Clear Sky Science · pt
Banco de Dados de Nanopartículas Lipídicas voltado para modelagem estrutura-função e desenho orientado por dados para entrega de ácidos nucleicos
Por que bolhas minúsculas de gordura importam para os medicamentos do futuro
Nanopartículas lipídicas são bolhas microscópicas à base de gordura que transportam com segurança instruções genéticas — como vacinas de mRNA — para dentro das nossas células. Elas foram fundamentais para as vacinas contra a COVID-19, mas os pesquisadores ainda não compreendem totalmente como sua composição química detalhada controla sua eficácia. Este artigo descreve um novo recurso online, o Banco de Dados de Nanopartículas Lipídicas (LNPDB), criado para reunir dados dispersos em um único lugar, permitindo que cientistas projetem de maneira sistemática medicamentos genéticos melhores e mais seguros.
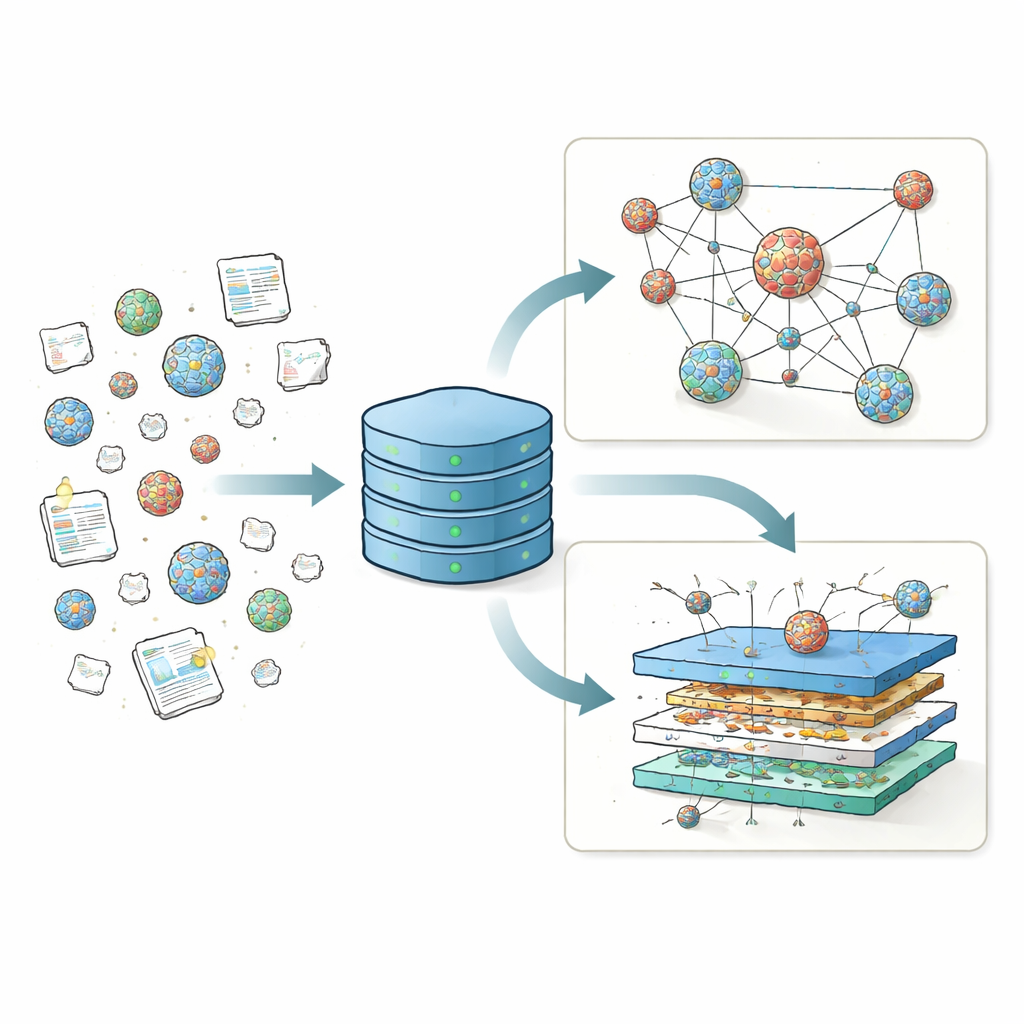
Reunindo resultados dispersos em um único lugar
Durante anos, diferentes laboratórios testaram milhares de receitas de nanopartículas lipídicas (LNP), variando o lipídio carregado principal, lipídios auxiliares, colesterol e lipídios de revestimento protetor para ver quais combinações entregam material genético com mais eficiência. Mas esses resultados foram reportados em muitos formatos ao longo de dezenas de artigos, dificultando a comparação entre estudos ou a identificação de tendências em larga escala. Ao contrário da ciência das proteínas, que conta com um repositório central — o Protein Data Bank — que impulsionou ferramentas como o AlphaFold, o campo de LNP não tinha um repositório unificado para seus dados de estrutura e desempenho. O LNPDB preenche essa lacuna ao coletar informações detalhadas de 19.528 formulações de LNP extraídas de 42 estudos e de um fornecedor comercial, e ao padronizar como os ingredientes, condições de teste e resultados de cada partícula são codificados.
O que há dentro do novo banco de dados
Cada entrada de LNP no LNPDB é descrita ao longo de três eixos principais: composição, experimento e simulação. Os campos de composição registram quais lipídios foram usados, quantos átomos de nitrogênio o lipídio carregado principal contém e as razões de mistura exatas entre os quatro componentes centrais: lipídio ionizável, lipídio auxiliar, colesterol e um lipídio com polietilenoglicol (PEG). Os campos experimentais capturam que tipo de carga genética foi entregue — na maioria das vezes mRNA codificando uma proteína repórter — onde foi direcionada (por exemplo, células em placa, fígado, pulmão ou músculo), como as partículas foram preparadas e como o sucesso foi medido. Finalmente, os campos de simulação fornecem arquivos prontos para uso que descrevem o comportamento físico de cada molécula lipídica com detalhes suficientes para executar simulações computacionais em nível atômico de membranas lipídicas. Juntos, esses descritores padronizados transformam um mosaico de triagens individuais em um panorama coerente que pode ser pesquisado, filtrado e ampliado pela comunidade.
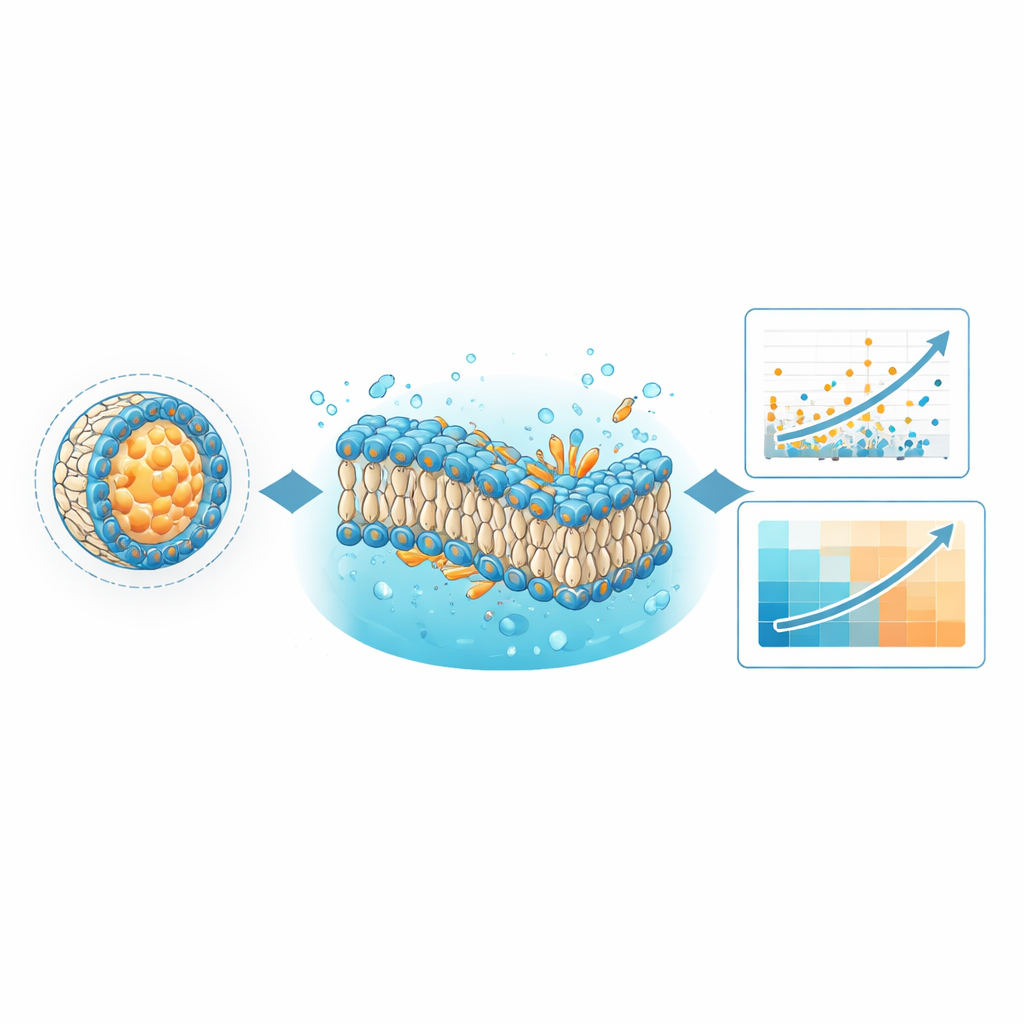
Ensinando computadores a identificar receitas de entrega melhores
Um uso imediato do LNPDB é melhorar modelos de aprendizado de máquina que preveem quais formulações irão entregar material genético com maior eficiência. Os autores re-treinaram seu modelo de aprendizado profundo existente, chamado LiON, com o conjunto de dados ampliado do LNPDB, mais que dobrando o número de exemplos que o modelo havia visto anteriormente. O LiON aprende padrões que conectam as estruturas químicas dos lipídios ionizáveis, a mistura de componentes auxiliares e o contexto de teste ao desempenho de cada formulação. Com os dados mais ricos, as previsões do LiON corresponderam melhor aos resultados experimentais na maioria dos conjuntos de teste e superaram um modelo concorrente chamado AGILE em vários conjuntos de dados independentes. Isso sugere que um conjunto de treinamento amplo, diversificado e em crescimento contínuo é fundamental para construir ferramentas de desenho de propósito geral para futuros medicamentos em LNP.
Observando membranas modelo para descobrir regras ocultas
O banco de dados também foi projetado para um tipo de cálculo muito diferente: simulações de dinâmica molecular baseadas em física. Usando os arquivos de simulação incluídos no LNPDB, a equipe construiu membranas simplificadas representando formulações selecionadas de LNP e observou seu comportamento ao longo de microssegundos de tempo simulado. Eles fizeram duas perguntas: as bicamadas lipídicas modeladas permanecem intactas e qual forma geral os lipídios-chave adotam dentro da membrana? As simulações revelaram que formulações cujas membranas se mantiveram estáveis eram mais propensas a ter sucesso experimentalmente. Também quantificaram uma característica chamada “parâmetro crítico de empacotamento”, que reflete se um lipídio tem formato mais cilíndrico, cônico ou cônico invertido na membrana. Em várias bibliotecas testadas, lipídios cujas formas favoreciam curvatura negativa — considerada útil para ajudar as partículas a fundir-se e perturbar membranas endossômicas — mostraram maior eficiência de entrega, às vezes correlacionando com o desempenho melhor do que o próprio modelo de aprendizado profundo.
Uma nova base para uma nanomedicina mais inteligente
Para um não especialista, a mensagem central é que este trabalho constrói um “mapa” compartilhado e em crescimento de como os ingredientes e a estrutura das pequenas bolhas de gordura se relacionam com sua capacidade de entregar terapias genéticas. Ao reunir dezenas de milhares de experimentos passados, possibilitar modelos de previsão poderosos e fornecer ferramentas para simular como as partículas se comportam no nível molecular, o LNPDB estabelece a base para um desenho mais racional em vez de tentativa e erro. Com o tempo, esse tipo de abordagem orientada por dados pode acelerar a criação de vacinas mais eficazes, tratamentos de edição genômica e outras terapias baseadas em ácidos nucleicos, além de ajudar os pesquisadores a entender por que certas receitas de nanopartículas funcionam — e outras não.
Citação: Collins, E., Ji, J., Kim, SG. et al. Lipid Nanoparticle Database towards structure-function modeling and data-driven design for nucleic acid delivery. Nat Commun 17, 2464 (2026). https://doi.org/10.1038/s41467-026-68818-1
Palavras-chave: nanopartículas lipídicas, entrega de mRNA, nanomedicina, aprendizado de máquina, dinâmica molecular