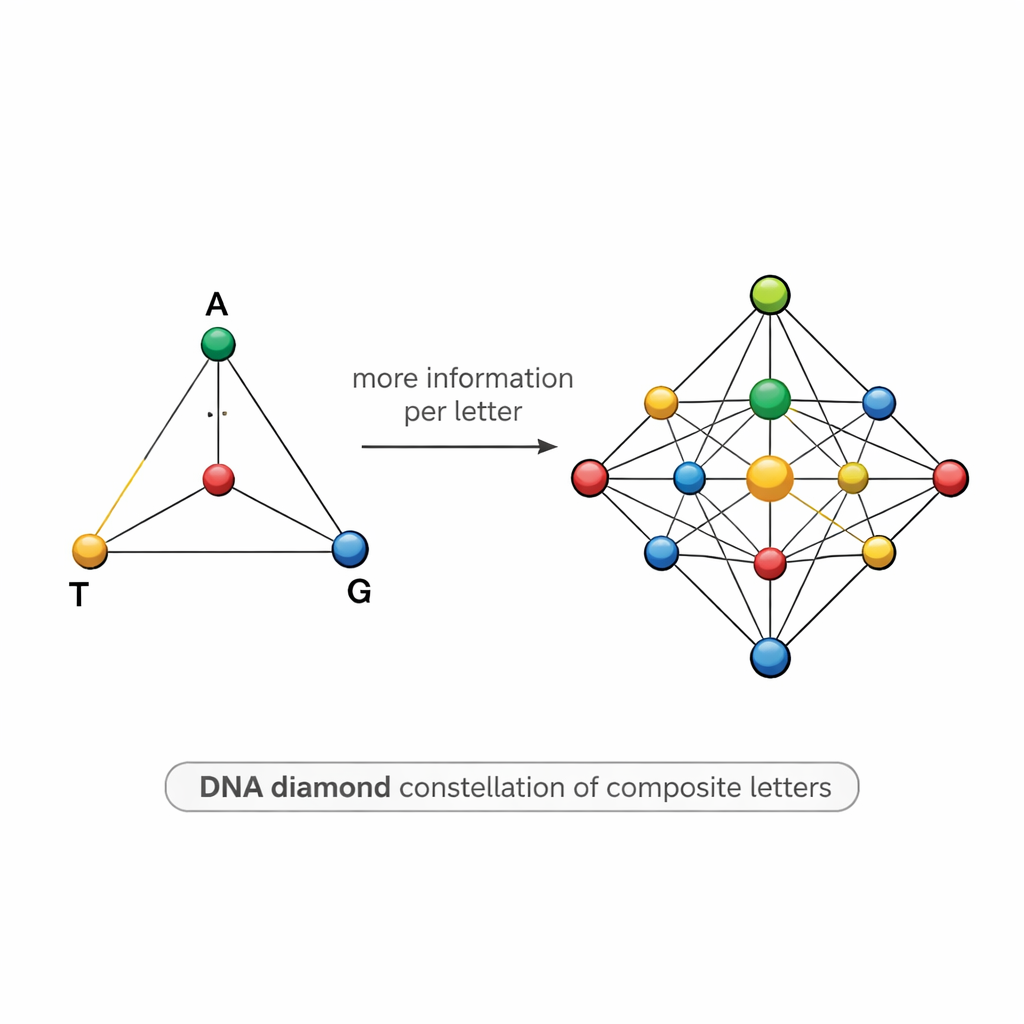
Um mapa em forma de diamante de símbolos de DNA
Projetar tais misturas é desafiador. Se dois símbolos forem muito parecidos — por exemplo, um com 50% A e 50% T e outro com 55% A e 45% T — o ruído do sequenciamento pode borrá‑los, causando erros e forçando os cientistas a sequenciar muito mais cópias do que gostariam. Para enfrentar isso, a equipe propõe um modelo estruturado chamado “diamante de DNA”: um conjunto de 15 letras compostas dispostas como pontos sobre um tetraedro cujos vértices são A, T, G e C. O conjunto inclui bases puras nos vértices, misturas iguais de duas bases ao longo das arestas, misturas de três bases em cada face e uma mistura perfeitamente uniforme das quatro bases no centro. Essa constelação cuidadosamente escolhida eleva teoricamente a informação por posição para cerca de 3,9 bits, mantendo os símbolos distintos o suficiente para serem diferenciados na prática.
Decodificação mais inteligente com entropia e indexação
Ler dados de volta do DNA significa inferir qual letra composta foi pretendida em cada posição a partir de medições ruidosas das frequências das bases. Os autores tomam emprestada uma estratégia das telecomunicações chamada particionamento de conjuntos. Primeiro, eles avaliam o quão “mista” uma posição parece ser, usando uma quantidade chamada entropia, que é baixa para bases puras e maior para misturas complexas. Isso atribui rapidamente cada posição a um dos quatro grupos: bases puras, misturas de duas bases, misturas de três bases ou a mistura das quatro bases. Então, dentro do grupo escolhido, um cálculo de verossimilhança mais preciso escolhe a letra mais provável. Essa abordagem em duas etapas reduz a confusão entre símbolos e diminui o tempo de computação em comparação com métodos anteriores. Para evitar que fitas sejam confundidas entre si, cada peça de DNA carrega sequências de índice protegidas contra erros em ambas as extremidades, e leituras de comprimento incorreto — frequentemente causadas por inserções ou deleções — são filtradas antes da decodificação.
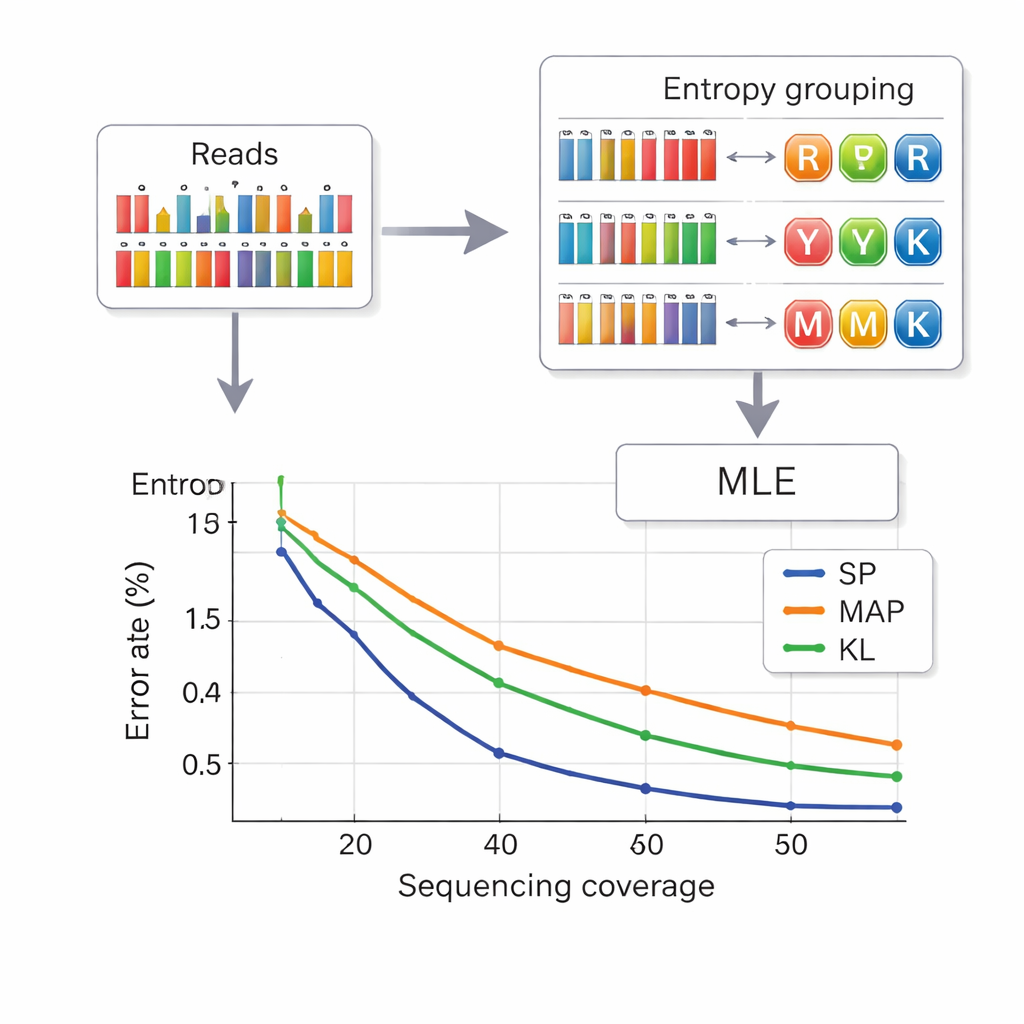
Empacotando mais dados com menos leituras
Os pesquisadores testaram seu sistema em pools de DNA pequenos e grandes, usando plataformas comerciais de síntese. Com um alfabeto composto de oito letras, eles atingiram uma densidade de carga útil de 2,5 bits por posição de DNA e conseguiram recuperar arquivos perfeitamente com uma média de 14 leituras de sequenciamento por fita — densidade melhor que esquemas anteriores de seis letras, exigindo menos leituras. Com o alfabeto completo de 15 letras do diamante de DNA, eles alcançaram 3,125 bits por posição para os dados principais e ainda recuperaram tudo sem erros com cobertura de 33 vezes. Simulações e experimentos também mostraram que seu método baseado em entropia performa quase tão bem quanto a abordagem de decodificação mais precisa, porém mais lenta, e claramente melhor do que técnicas antigas, especialmente em profundidades de sequenciamento mais baixas.
O que isso significa para memória futura
Para um leitor leigo, a mensagem principal é que os autores descobriram uma maneira de ensinar “novos truques” ao DNA sem inventar nova química: ao misturar inteligentemente as quatro bases existentes e decodificá‑las de forma mais inteligente, eles podem armazenar mais bits por molécula enquanto controlam custos. Seu alfabeto em forma de diamante, combinado com indexação robusta e correção de erros, mostra que armazenamento de dados de alta capacidade em DNA é possível com esforço de sequenciamento relativamente modesto. À medida que a síntese e o sequenciamento de DNA continuam a ficar mais baratos, esses designs podem ajudar a transformar o DNA de uma curiosidade de laboratório em um meio realista para arquivar as memórias digitais do mundo.
Citação: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
Palavras-chave: armazenamento de dados em DNA, letras compostas, densidade de informação, correção de erros, arquivamento digital